






4. 同步方式(增量和全量)
4.1 数据同步一般分为两种方式:全量和增量。
全量
全量,这个很好理解。就是每天定时(避开业务高峰期)或者周期性全量把数据从一个地方拷贝到另外一个地方;
全量的话,可以采用直接全部覆盖(使用“新”数据覆盖“旧”数据);或者走更新逻辑(覆盖前判断下,如果新旧不一致,就更新);
这里面有一个隐藏的问题:如果采用异步写,主数据物理删除了,怎么直接通过全量数据同步?这就需要借助一些中间操作日志文件,或者其他手段,把这些“看不到”的数据记录起来。
增量
增量的基础是全量,就是你要使用某种方式先把全量数据拷贝过来,然后再采用增量方式同步更新。
增量的话,就是指抓取某个时刻(更新时间)或者检查点(checkpoint)以后的数据来同步,不是无规律的全量同步。这里引入一个关键性的前提:副本一端要记录或者知道(通过查询更新日志或者订阅更新)哪些更新了。
增量的话需要确定更新点
采用更新时间戳、有的采用checkpoint等来标识和记录更新点。
4.2 在增量同步过程中需要注意的一点(重点)
# mysql 中表查询的上限大概在500万左右
# 增量表的后缀名为 delta 所以我们需要改变昨天的表名(全部)
# 我们在配置json脚本中需要加上判断条件,而且也不能写死应该搞一个变量(${ds})传进去
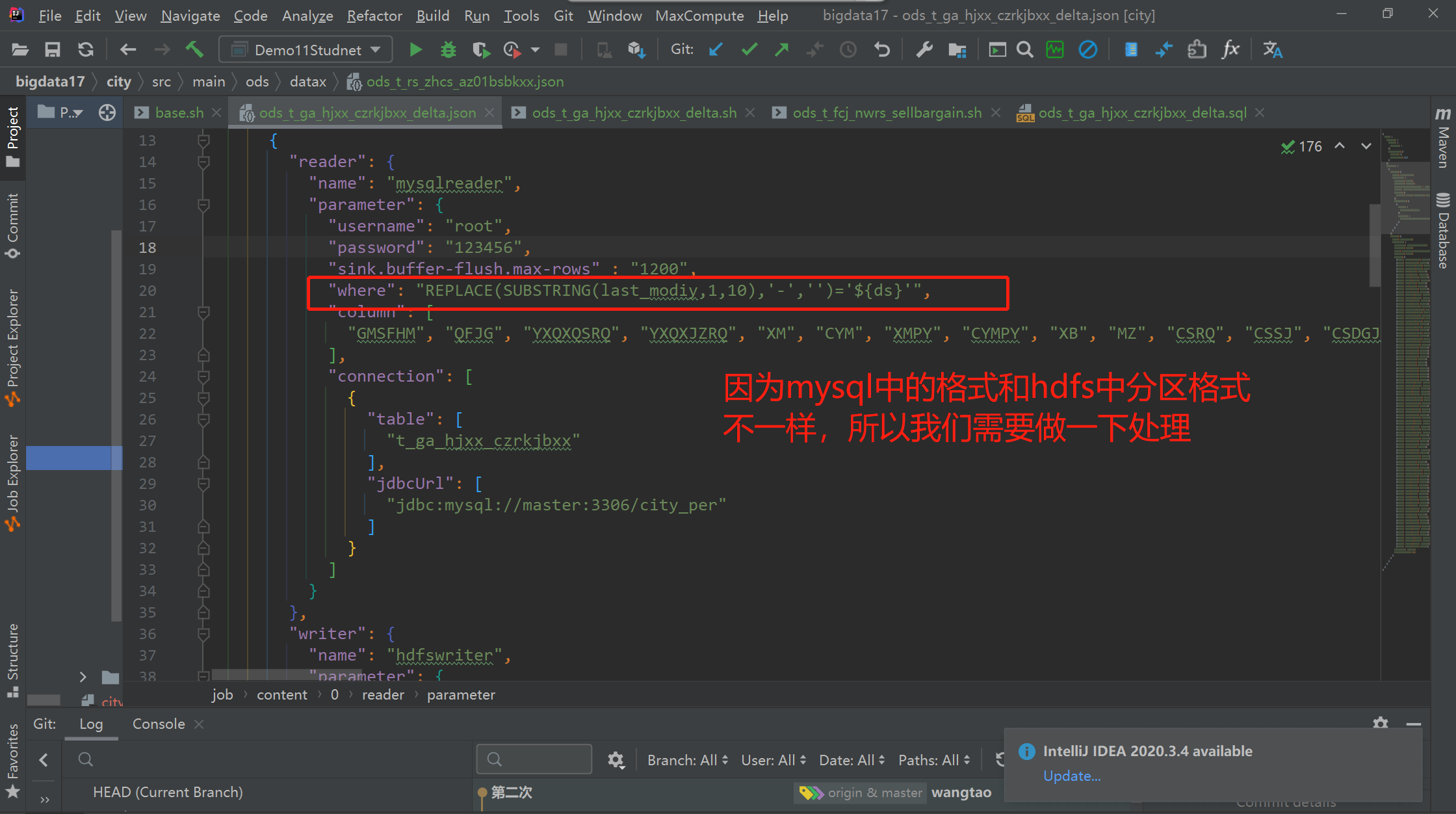
# 可能在mysql中的时间字段和在hdfs中的分区名字不一样,需要做处理,譬如在mysql中的时间为 2022-08-06,但是在hdfs中的却是20220806,这时我们需要做处理4.3 增量和全量的优缺点
# 使用全量同步时我们可能需要删除历史的数据,以免造成资源浪费,但是这会产生一个问题,当某一天的数据发生错误时,我们不能回溯到那一天的数据(因为有可能被我们删除了)
# 使用增量表时,有可能不是增加而是修改,这样一个用户有可能会产生多条数据(解决办法):我们使用row_number按照id分组,然后按照时间排序,取出第一条数据就可以在mysql中的数据如下:

在脚本文件中文件名字需要修改 增量表的后缀名需要加上 . delta

因为是增量,每天拉取新增的量,所以需要在脚本中设置一下 where条件

通过执行脚本文件,sh 脚本 20220806 得到结果

第一个分区:

第二个分区
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









