






Don’t Hallucinate, Abstain:Identifying LLM Knowledge Gaps via Multi-LLM Collaboration(ACL杰出论文奖)

paper: https://aclanthology.org/2024.acl-long.786.pdf (ACL杰出论文奖)
论文概述
论文简介
提出了两种基于模型协作的新方法(合作与竞争),通过合作或竞争的方式让多个LLM相互探查知识缺口,并在一些情况下放弃回答来防止模型生成幻觉输出。
论文动机
作者认为避免产生低置信度的输出应该是LLM功能的一部分,需要察觉并改善大模型中存在的知识差距问题,比如在不清楚答案时放弃回答。
论文贡献
- 通过该方式相较于baseline上有19.3%的提高
- 弃权方法精确地反应出了检索增强中的失败情况和多跳推理中的知识缺口
Method
前置知识
论文将当前LLM弃权的方法归结为四类
- calibration-based(基于校准):例如采用温度缩放来校准模型,设定一个置信阈值,超出阈值则放弃
- training-based(基于训练):例如在llm的隐藏层上使用线性探测来评估生成的文本的准确性
- prompting-based(基于提示):例如在模型回答之前让模型输出更多细节信息
- self-consistency based(基于自我一致):例如用思维链的方式让模型生成多种结果来比对
在前四种弃权归类方式基础上,作者提出了第五种范式:
- collaboration-based(基于协作的):竞争与协作
具体实现方式
用合作(COOPERATE)、竞争(COMPETE)的方式来探索大模型之间的差距
