







【论文链接】https://arxiv.org/abs/2203.02177v2
问题动机
对话已成为社交媒体平台上的重要数据格式。由于其在人机交互中的广泛应用,从情感、内容等方面理解对话也越来越受到研究者的关注。在现实环境中,我们经常会遇到模态不完整的问题,这已经成为对话理解的核心问题。例如,语音可能由于背景噪音或传感器故障而丢失;由于自动语音识别错误或未知单词,文本可能不可用;由于光照、运动或遮挡,可能无法检测到面部。模态不完整的问题增加了准确理解对话的难度。
一方面,相邻的话语在对话中通常在语义上是相关的。另一方面,每个说话者都有自己的表达方式,在谈话中通常是一致的。然而,现有作品通常无法利用它们,从而限制了它们在会话数据中的性能。
解决方法
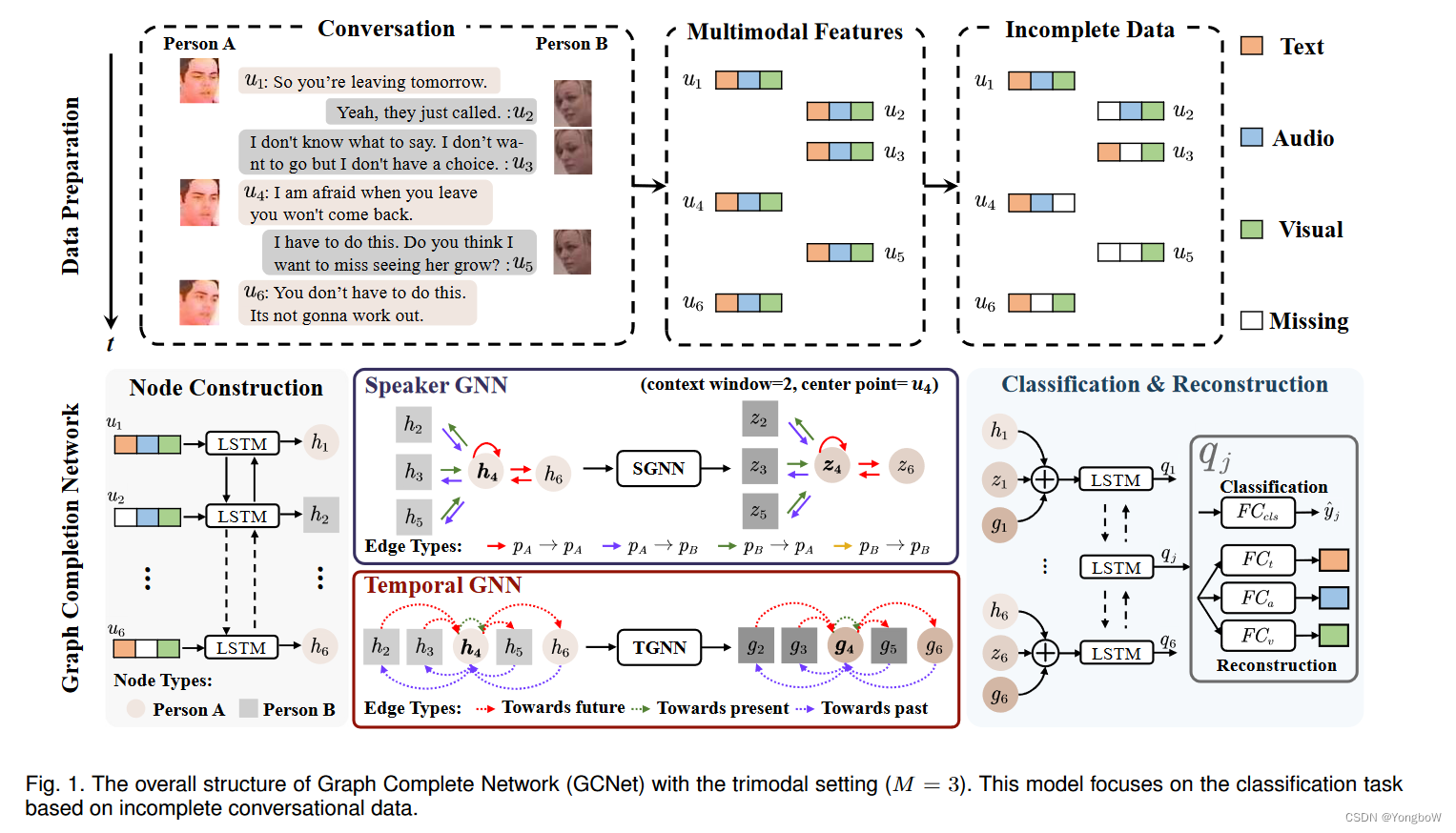
在本文中,提出了一种用于对话中不完整多模态学习的新框架,称为“图补全网络 (GCNet)”。我们的目标是在对话中充分利用时间和说话者信息来处理不完整的模态。具体来说,我们首先随机丢弃多模态特征来模拟真实世界的缺失模式。为了捕捉对话中的说话人和时间依赖性,我们提出了两个基于图神经网络的模块,“说话人 GNN (SGNN)”和“时间 GNN (TGNN)”。这两个模块共享相同的边,但边类型不同。最后,我们以端到端的方式联合优化分类和重建。
