







目的:url:https://xueqiu.com/ ,需求就是爬取热帖内容
页面整体分析
代码分析
import requests
#
# 创建一个空白的session对象
session = requests.Session()
# url:https://xueqiu.com/ ,需求就是爬取热帖内容
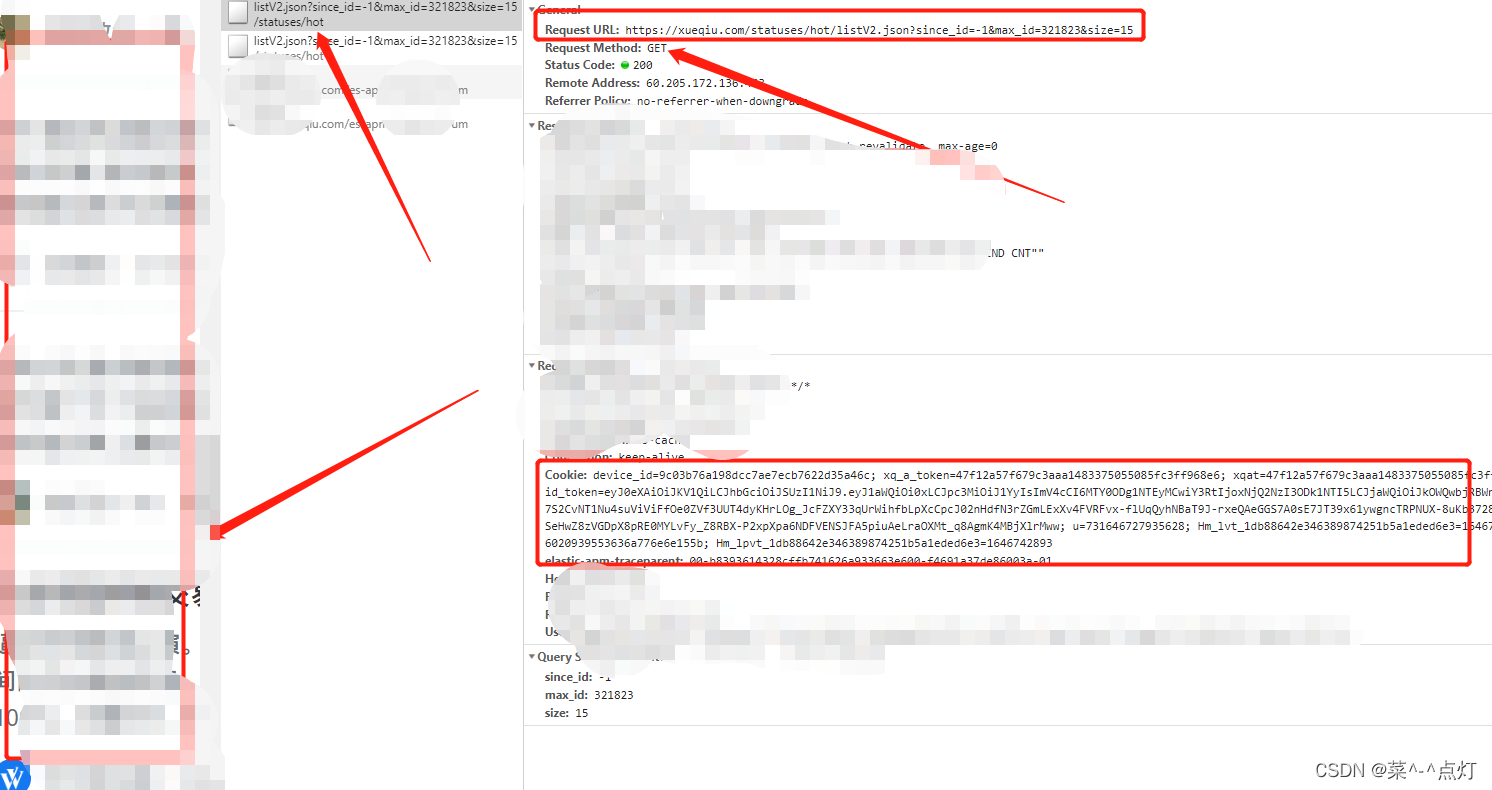
# 经过分析发现帖子的内容是通过ajax动态加载出来的,因此通过抓包工具,定位到ajax请求的数据包,从数据包中提到:
# url = https://xueqiu.com/statuses/hot/listV2.json?since_id=-1&max_id=321708&size=15
# 请求方式:get
# 请求参数:拼接在url后面
# 变故 -> cookie处理机制
# 分析why?
# 切记:只要爬虫拿不到你想要的数据,唯一的原因是爬虫程序模拟浏览器的力度不够!一般来讲,模拟的力度重点放置在请求头中
# 只需要在请求头 headers 中添加cookie中即可!
# 爬虫中cookie的处理方式(两种方式):
# 手动处理:将爬包工具的cookie赋值到headers中即可
# 缺点
# 编写麻烦
# cookie通常都会存长有效时长
# cookie中可能会存在实时变化的局部数据
# 自动处理
# 基于session对象实现自动处理cookie
# 1.创建一个空白的session对象
# 2.需要使用session对象发起请求,请求的目的是为了捕获cookie
# 注意:如果session对象在发请求的过程中,服务器端产生了cookie,
# 则cookie会自动存储在session对象中。
# 3.使用携带cookie的session对象,对目的网址发起请求,就可以实现携带
# cookie的请求发送,从而获取想要的数据。
# 注意 session对象至少需要发起两次请求
# 第一次请求的目的是为了捕获存储cookie到session对象.
# 后次的请求,就是携带cookie发起的请求了
# 手动添加
# headers = {
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
# 'Cookie': 'device_id=9c03b76a198dcc7ae7ecb7622d35a46c; acw_tc=2760779816467278738956459e6e8317192641988ad10e8342370fb1c37240; xq_a_token=47f12a57f679c3aaa1483375055085fc3ff968e6; xqat=47f12a57f679c3aaa1483