- 合作: 不同的LLM被用来生成对所提出答案的反馈,并综合这些反馈得出是否放弃回答的决定。
- 竞争: 让其他LLM生成与原答案相冲突的信息,测试LLM在面对冲突信息时是否坚持原有答案。
合作(COOPERATE)
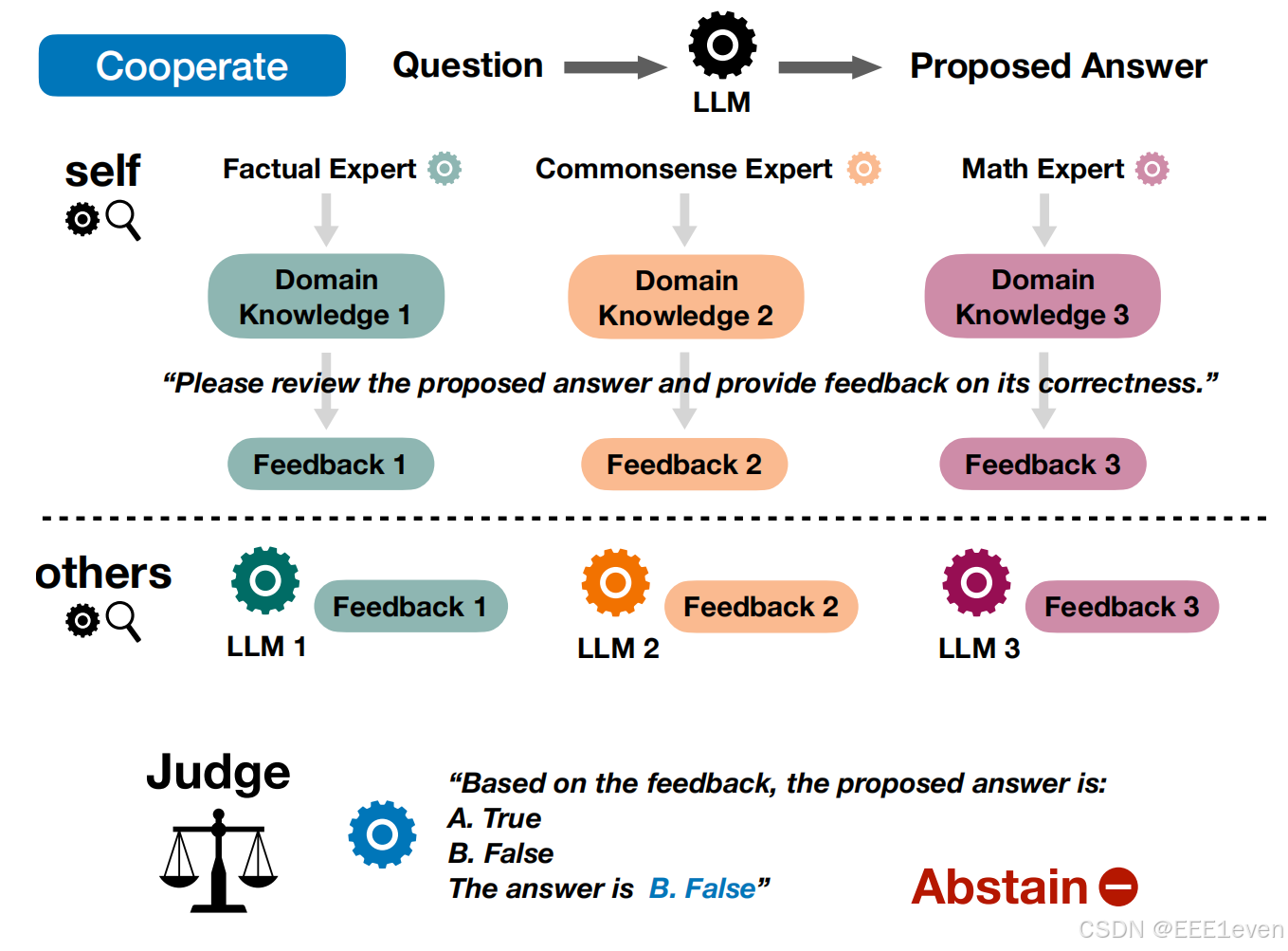
使用提示词来让一个LLM聚焦于不同的domain,在这个domain下,让LLM生成一个关于question的知识段落(
k
n
o
w
l
e
d
g
e
i
knowledge_i
knowledgei ),再将这些知识段落结合之前的问答输入回模型,让模型判断问答对的正确性,作为一个反馈(
f
i
f_i
fi):
f
i
=
LLM
(
k
n
o
w
l
e
d
g
e
i
,
q
,
a
)
f_i = \text{LLM}(knowledge_i, q, a)
fi=LLM(knowledgei,q,a)
在
L
L
M
LLM
LLM 中可以加入其他多个大模型
LLMs
{
LLM
1
,
…
,
LLM
k
}
\text{LLMs} \{ \text{LLM}_1, \dots, \text{LLM}_k \}
LLMs{LLM1,…,LLMk}
将上述的反馈与问答拼接作为输入,来让最开始的LLM判断:
LLM
(
q
,
a
,
{
f
1
,
…
,
f
k
}
)
→
{
accept
,
reject
}
.
\text{LLM}(q, a, \{f_1, \dots, f_k\}) \rightarrow \{ \text{accept}, \text{reject} \}.
LLM(q,a,{f1,…,fk})→{accept,reject}.
