







Lab 1 Xv6 and Unix utilities
Boot xv6 (easy)
实验目的
切换到 xv6-labs-2020 代码的 util 分支,并利用 QEMU 模拟器启动 xv6 系统。
实验步骤
使用下面的命令克隆 xv6-labs-2020 代码到本地。
git clone git://g.csail.mit.edu/xv6-labs-2020
使用下面的命令进入 xv6-labs-2020 代码目录。
cd xv6-labs-2020
使用下面的命令切换到 util 分支。
git checkout util
xv6-labs-2020 代码库与配套教材的 xv6-riscv 略有不同,它主要添加一些文件。如果你好奇,使用下面的命令查看 git 日志。如果不感兴趣可以忽略此步骤。
git log
接下来使用下面的命令编译并运行 xv6 系统。
make qemu
xv6 通过 QEMU 模拟器启动后,启动 shell 进程,最后你会看到下面的输出,说明你已经成功编译并运行 xv6 系统。
xv6 kernel is booting
hart 2 starting
hart 1 starting
init: starting sh
$
如果你输入 ls 命令,即创建了一个子进程 ls ,就会看到 xv6 目录下的文件,下面是输出结果。
$ ls
. 1 1 1024
.. 1 1 1024
README 2 2 2059
xargstest.sh 2 3 93
cat 2 4 24256
echo 2 5 23080
forktest 2 6 13272
grep 2 7 27560
init 2 8 23816
kill 2 9 23024
ln 2 10 22880
ls 2 11 26448
mkdir 2 12 23176
rm 2 13 23160
sh 2 14 41976
stressfs 2 15 24016
usertests 2 16 148456
grind 2 17 38144
wc 2 18 25344
zombie 2 19 22408
console 3 20 0
你所看到的这些输出是 mkfs 包含在初始文件系统中的文件,大多数是可以运行的程序。你刚刚就运行了其中的一个:ls。
在 xv6 中按 Ctrl + p 会显示当前系统的进程信息。
1 sleep init
2 sleep sh
在 xv6 中按 Ctrl + a ,然后按 x 即可退出 xv6 系统。
sleep (easy)
实验目的
为 xv6 系统实现 UNIX 的 sleep 程序。你的 sleep 程序应该使当前进程暂停相应的时钟周期数,时钟周期数由用户指定。例如执行 sleep 100 ,则当前进程暂停,等待 100 个时钟周期后才继续执行。
实验要求及提示
- 如果系统没有安装
vim的请先使用命令sudo apt install vim安装vim编辑器。 - 在开始实现程序前,阅读配套教材的第一章,其内容与实验内容息息相关。
- 实现的程序应该命名为
sleep.c并最后放入user目录下。 - 可以查看
user目录下的其他程序(如echo.c、grep.c和rm.c),以它们为参考,了解如何获取和传递给程序相应的命令行参数。 - 如果用户传入参数有误,即没有传入参数或者传入多个参数,程序应该能打印出错误信息。
- C 语言中的
atoi函数可以将字符串转换为整数类型,在 xv6 中也已经定义了相同功能的函数。可以参考user/ulib.c或者参考机械工业出版社的《C程序设计语言(第2版·新版)》附录B.5。 - 使用系统调用
sleep。 - 确保
main函数调用exit()以退出程序。 - 将你的
sleep程序添加到Makefile的UPROGS中。只有这步完成后,make qemu才能编译你写的程序。 - 完成上述步骤后,运行
make qemu编译运行xv6,输入sleep 10进行测试,如果shell隔了一段时间后才出现命令提示符,则证明你的结果是正确的,可以退出xv6运行./grade-lab-util sleep或者make GRADEFLAGS=sleep grade进行单元测试。
实验思路
- 参考
user目录下的其他程序,先把头文件引入,即kernel/types.h声明类型的头文件和user/user.h声明系统调用函数和ulib.c中函数的头文件。 - 编写
main(int argc,char* argv[])函数。其中,参数argc是命令行总参数的个数,参数argv[]是argc个参数,其中第 0 个参数是程序的全名,其他的参数是命令行后面跟的用户输入的参数。 - 首先,编写判断用户输入的参数是否正确的代码部分。只要判断命令行参数不等于 2 个,就可以知道用户输入的参数有误,就可以打印错误信息。但我们要如何让命令行打印出错误信息呢?我们可以参考
