







本文整理自 OpenMLDB Meetup No.5 中 OpenMLDB PMC 邓龙的演讲。本文深入解析 OpenMLDB 架构设计背后的硬核技术,带领大家了解 OpenMLDB 毫秒级实时在线特征计算引擎内部实现。
分享视频如下:
视频链接:https://www.zhihu.com/zvideo/1537772166535331840
接下来作者将从“OpenMLDB 整体架构”、“在线实时 SQL 执行引擎和存储引擎”、“在线引擎性能测试”三个板块为大家介绍 OpenMLDB 毫秒级的实时在线特征计算引擎。
一、OpenMLDB 整体架构
1.1 OpenMLDB 是线上线下一致的生产级特征平台
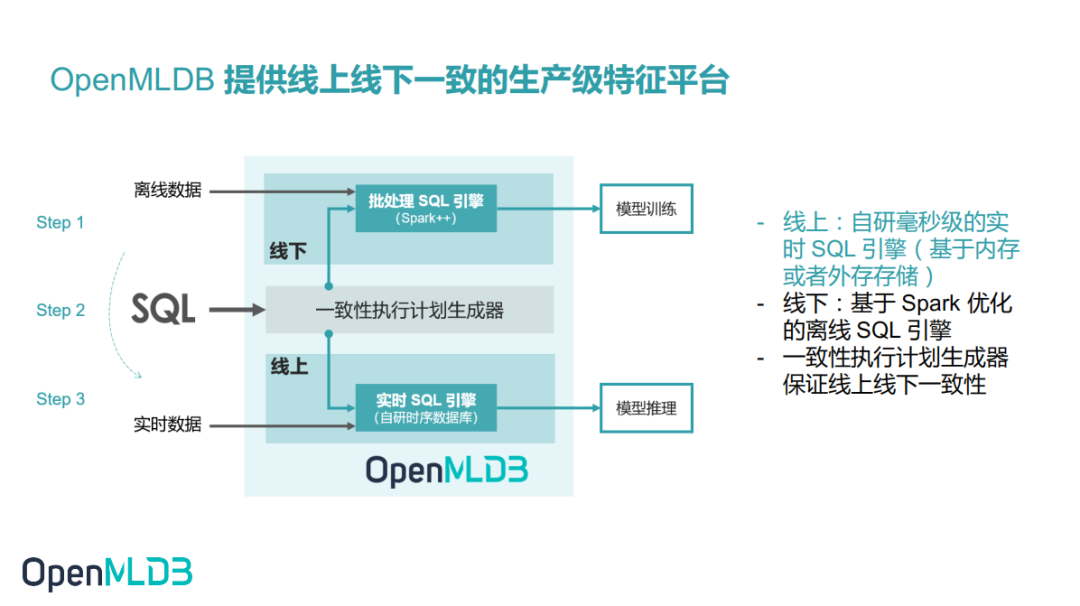
OpenMLDB 是一个提供线上线下一致性的生产级特征平台,我们对外提供的是一整套的 SQL 语言。用户可以通过 SQL 语言写成脚本,再用 OpenMLDB 离线引擎做批量计算,进行模型探索。探索完成后,SQL 脚本能直接上线通过 OpenMLDB 的在线实时引擎完成实时特征计算。
在离线部分,OpenMLDB 的离线特征计算引擎是基于 Spark 做了一个改造。Spark 会用 JNI 的方式来调用我们生成的SQL解析执行库。在线部分,我们用自研实时计算引擎来做实时计算。OpenMLDB离线和在线引擎使用同一套一致性执行计划生成器,运行同一套代码,天然保证了线上线下的一致性。
1.2 OpenMLDB 线上引擎整体架构
1.2.1 主要模块
OpenMLDB 线上引擎包含的主要模块有 Apache ZooKeeper, Nameserver 以及 Tablet (Tablet包括SQL Engine 和 Storage Engine)。下图显示了这些模块之间的关系。其中 Tablet 是整个 OpenMLDB 存储和计算的核心模块,也是消耗资源最多的模块。

- ZooKeeper 在 OpenMLDB 中用于服务发现和元数据存储和管理功能。ZooKeeper 和 OpenMLDB SDK,Tablet, Namesever 之间都会存在交互。
- Nameserver 主要用来做 Tablet 管理以及故障转移(failover)。当一个 Tablet 节点宕机后,Nameserver 就会触发一系列任务来执行故障转移。当节点恢复后会重新把数据加载到该节点中。同时,为了保证 Nameserver 本身的高可用,Nameserver 在部署时会部署多个实例,并采用primary/secondary 的模式。同一时刻只会有一个 primary 节点。多个 Nameserver 通过 ZooKeeper 实现 primary 节点的抢占。因此,如果当前 primary 节点挂掉,则 secondary 节点会通过 ZooKeeper 重新选出一个 primary 节点。
- Tablet 模块负责执行SQL、存储数据。从
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2307
2307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