通俗理解:多个LLM合作判断一个问题
竞争(COMPETE)
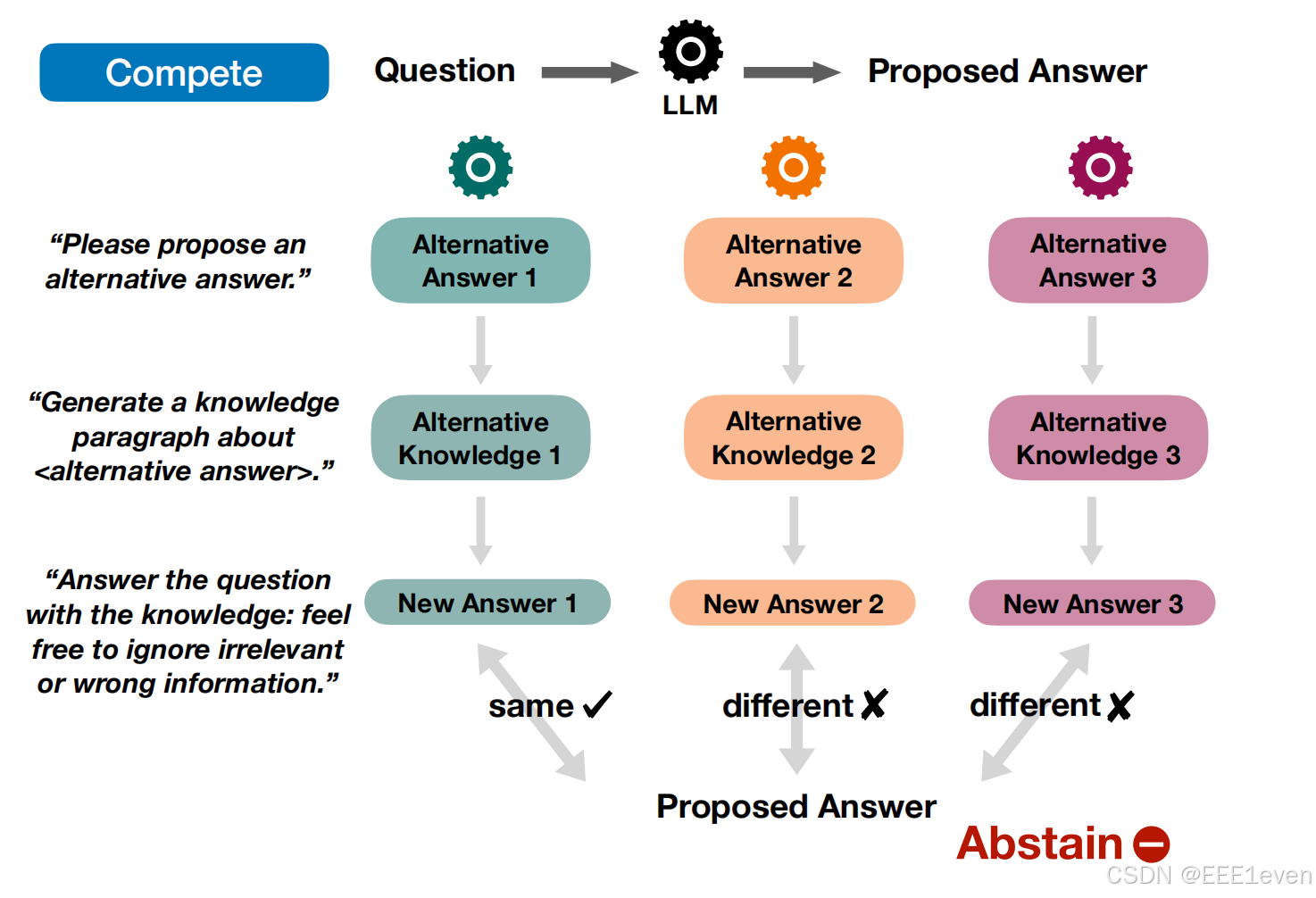
通过一个大模型来获取到回答
a
=
LLM
(
q
)
a=\text{LLM}(q)
a=LLM(q)
不同的大模型基于原问题来生成替代性的回答(冲突)
其中可以有多个模型:
LLMs
{
LLM
1
,
…
,
LLM
k
}
\text{LLMs} \{ \text{LLM}_1, \dots, \text{LLM}_k \}
LLMs{LLM1,…,LLMk}
生成多个回答:
{
a
1
′
,
…
,
a
k
′
}
\{ a'_1, \dots, a'_k \}
{a1′,…,ak′}
针对于该回答让LLM生成知识段落