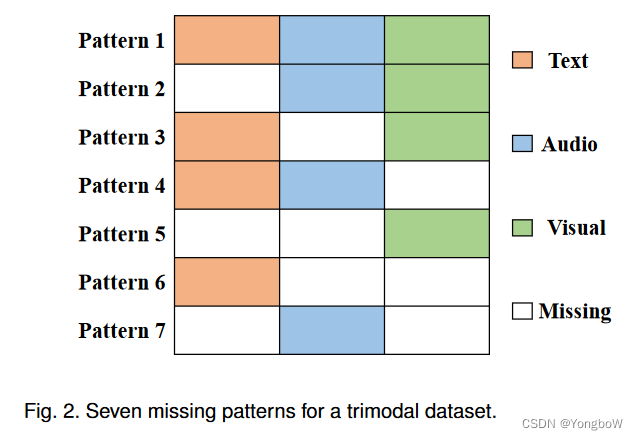
1. 为了模拟现实世界中缺失的场景,我们通过保证每个样本至少有一种模态可用来随机丢弃一些模态。因此,不完整的 M 模态数据集有 ( − 1) 个不同的缺失模式。以为本文是3模态的情况,所以,一共有7种确实情况,如图2。
2. 图补全网络主要由3个模块组成:节点构建、说话者和时间 GNN 以及分类和重建。
- 节点构建:我们将缺少模态的对话数据作为输入。每个对话包含多个话语,我们将每个话语
表示为节点
。为了提取
- 说话者和时间GNN:Speaker GNN (SGNN) 和 Temporal GNN (TGNN) 是捕获对话中说话人和时间依赖性的关键模块。在这些模块中,边衡量节点之间连接的重要性。边类型定义了节点交互中的不同聚合方法。SGNN 和 TGNN 共享相同的边但不同的边类型以捕获不同的依赖关系。
- 分类和重建:对于每个节点,我们提取其初始表示、考虑说话人信息的表示和考虑时间信息的表示。为了聚合这些表示,我们将它们连接在一起,然后利用 Bi-LSTM 进行上下文敏感建模。
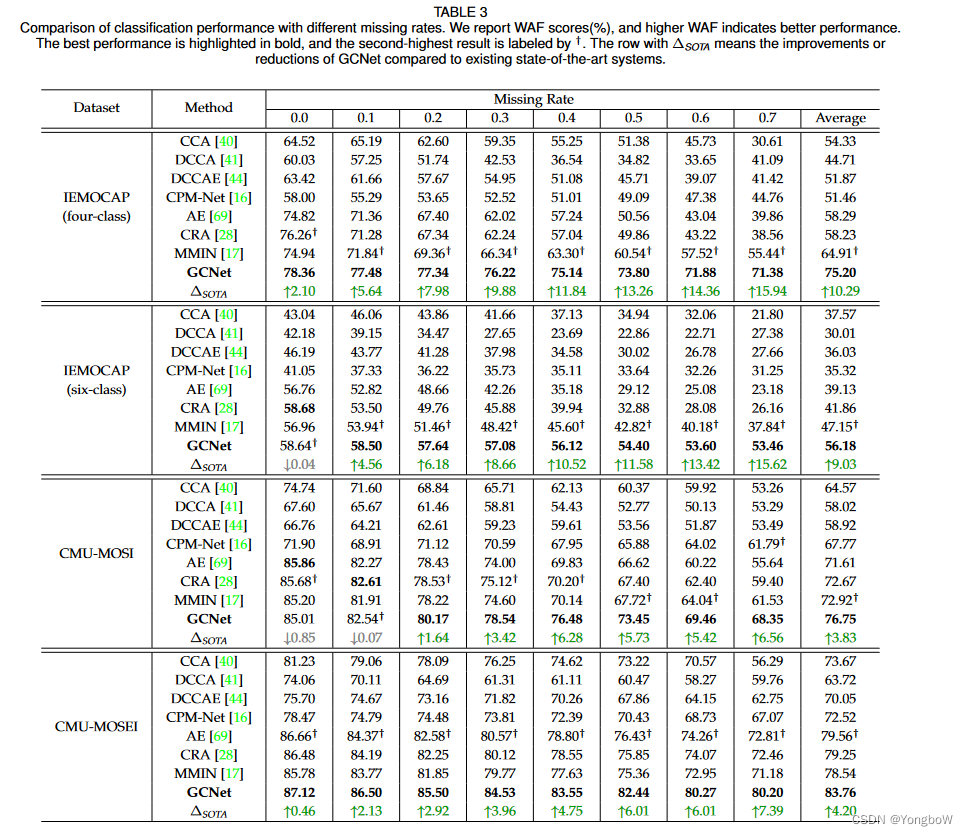
实验结果















 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









