







为什么要数据规范化
- 信息重复
- 更新异常
- 插入异常
- 无法正常显示信息
- 删除异常
- 丢失有效信息
三大范式
第一范式(1NF)
- 原子性:保证每一列不可再分
- 关系模式中的所有属性值都是不可再分的原子值
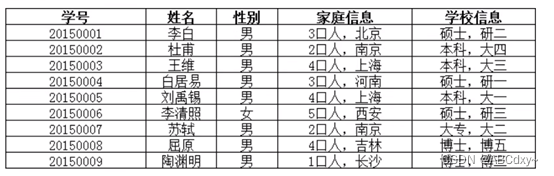
在上面的表中,“家庭信息”和“学校信息”列均不满足原子性的要求,故不满足第一范式,调整如下:

第二范式(2NF)
-
前提:满足第一范式
-
第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)
-
即满足第一范式,且关系模式的任一非主属性都完全函数依赖与任一候选码
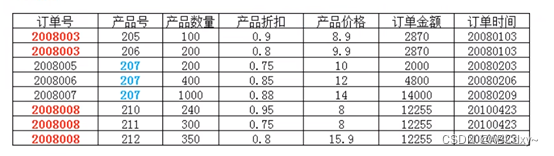
在上图所示的情况中,同一个订单中可能包含不同的产品,因此主键必须是"订单号"和"产品号"联合组成,但可以发现,产品数量、产品折扣、产品价格与'订单号"和"产品号"都相关,但是订单金额和订单时间仅与"订单号“相关,与"产品号"无关这样就不满足第二范式的要求,调整如下,需分成两个表:
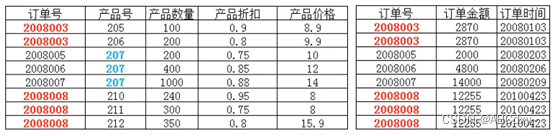
第三范式(3NF)
- 前提:满足第一范式和第二范式
- 第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
- 即满足第一、第二范式且不传递依赖于候选码
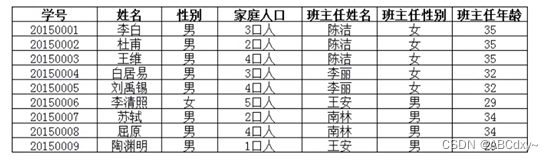
上表中,所有属性都完全依赖于学号,所以满足第二范式,但是“班主任性别”和“班主任年龄”直接依赖的是“班主任姓名”,而不是主键“学号”,所以需做如下调整:

BC范式(扩展)
- 不存在主属性候选码有部分/传递依赖
规范性和性能的问题
关联查询不得超过三张表
- 考虑商业化的需求和目标(成本,用户体验)数据库的性能更加重要
- 在规范性能的问题的时候,需要适当的考虑一下规范性
- 故意给某些表增加一些冗余的字段。(从多表查询中变为单表查询)
- 故意增加一些计算列(从大数据库降低为小数据量的查询:索引)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









