







了解到脑电需要对输入的信号进行预处理,特征提取,特征选择等,看了些网课,再了解一下EEG信号相关知识。
一、原始数据

文件为原始数据(Brain Products数据):
- eeg:存储数据
- vhdr:头文件信息 通道配置信息
- vmrk:marker信息
import os
os.chdir(#这里写具体导入文件的上级路径)
import mne
import numpy as np
#读取原始数据 mne区分是否为原始数据的方式是看数据的维度 二维的数据(连续数据)都是raw 分段过的数据用epoch的形式读
#不确定用什么函数 可以用mne.io.read之后tab
raw = mne.io.read_raw_brainvision('1.vhdr',preload=True)
raw.info #查看原始数据的信息
print(raw)
dir(raw)
sampling_rate = raw.info['sfreq'] #查看采样率的信息
n_time_samps = raw.n_times #采样点信息
time_secs = raw.times #每个采样点对应的时间信息 单位是s
ch_names = raw.ch_names #查看通道的名称
n_ch = len(ch_names) #通过len访问通道名称,获取一共有多少个通道
raw.plot()
raw.plot(n_channels = 64, duration = 5, scalings = 30e-6) #定义一次显示多少个通道 多长时间的数据 以及绘图的尺寸 一般60导左右的数据用30e-6
#由于数据中的原始通道到名称没法成功定位 所以修改通道名称信息
mapping = {'FP1':'Fp1', 'FPZ':'Fpz','FP2':'Fp2', 'FZ':'Fz',
'FCZ':'FCz', 'CZ':'Cz', 'CPZ':'CPz', 'PZ':'Pz',
'PO5':'PO5', 'POZ':'POz', 'PO6':'PO6', 'OZ':'Oz',
'HEO':'HEOG', 'VEO':'VEOG'} #有多少改多少
raw_rename_ch = raw.copy().rename_channels(mapping) #不想直接对原始数据进行修改,copy一份,再修改通道的名称
montage = mne. channnels.read_custom_montage('standard-10-5-cap385.elp') #读取通道定位文件
raw_rename_ch.set_montage(montage) #进行通道定位