user/echo.c,其中可以看到程序使用了write()函数。write(int fd, char *buf, int n)函数是一个系统调用,参数fd是文件描述符,0 表示标准输入,1 表示标准输出,2 表示标准错误。参数buf是程序中存放写的数据的字符数组。参数 n 是要传输的字节数,调用user/ulib.c的strlen()函数就可以获取字符串长度字节数。通过调用这个函数,就能解决输出错误信息的问题啦。认真看了提示给出的所有文件代码你可能会发现,像在user/grep.c打印信息调用的是fprintf()函数,当然,在这里使用也没有问题,毕竟fprintf()函数最后还是通过系统调用write()。最后系统调用exit(1)函数使程序退出。按照惯例,返回值 0 表示一切正常,而非 0 则表示异常。 - 接下来获取命令行给出的时钟周期,由于命令行接收的是字符串类型,所以先使用
atoi()函数把字符串型参数转换为整型。 - 调用系统调用
sleep函数,传入整型参数,使计算机程序(进程、任务或线程)进入休眠。 - 最后调用系统调用
exit(0)使程序正常退出。 - 在
Makefile文件中添加配置,照猫画虎,在UPROGS项中最后一行添加$U/_sleep\,最后这项配置如下。
UPROGS=\
$U/_cat\
$U/_echo\
$U/_forktest\
$U/_grep\
$U/_init\
$U/_kill\
$U/_ln\
$U/_ls\
$U/_mkdir\
$U/_rm\
$U/_sh\
$U/_stressfs\
$U/_usertests\
$U/_grind\
$U/_wc\
$U/_zombie\
$U/_sleep\
实验代码
// Lab Xv6 and Unix utilities
// sleep.c
// 引入声明类型的头文件
#include "kernel/types.h"
// 引入声明系统调用和 user/ulib.c 中其他函数的头文件
#include "user/user.h"
// int main(int argc,char* argv[])
// argc 是命令行总的参数个数
// argv[] 是 argc 个参数,其中第 0 个参数是程序的全名,以后的参数是命令行后面跟的用户输入的参数
int
main(int argc, char *argv[])
{
// 如果命令行参数不等于2个,则打印错误信息
if (argc != 2)
{
// 系统调用 write(int fd, char *buf, int n) 函数输出错误信息
// 参数 fd 是文件描述符,0 表示标准输入,1 表示标准输出,2 表示标准错误
// 参数 buf 是程序中存放写的数据的字符数组
// 参数 n 是要传输的字节数
// 所以这里调用 user/ulib.c 的 strlen() 函数获取字符串长度字节数
write(2, "Usage: sleep time\n", strlen("Usage: sleep time\n"));
// 当然这里也可以使用 user/printf.c 中的 fprintf(int fd, const char *fmt, ...) 函数进行格式化输出
// fprintf(2, "Usage: sleep time\n");
// 退出程序
exit(1);
}
// 把字符串型参数转换为整型
int time = atoi(argv[1]);
// 调用系统调用 sleep 函数,传入整型参数
sleep(time);
// 正常退出程序
exit(0);
}
实验结果
在 xv6 中输入命令后一切符合预期。
$ sleep 10
$ sleep 1 1
Usage: sleep time
$ sleep
Usage: sleep time
退出 xv6 运行单元测试。
./grade-lab-util sleep
提示:如果运行命令 ./grade-lab-util sleep 报 /usr/bin/env: ‘python’: No such file or directory 错误,请使用命令 vim grade-lab-util,把第一行 python 改为 python3。如果系统没装 python3,请先安装 sudo apt-get install python3 。
通过测试样例。
make: 'kernel/kernel' is up to date.