375055085fc3ff968e6; xq_r_token=9c315184fa0eb80e33c16122000a48b423dafec5; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTY0ODg1NTEyMCwiY3RtIjoxNjQ2NzI3ODk1NTI5LCJjaWQiOiJkOWQwbjRBWnVwIn0.l26Ix1ew0933oV96eenI9jU7XhsfQvclY_O3JCQgHPwuR7PSljuiPB3B57S2CvNT1Nu4suViViFfOe0ZVf3UUT4dyKHrLOg_JcFZXY33qUrWihfbLpXcCpcJ02nHdfN3rZGmLExXv4FVRFvx-flUqQyhNBaT9J-rxeQAeGGS7A0sE7JT39x61ywgncTRPNUX-8uKb3728fEM9Fr92m6O_JYNS6KCjxYDNKh_ubev40MFWbmcwoXj872t9q-jm9K6rbeIGrBkSeHwZ8zVGDpX8pRE0MYLvFy_Z8RBX-P2xpXpa6NDFVENSJFA5piuAeLraOXMt_q8AgmK4MBjXlrMww; u=731646727935628; Hm_lvt_1db88642e346389874251b5a1eded6e3=1646725798,1646727937; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1646727939'
#
# }
# 自动添加
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
main_url = 'https://xueqiu.com/'
# 使用session发起的请求,目的是为了捕获到cookie,且将其存储到session对象中
session.get(url=main_url,headers=headers)
url = 'https://xueqiu.com/statuses/hot/listV2.json'
param = {
'since_id': '-1',
'max_id': '321708',
'size': '15'
}
# 就是使用携带了cookie的session对象发起的请求(就是携带者cookie发起的请求)
response = session.get(url=url,headers=headers,params=param)
data = response.json()
print(data)
结果


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