raw_rename_ch.plot_sensors() #画出通道分布图
raw_rename_ch.plot_sensors(ch_type = 'eeg', show_names = True, sphere = 0.075) #重新调节分布图上的参数,三个参数分别对应通道的类型 通道的名称 和脑子轮廓的大小
raw_rename_ch.plot_psd(fmin = 1, fmax = 70, spatial_colors = True) #画出原始psd图(频谱相应图,1-70为频率范围)

50hz的时候有个小尖尖,为干扰
#去除无用电极 (更改并选择通道类型)
raw_select_ch = raw_rename_ch.copy()
#定义一些通道的类型 将HEOG和VEOG定义为眼电电极
raw_select_ch.set_channel_types({'HEOG':'eog','VEOG':'eog'})
raw_select_ch.info
raw_select_ch.pick(['eeg']) #只保留eeg信息
raw_select_ch.info
二、滤波
1.带通滤波:给两个频率点,中间是需要的
#脑电特征,小信号,大噪声
raw_band = raw_select_ch.copy().filter(0.1,30,picks = 'eeg')
#滤波,0.1-30的带通滤波,具体频率范围根据实验需要自己选择,大于和小于的部分是衰减
raw_band.plot_psd(fmin=1, fmax = 70, spatial_colors = True)
#绘制频谱相应图,方便观察滤波前后数据在频域响应上的变化
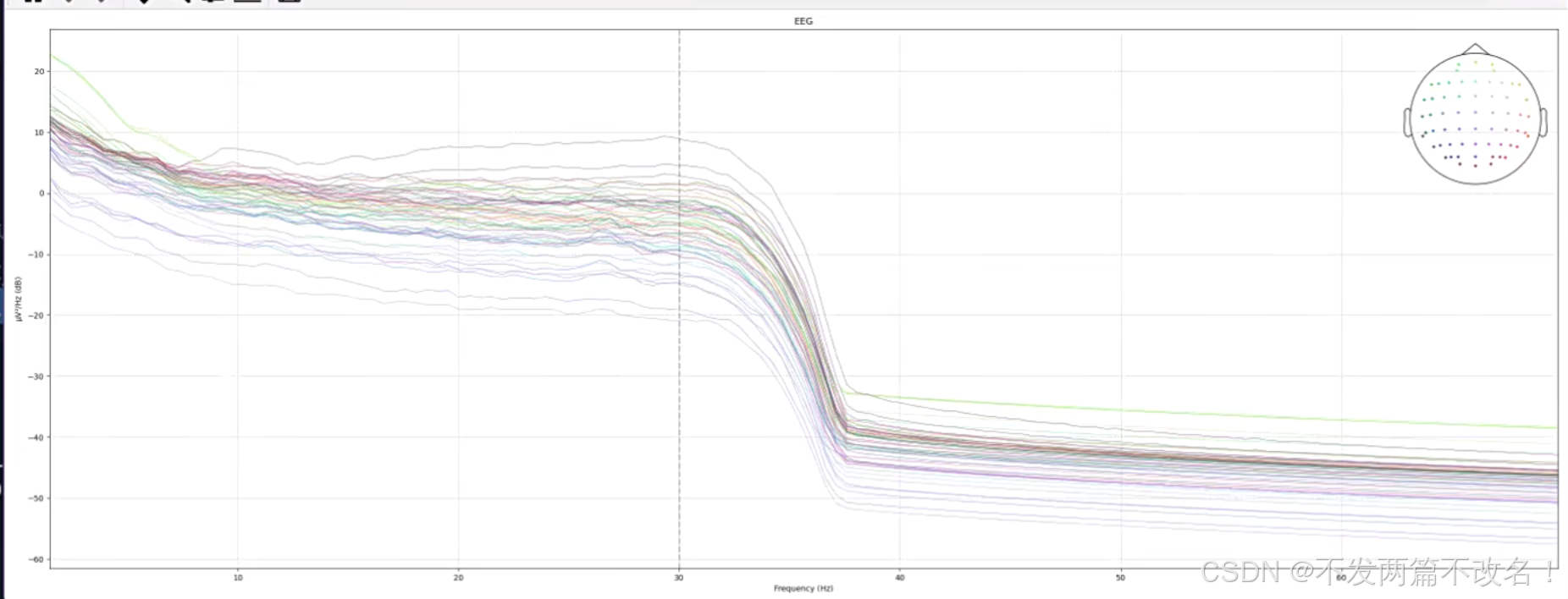
由图可知,大于30Hz的频率被衰减,滤波的目的是任为0.1-30有用,为了使数据更加精细,可以再用凹陷滤波去除工频干扰(50Hz)
2. 凹陷(带阻)滤波:给两个频率点,频率点外面的是需要的
raw_band.info
raw_band_notch = raw_band.notch_filter(50, notch_widths = 4)
# 以50hz为中心点,加一个宽度为4hz的范围是不要的,48-52hz的带通
raw_band_notch.plot_psd(fmin=1, fmax = 70, spatial_colors = True)
能够分析到的最大频率是采样率的一半,但实际上能够准确分析到的频率是采样率的1/3-1/4,降采样的好处是缩减数据量,节约计算和存储成本,但是要注意将采样后的数据对频域分析的影响,先滤波再将采样。