== Test sleep, no arguments == sleep, no arguments: OK (0.9s)
== Test sleep, returns == sleep, returns: OK (1.4s)
== Test sleep, makes syscall == sleep, makes syscall: OK (0.9s)
pingpong (easy)
实验要求
使用 UNIX 系统调用编写一个程序 pingpong ,在一对管道上实现两个进程之间的通信。父进程应该通过第一个管道给子进程发送一个信息 “ping”,子进程接收父进程的信息后打印 "<pid>: received ping" ,其中是其进程 ID 。然后子进程通过另一个管道发送一个信息 “pong” 给父进程,父进程接收子进程的信息然后打印 "<pid>: received pong" ,然后退出。
实验提示
- 使用
pipe创建管道。 - 使用
fork创建一个子进程。 - 使用
read从管道读取信息,使用write将信息写入管道。 - 使用
getpid获取当前进程 ID。 - 将程序添加到
Makefile中的UPROGS。 - xv6 上的用户程序具有有限的库函数可供它们使用。你可以在
user/user.h中查看,除系统调用外其他函数代码位于user/ulib.c、user/printf.c、和user/umalloc.c中。
实验思路
- 首先引入头文件
kernel/types.h和user/user.h。 - 开始编写
main函数,定义两个文件描述符ptoc_fd和ctop_fd数组,创建两个管道,pipe(ptoc_fd)和pipe(ctop_fd),一个用于父进程传递信息给子进程,另一个用于子进程传递信息给父进程。pipe(pipefd)系统调用会创建管道,并把读取和写入的文件描述符返回到pipefd中。pipefd[0]指管道的读取端,pipefd[1]指管道的写入端。可以使用命令man pipe查看手册获取更多内容。 - 创建缓冲区字符数组,存放传递的信息。
- 使用
fork创建子进程,子进程的fork返回值为 0 ,父进程的fork返回子进程的进程 ID,所以通过 if 语句就能让父进程和子进程执行不同的代码块。 - 编写父进程执行的代码块。使用
write()系统调用传入三个参数,把字符串"ping"写入管道一,第一个参数为管道的写入端文件描述符,第二个参数为写入的字符串,第三个参数为写入的字符串长度。然后调用wait()函数等待子进程完成操作后退出,传入参数 0 或者 NULL ,不过后者需要引入头文件stddef.h。使用read()系统调用传入三个参数,接收从管道二传来的信息,第一个参数为管道的读取端文件描述符,第二个参数为缓冲区字符数组,第三个参数为读取的字符串长度。最后调用printf()函数打印当前进程 ID 以及接收到的信息,即缓冲区的内容。 - 编写子进程执行的代码块。使用
read()系统调用传入三个参数,接收从管道一传来的信息,第一个参数为管道的读取端文件描述符,第二个参数为缓冲区字符数组,第三个参数为读取的字符串长度。然后调用printf()函数打印当前进程 ID 以及接收到的信息,即缓冲区的内容。最后使用write()系统调用传入三个参数,把字符串"pong"写入管道二,第一个参数为管道的写入端文件描述符,第二个参数为写入的字符串,第三个参数为写入的字符串长度。 - 最后调用
exit()系统调用使程序正常退出。
实验代码
// Lab Xv6 and Unix utilities
// pingpong.c
#include "kernel/types.h"
#include "user/user.h"
#include "stddef.h"
int
main(int argc, char *argv[])
{
int ptoc_fd[2], ctop_fd[2];
pipe(ptoc_fd);
pipe(ctop_fd);
char buf[8];
if (fork() == 0) {
// child process
read(ptoc_fd[0], buf, 4);
printf("%d: received %s\n", getpid(), buf);
write(ctop_fd[1], "pong", strlen("pong"));
}
else {
// parent process
write(ptoc_fd[1], "ping", strlen("ping"));
wait(NULL);
read(ctop_fd[0], buf, 4);
printf("%d: received %s\n", getpid(), buf);
}
exit(0);
}
实验结果
在 Makefile 文件中, UPROGS 项追加一行 $U/_pingpong\ 。编译并运行 xv6 进行测试。
$ make qemu
...
init: starting sh
$ pingpong
4: received ping
3: received pong
$
退出 xv6 ,运行单元测试检查结果是否正确。
./grade-lab-util pingpong
通过测试样例。
make: 'kernel/kernel' is up to date.
