 矩池云Hugging Face数据加速下载指南
矩池云Hugging Face数据加速下载指南




相信使用矩池云的小伙伴们一定很苦恼在Hugging Face下载数据,现在矩池云给大家准备一个非常好用的工具,能够加速在Hugging Face 下载数据和模型,就让我们一起来了解一下吧!!!
首先我们租用机器时会弹出一个提示:
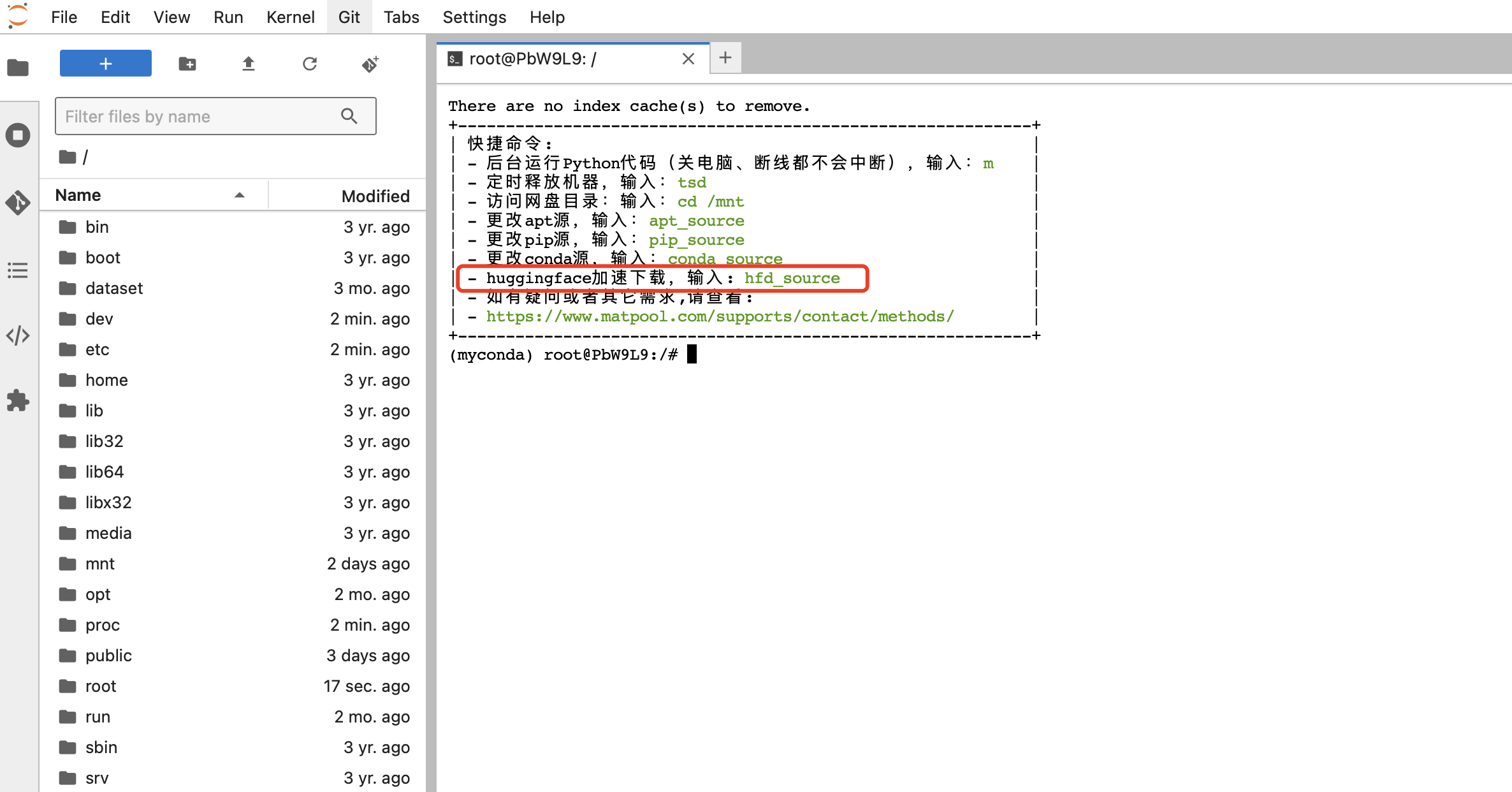
这就是我们的huggingface加速下载的命令,接下来我们执行这个命令查看一下:

如上图所示,在我们执行这个命令之后,有两个提示我们有一些依赖和工具未安装,那我们就按照提示吧依赖和工具安装起来,建议安装以来和工具的时候先把下载源改为国内的哦
在安装好依赖和工具之后,我们再次执行hfd_source这个命令,可以看到已经提示依赖和工具已经安装完毕,可以正常使用,已经这个命令使用的一些方式参数:
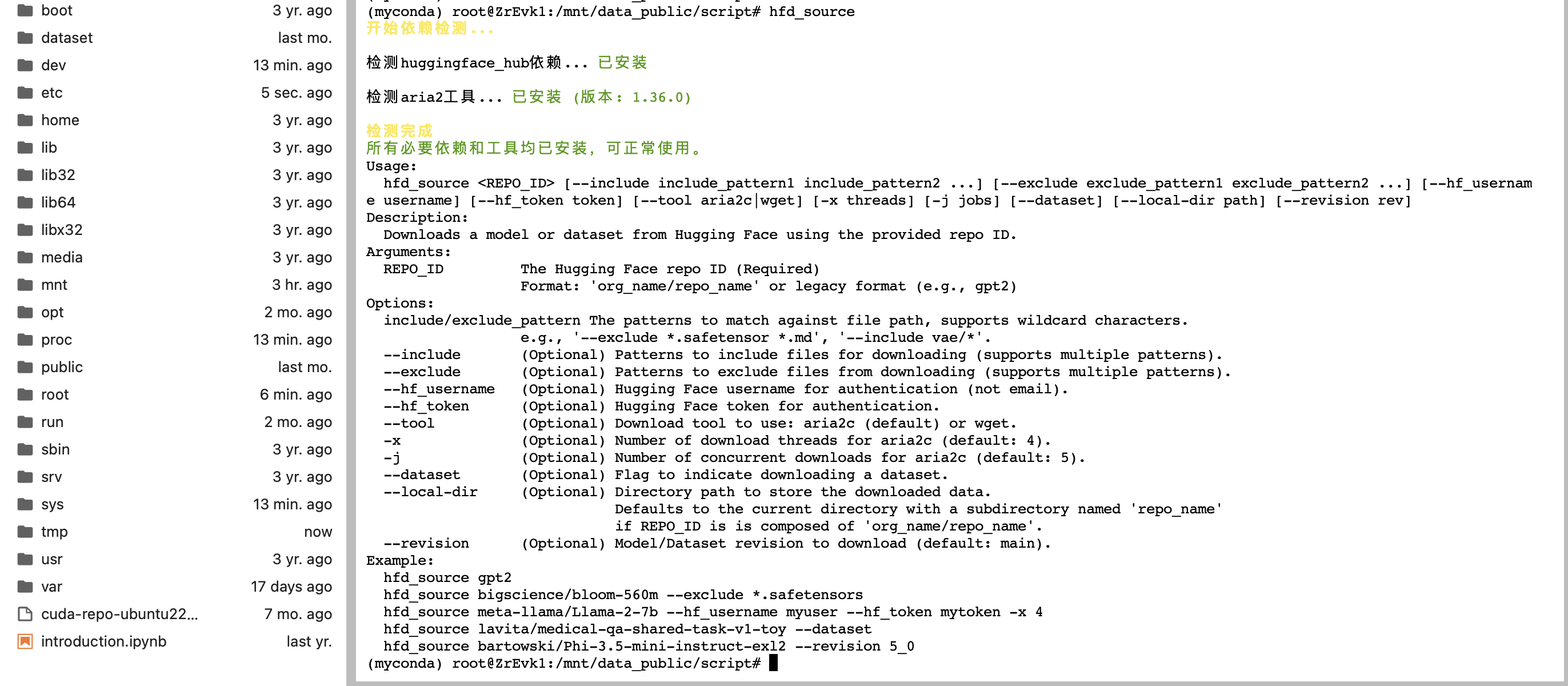
接下来我们就来测试一下,使用这个命令下载huggingface下的gpt2模型:

可以看到,已经正常下载,并且速度可观。默认是开启4个线程下载,并发数为5,下载目录为当前所在目录,如有其他需求,可执行hfd_source --help命令查看参数信息和使用案例
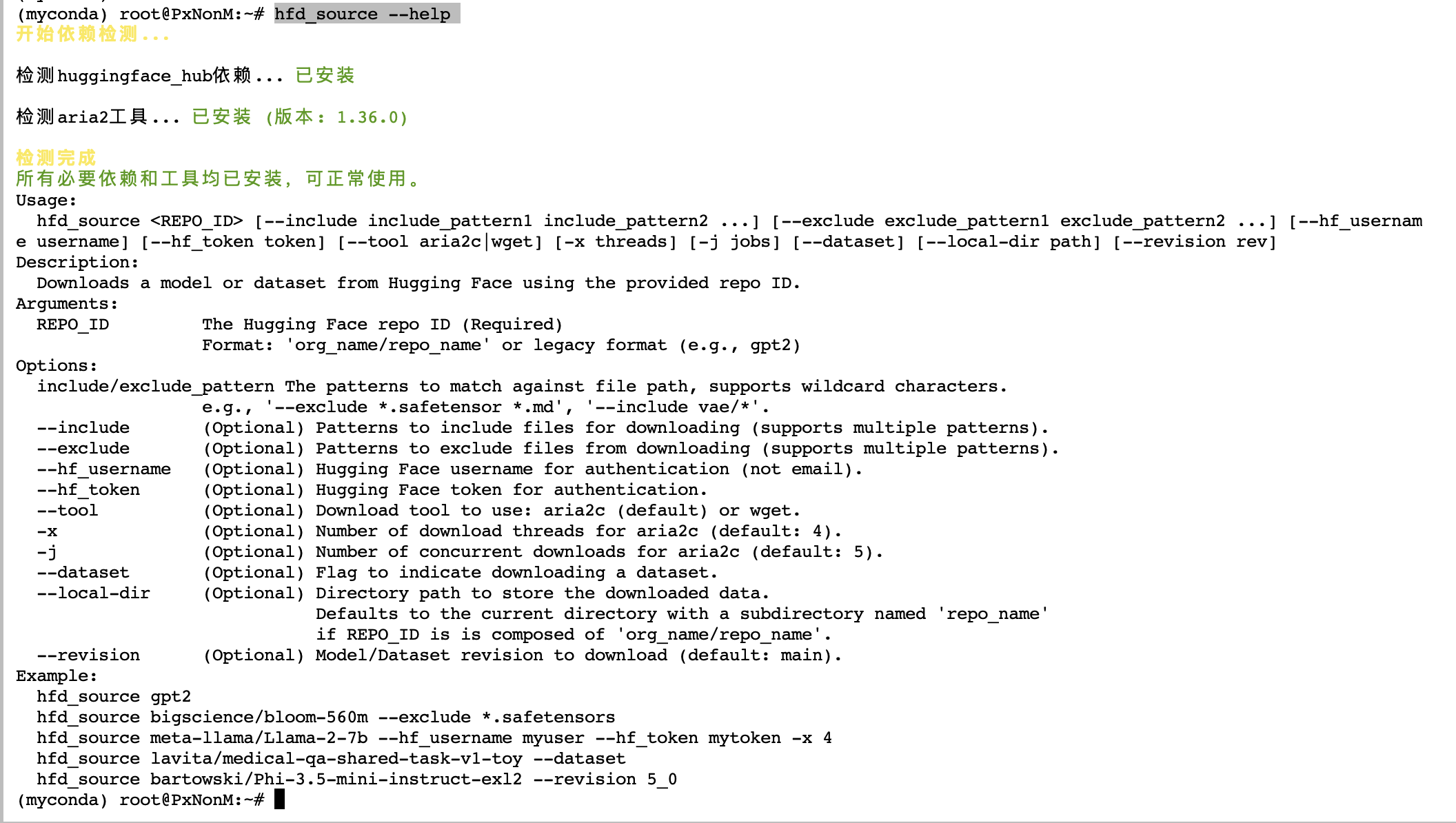
如果需要下载数据集,则需要添加一个参数 --dataset,示例如下:

否则的话会提示如下错误:

有一些项目是和数据集是需要登陆账号才能下载,可以使用以下参数:
hfd_source meta-llama/Llama-2-7b --hf_username YOUR_HF_USERNAME --hf_token hf_***

















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