raw_resampled = raw_band_notch.copy().resample(sfreq = 500)
#对数据将采样到500hz
raw_resampled.info
vmrk, marker(annotation)在哪个时间点上出现哪个刺激,方便后面进行分析
三、分段
#读取数据的marker信息,event_dict字典,前面为Key,后面为value, 刺激类型和标记的关系
events_from_anno, event_dict = mne.events_from_annotations(raw_resampled)
print(event_dict)
print(events_from_anno)
#第一列:每个标记出现的时间点(在哪个采样点下出现marker);第二列:持续时间(0);第三列:代表刺激的类型
custom_mapping = {'Stimulus10': 10, 'Stimulus11': 11}
# 定义想要对什么marker的数据进行分段
(events_from_anno, event_dict) = mne.events_from_annotations(raw_resampled, event_id = custom_mapping)
# 更改数据中的marker信息
print(event_dict)
print(events_from_anno)
#对数据进行分段 定义分段的长度 和基线的范围 以刺激为原点 向前取0.2s 向后 取0.8s
my_epochs = mne.Epochs(raw_resampled, events_from_anno, tmin = -0.2, tamx = 0.8, baseline = (-0.2,0))
#基线校正
my_epochs.apply_baseline()
my_epochs.info
为什么对数据进行分段,受到刺激10,以10为中心,划分出一段(事件相关的一段),判断反应对了还是错了,对了就标记100,错了标记200。
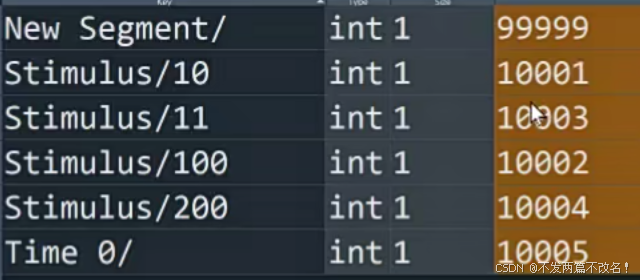
六个列别的刺激,其中New Segment和Time 0 为机器自动打的,100和200代表反应标记,判断反应对了还是反应错了,10和11为刺激标记。
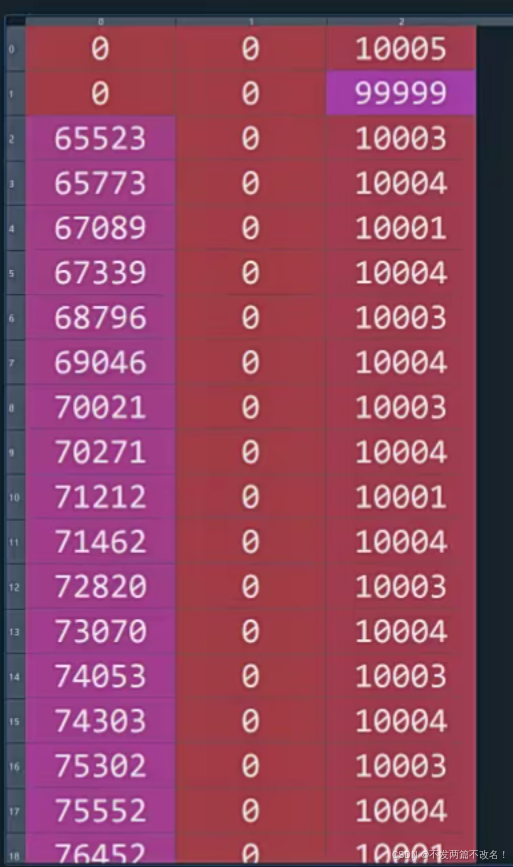
保存分段好的数据
import pickle
#用pickle 把my_epochs变量存成my_epochs.pkl文件
output = open('my_epochs.pkl','wb')
pickle.dump(my_epochs, output)