== Test pingpong == pingpong: OK (1.1s)
primes (moderate)/(hard)
实验要求
使用管道将 2 至 35 中的素数筛选出来,这个想法归功于 Unix 管道的发明者 Doug McIlroy 。链接中间的图片和周围的文字解释了如何操作。最后的解决方案应该放在 user/primes.c 文件中。
你的目标是使用 pipe 和 fork 来创建管道。第一个进程将数字 2 到 35 送入管道中。对于每个质数,你要安排创建一个进程,从其左邻通过管道读取,并在另一条管道上写给右邻。由于 xv6 的文件描述符和进程数量有限,第一个进程可以停止在 35 。
实验提示
- 请关闭进程不需要的文件描述符,否则程序将在第一个进程到达
35之前耗尽 xv6 资源。 - 一旦第一个进程到达
35,它应该等到整个管道终止,包括所有的子进程,孙子进程等。因此,主进程只有在打印完所有输出后才能退出,即所有其他进程已退出后主进程才能退出。 - 当管道的写入端关闭时,
read函数返回0。 - 最简单的方式是直接将
32位(4字节)的整型写到管道中,而不是使用格式化的 ASCII I/O 。 - 你应该根据需要创建进程。
- 将程序添加到
Makefile中的UPROGS。
实验思路
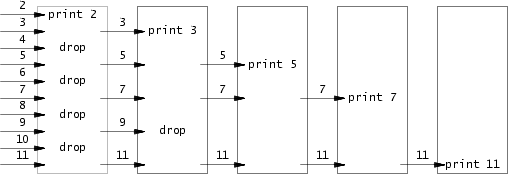
- 首先打开提示给出的链接,阅读并观察上面给出的图。由图可见,首先将数字全部输入到最左边的管道,然后第一个进程打印出输入管道的第一个数
2,并将管道中所有2的倍数的数剔除。接着把剔除后的所有数字输入到右边的管道,然后第二个进程打印出从第一个进程中传入管道的第一个数3,并将管道中所有3的倍数的数剔除。接着重复以上过程,最终打印出来的数都为素数。 - 参考 xv6 手册第一章的 Pipes 部分,其中的例子演示了运行程序
wc,由此受到启发,可以使用文件描述符重定向技巧,避免 xv6 的文件描述符限制所带来的影响。所以,学习示例代码,先写一个重定向函数mapping,虽然叫重定向,但感觉还是称为映射比较好,原理就是关闭当前进程的某个文件描述符,把管道的读端或者写端的描述符通过dup函数复制给刚刚关闭的文件描述符,再把管道描述符关闭,节约了资源。 - 编写
main函数,首先创建文件描述符和创建一个管道,再创建一个子进程,子进程把管道的写端口描述符映射到原来的描述符标准输出1上。循环通过write系统调用把2到35写入管道。父进程等待子进程把数据写入完毕后,父进程把管道的读端口描述符映射到原来的描述符标准输入0上。在编写一个primes函数,调用此函数实现递归筛选的过程。 - 编写
primes函数。定义两个整型变量,存放从管道获取的数,定义管道描述符数组。从管道中读取数据,第一个数一定是素数,直接打印出来,然后创建另一个管道和子进程,子进程通过管道描述符映射,关闭不必要的文件描述符节约资源。再循环读取原管道中的数据,如果该数与原管道的第一个取模后不为0,则再次写入刚刚创建的管道。父进程等待此子进程执行完毕,再次调用重定向函数关闭不必要的文件描述符,再递归调用primes函数重复以上筛选过程,即可将管道中所有素数打印出来。
实验代码
// Lab Xv6 and Unix utilities
// primes.c
#include "kernel/types.h"
#include "user/user.h"
#include "stddef.h"
// 文件描述符重定向(讲成映射比较好)
void
mapping(int n, int pd[])
{
// 关闭文件描述符 n
close(n);
// 将管道的 读或写 端口复制到描述符 n 上
// 即产生一个 n 到 pd[n] 的映射
dup(pd[n]);
// 关闭管道中的描述符
close(pd[0]);
close(pd[1]);
}
// 求素数
void
primes()
{
// 定义变量获取管道中的数
int previous, next;
// 定义管道描述符数组
int fd[2];
// 从管道读取数据
if (read(0, &previous, sizeof(int)))
{
// 第一个一定是素数,直接打印
printf("prime %d\n", previous);
// 创建管道
pipe(fd);
// 创建子进程
if (fork() == 0)
{
// 子进程
// 子进程将管道的写端口映射到描述符 1 上
mapping(1, fd);
// 循环读取管道中的数据
while (read(0, &next, sizeof(int)))
{
// 如果该数不是管道中第一个数的倍数
if (next % previous != 0)
{
// 写入管道
write(1, &next, sizeof(int));
}
}
}
else
{
// 父进程
// 等待子进程把数据全部写入管道
wait(NULL);
// 父进程将管道的读端口映射到描述符 0 上
mapping(0, fd);
// 递归执行此过程
primes();
}
}
}
int
main(int argc, char *argv[])
{
// 定义描述符
int fd[2];
// 创建管道
pipe(fd);
// 创建进程
if (fork() == 0)
{
// 子进程
// 子进程将管道的写端口映射到描述符 1 上
mapping(1, fd);
// 循环获取 2 至 35
for (int i = 2; i < 36; i++)
{
// 将其写入管道
write(1, &i, sizeof(int));
}
}
else
{
// 父进程
// 等待子进程把数据全部写入管道
wait(NULL);
// 父进程将管道的读端口映射到描述符 0 上
mapping(0, fd);
// 调用 primes() 函数求素数
primes();
}
// 正常退出
exit(0);
}
实验结果
在 Makefile 文件中, UPROGS 项追加一行 $U/_primes\ 。编译并运行 xv6 进行测试。
$ make qemu
...