output.close()
del my_epochs
#将my_epochs.pkl文件读进来 读取在my_epochs变量中
pkl_file = open('my_epochs.pkl','rb')
my_epochs = pickle.load(pkl_file)
pkl_file.close()
my_epochs.info
去除坏段
my_epochs_good = my_epochs.copy()
#绘制数据 分段前的数据 定义绘制数据的时间长度 分段后的数据 定义绘制的分段个数
#将认为是坏段的数据手动将分段标红
my_epochs_good.plot(n_epochs = 5, n_channels = 64)
#去除标记果的坏段
my_epochs_good.drop_bad
my_epochs_good.info
#查看剩余分段的信息
print(len(my_epochs_good.events))
#插值坏电极
#标记坏通道 通道为灰色即为成功
my_epochs_good.plot(n_epochs = 5, n_channels = 64)
#进行坏通道插值
good_ch = my_epochs_good.load_data().copy().interpolate_bads(reset_bads=True)
good_ch.info
good_ch.plot(n_epochs = 5, n_channels = 64)
三、ICA独立成分分析
ICA的意图是去伪迹,但是ICA不是万能的,比较好算出来的独立成分是类似于眼电,肌电。在数据中对数据影响并不是非常大,而且出现比较规律。在做ICA之前,先对数据进行坏段去除、坏导插值,将规律的眼电信息保留。
from mne.preprocessing import (ICA)
ica_data = good_ch.copy()
#定义ICA 独立成分分析的数量,数量 = 实际的电极数量-坏通道的数量,但是当电极很多的时候,可以只进行64个独立成分的分解
ica = ICA(n_components = 50)
#进行ICA分析
ica.fit(ica_data)
#绘制ICA的独立成分图
ica.plot_components()
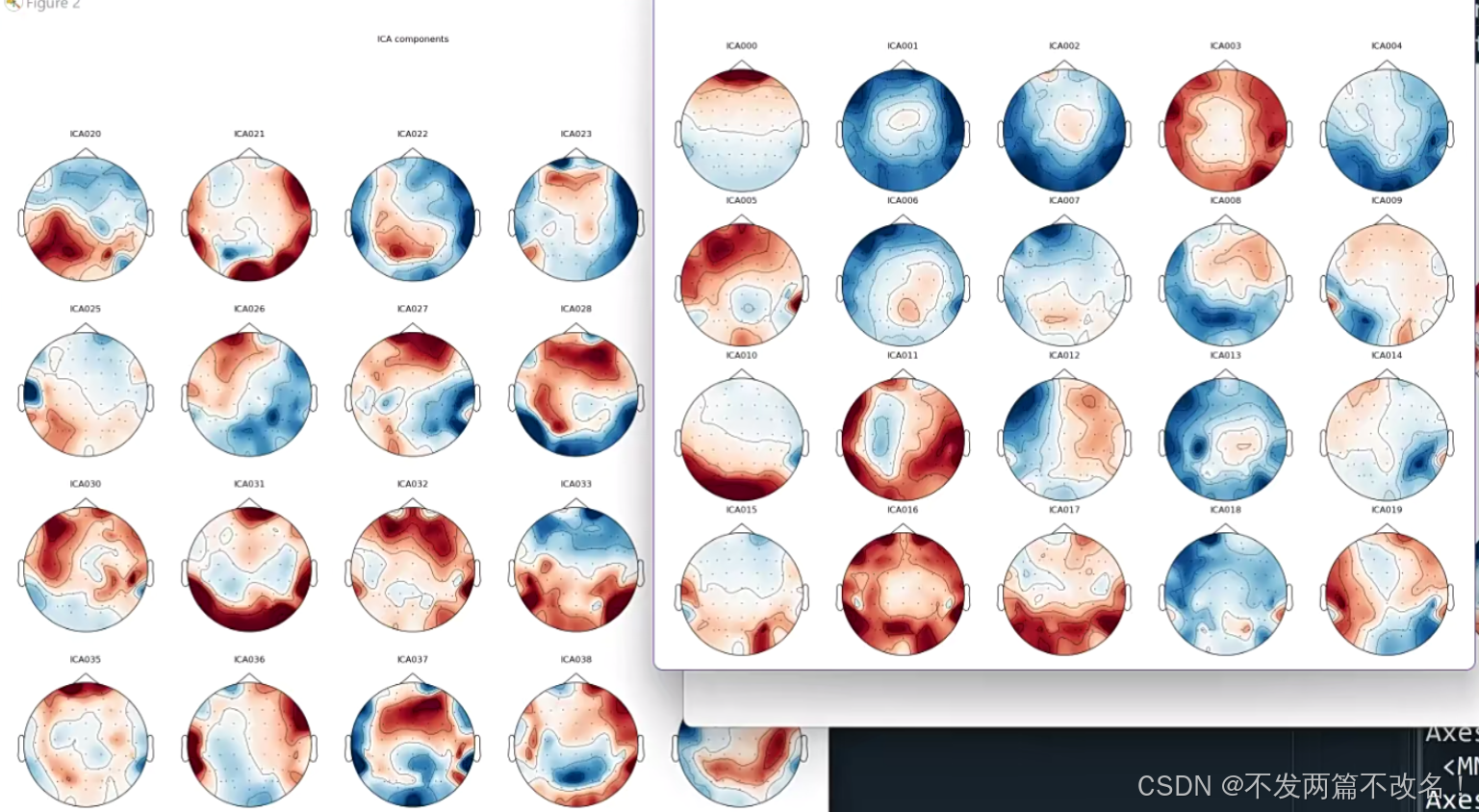
跑出来对数据影响最大的就算第一个成分(00),对数据影响最小的是最后一个成分。颜色红和蓝代表权重上的正与负,红和蓝的程度代表响应的程度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