init: starting sh
$ primes
prime 2
prime 3
prime 5
prime 7
prime 11
prime 13
prime 17
prime 19
prime 23
prime 29
prime 31
$
退出 xv6 ,运行单元测试检查结果是否正确。
./grade-lab-util primes
通过测试样例。
make: 'kernel/kernel' is up to date.
== Test primes == primes: OK (1.4s)
find (moderate)
实验要求
编写一个简单的 UNIX find 程序,在目录树中查找包含特定名称的所有文件。你的解决方案应放在 user/find.c 。
实验提示
- 查看
user/ls.c了解如何读目录。 - 使用递归查找子目录下的文件。
- 不要递归
"."和"..."。 - 文件系统的变化在
qemu的运行中持续存在。使用make clean然后再make qemu让一个干净的文件系统运行。 - 你需要使用 C 字符串。可以参考机械工业出版社的《C程序设计语言(第2版·新版)》第 5.5 节。
- 请注意,比较字符串不能像在
Python中使用==一样。请使用strcmp()函数。 - 支持使用正则表达式匹配字符串,参照
user/grep.c当中的正则匹配器。 - 将程序添加到
Makefile的UPROGS中。
实验思路
- 根据提示,我们可以先阅读
user/ls.c源码查看如何读目录。 - 在
user/ls.c中,有一个名为fmtname()的函数,其目的是将路径格式化为文件名,也就是把名字变成前面没有左斜杠/,仅仅保存文件名。 - 在
user/ls.c中,有一个名为ls()的函数,首先函数里面声明了需要用到的变量,包括文件名缓冲区、文件描述符、文件相关的结构体等等。其次使用open()函数进入路径,判断此路径是文件还是文件名。 - 如果是文件类型,则打印出文件信息,包括文件名,类型,Inode号,文件大小(单位为bytes)。如果是目录类型,则获取目录下的文件名,并依次输出文件信息。如果该文件还为路径,则循环遍历输出该路径下的文件信息。
- 可以把
user/ls.c中的大部分代码重复利用,只要修改传入参数的数量,以及文件名之间的比较部分,就能完成此次实验。 - 下面的参考实验代码只使用了
find()函数,与ls()函数一样,首先声明了文件名缓冲区、文件描述符和文件相关的结构体。其次试探是否能进入给定路径,然后调用系统调用获得一个已存在文件的模式,并判断其类型。如果该路径不是目录类型就报错。接着把绝对路径进行拷贝,循环获取路径下的文件名,与要查找的文件名进行比较,如果类型为文件且名称与要查找的文件名相同则输出路径,如果是目录类型则递归调用find()函数继续查找。
实验代码
// Lab Xv6 and Unix utilities
// find.c
#include "kernel/types.h"
#include "user/user.h"
#include "kernel/stat.h"
#include "kernel/fs.h"
// find 函数
void
find(char *dir, char *file)
{
// 声明 文件名缓冲区 和 指针
char buf[512], *p;
// 声明文件描述符 fd
int fd;
// 声明与文件相关的结构体
struct dirent de;
struct stat st;
// open() 函数打开路径,返回一个文件描述符,如果错误返回 -1
if ((fd = open(dir, 0)) < 0)
{
// 报错,提示无法打开此路径
fprintf(2, "find: cannot open %s\n", dir);
return;
}
// int fstat(int fd, struct stat *);
// 系统调用 fstat 与 stat 类似,但它以文件描述符作为参数
// int stat(char *, struct stat *);
// stat 系统调用,可以获得一个已存在文件的模式,并将此模式赋值给它的副本
// stat 以文件名作为参数,返回文件的 i 结点中的所有信息
// 如果出错,则返回 -1
if (fstat(fd, &st) < 0)
{
// 出错则报错
fprintf(2, "find: cannot stat %s\n", dir);
// 关闭文件描述符 fd
close(fd);
return;
}
// 如果不是目录类型
if (st.type != T_DIR)
{
// 报类型不是目录错误
fprintf(2, "find: %s is not a directory\n", dir);
// 关闭文件描述符 fd
close(fd);
return;
}
// 如果路径过长放不入缓冲区,则报错提示
if(strlen(dir) + 1 + DIRSIZ + 1 > sizeof buf)
{
fprintf(2, "find: directory too long\n");
// 关闭文件描述符 fd
close(fd);
return;
}
// 将 dir 指向的字符串即绝对路径复制到 buf
strcpy(buf, dir);
// buf 是一个绝对路径,p 是一个文件名,通过加 "/" 前缀拼接在 buf 的后面
p = buf + strlen(buf);
*p++ = '/';
// 读取 fd ,如果 read 返回字节数与 de 长度相等则循环
while (read(fd, &de, sizeof(de)) == sizeof(de))
{
if(de.inum == 0)
continue;
// strcmp(s, t);
// 根据 s 指向的字符串小于(s<t)、等于(s==t)或大于(s>t) t 指向的字符串的不同情况
// 分别返回负整数、0或正整数
// 不要递归 "." 和 "..."
if (!strcmp(de.name, ".") || !strcmp(de.name, ".."))
continue;
// memmove,把 de.name 信息复制 p,其中 de.name 代表文件名
memmove(p, de.name, DIRSIZ);
// 设置文件名结束符
p[DIRSIZ] = 0;
// int stat(char *, struct stat *);
// stat 系统调用,可以获得一个已存在文件的模式,并将此模式赋值给它的副本
// stat 以文件名作为参数,返回文件的 i 结点中的所有信息
// 如果出错,则返回 -1
if(stat(buf, &st) < 0)
{
// 出错则报错
fprintf(2, "find: cannot stat %s\n", buf);
continue;
}
// 如果是目录类型,递归查找
if (st.type == T_DIR)
{
find(buf, file);
}
// 如果是文件类型 并且 名称与要查找的文件名相同
else if (st.type == T_FILE && !strcmp(de.name, file))
{
// 打印缓冲区存放的路径
printf("%s\n", buf);
}
}
}
int
main(int argc, char *argv[])
{
// 如果参数个数不为 3 则报错
if (argc != 3)
{
// 输出提示
fprintf(2, "usage: find dirName fileName\n");
// 异常退出
exit(1);
}
// 调用 find 函数查找指定目录下的文件
find(argv[1], argv[2]);
// 正常退出
exit(0);
}
实验结果
在 Makefile 文件中, UPROGS 项追加一行 $U/_find\ 。编译并运行 xv6 进行测试。
$ make clean
...
$ make qemu
...
init: starting sh
$ echo > b
$ mkdir a
$ echo > a/b
$ find . b
./b
./a/b
$
退出 xv6 ,运行单元测试检查结果是否正确。
./grade-lab-util find
通过测试样例。
make: 'kernel/kernel' is up to date.
== Test find, in current directory == find, in current directory: OK (1.4s)
== Test find, recursive == find, recursive: OK (1.0s)
xargs (moderate)
实验要求
编写一个简单的 UNIX xargs 程序,从标准输入中读取行并为每一行运行一个命令,将该行作为命令的参数提供。你的解决方案应该放在 user/xargs.c 中。
实验提示
- 使用
fork()和exec()在每一行输入上调用命令。在parent中使用wait()等待child完成命令。 - 要读取单个输入行,请一次读取一个字符,直到出现换行符(
'\n')。 kernel/param.h声明了MAXARG,如果你需要声明一个argv数组,这可能很有用。- 将程序添加到
Makefile的UPROGS中。 - 文件系统的变化在
qemu的运行中持续存在。使用make clean然后再make qemu让一个干净的文件系统运行。
实验思路
- 根据提示,我们需要调用
fork()创建子进程,和调用exec()执行命令。我们知道要从标准输入中读取行并为每行运行一个命令,且将该行作为命令的参数。即把输入的字符放到命令后面,然后调用exec()。我们可以依次处理每行,根据空格符和换行符分割参数,调用子进程执行命令。 - 首先,我们定义一个字符数组,作为子进程的参数列表,其大小设置为
kernel/param.h中定义的MAXARG,用于存放子进程要执行的参数。而后,建立一个索引便于后面追加参数,并循环拷贝一份命令行参数,即拷贝xargs后面跟的参数。创建缓冲区,用于存放从管道读出的数据。 - 然后,循环读取管道中的数据,放入缓冲区,建立一个新的临时缓冲区存放追加的参数。把临时缓冲区追加到子进程参数列表后面。并循环获取缓冲区字符,当该字符不是换行符时,直接给临时缓冲区;否则创建一个子进程,把执行的命令和参数列表传入
exec()函数中,执行命令。当然,这里一定要注意,父进程一定得等待子进程执行完毕。
实验代码
// Lab Xv6 and Unix utilities
// xargs.c
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/param.h"
#define MAXN 1024
int
main(int argc, char *argv[])
{
// 如果参数个数小于 2
if (argc < 2) {
// 打印参数错误提示
fprintf(2, "usage: xargs command\n");
// 异常退出
exit(1);
}
// 存放子进程 exec 的参数
char * argvs[MAXARG];
// 索引
int index = 0;
// 略去 xargs ,用来保存命令行参数
for (int i = 1; i < argc; ++i) {
argvs[index++] = argv[i];
}
// 缓冲区存放从管道读出的数据
char buf[MAXN] = {"\0"};
int n;
// 0 代表的是管道的 0,也就是从管道循环读取数据
while((n = read(0, buf, MAXN)) > 0 ) {
// 临时缓冲区存放追加的参数
char temp[MAXN] = {"\0"};
// xargs 命令的参数后面再追加参数
argvs[index] = temp;
// 内循环获取追加的参数并创建子进程执行命令
for(int i = 0; i < strlen(buf); ++i) {
// 读取单个输入行,当遇到换行符时,创建子线程
if(buf[i] == '\n') {
// 创建子线程执行命令
if (fork() == 0) {
exec(argv[1], argvs);
}
// 等待子线程执行完毕
wait(0);
} else {
// 否则,读取管道的输出作为输入
temp[i] = buf[i];
}
}
}
// 正常退出
exit(0);
}
实验结果
在 Makefile 文件中, UPROGS 项追加一行 $U/_xargs\ 。编译并运行 xv6 进行测试。
$ make clean
...
$ make qemu
...
init: starting sh
$ echo hello too | xargs echo bye
bye hello too
退出 xv6 ,运行单元测试检查结果是否正确。
./grade-lab-util xargs
通过测试样例。
make: 'kernel/kernel' is up to date.
== Test xargs == xargs: OK (1.8s)
Lab 1 所有实验测试
退出 xv6 ,运行整个 Lab 1 测试,检查结果是否正确。
$ make grade
...
== Test sleep, no arguments ==
$ make qemu-gdb
sleep, no arguments: OK (2.4s)
== Test sleep, returns ==
$ make qemu-gdb
sleep, returns: OK (1.2s)
== Test sleep, makes syscall ==
$ make qemu-gdb
sleep, makes syscall: OK (0.8s)
== Test pingpong ==
$ make qemu-gdb
pingpong: OK (1.0s)
== Test primes ==
$ make qemu-gdb
primes: OK (1.3s)
== Test find, in current directory ==
$ make qemu-gdb
find, in current directory: OK (0.6s)
== Test find, recursive ==
$ make qemu-gdb
find, recursive: OK (3.0s)
== Test xargs ==
$ make qemu-gdb
xargs: OK (3.9s)
== Test time ==
time: OK
Score: 100/100

















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