k
n
o
w
l
e
d
g
e
i
knowledge_i
knowledgei ,对于所获取的知识段落再次作为输入
a
~
i
=
LLM
(
k
n
o
w
l
e
d
g
e
i
,
q
)
\tilde{a}_i = \text{LLM}(knowledge_i, q)
a~i=LLM(knowledgei,q)
如果新的输出于原先输出相等,即
a
=
a
~
i
a=\tilde{a}_i
a=a~i,则认为模型坚持之前的答案,因此不需要放弃输出;多个输出结果进行评判来确定这个最终结是否需要放弃。
实验结果
在多个数据集上,用不同的模型进行评测的结果
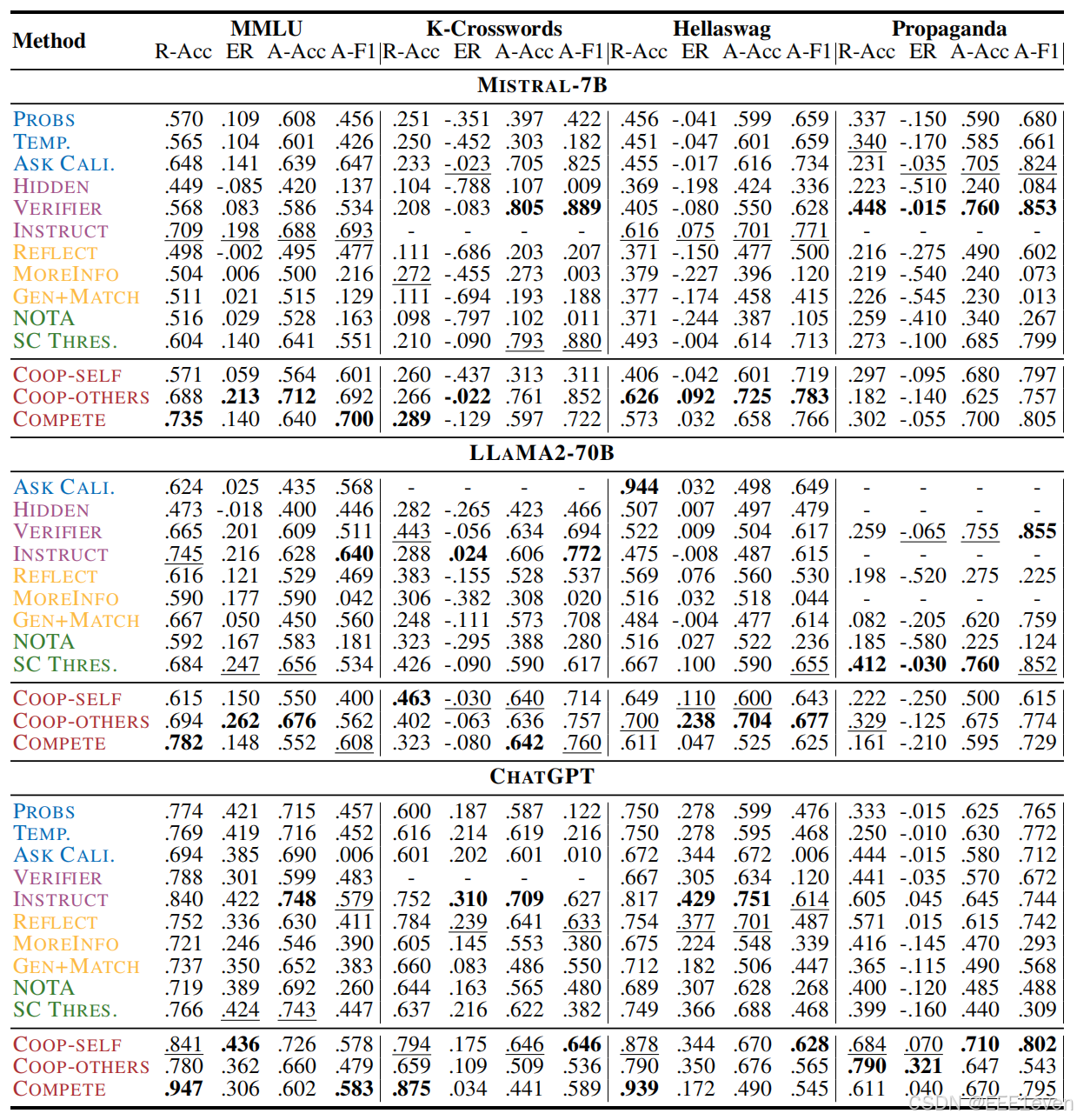
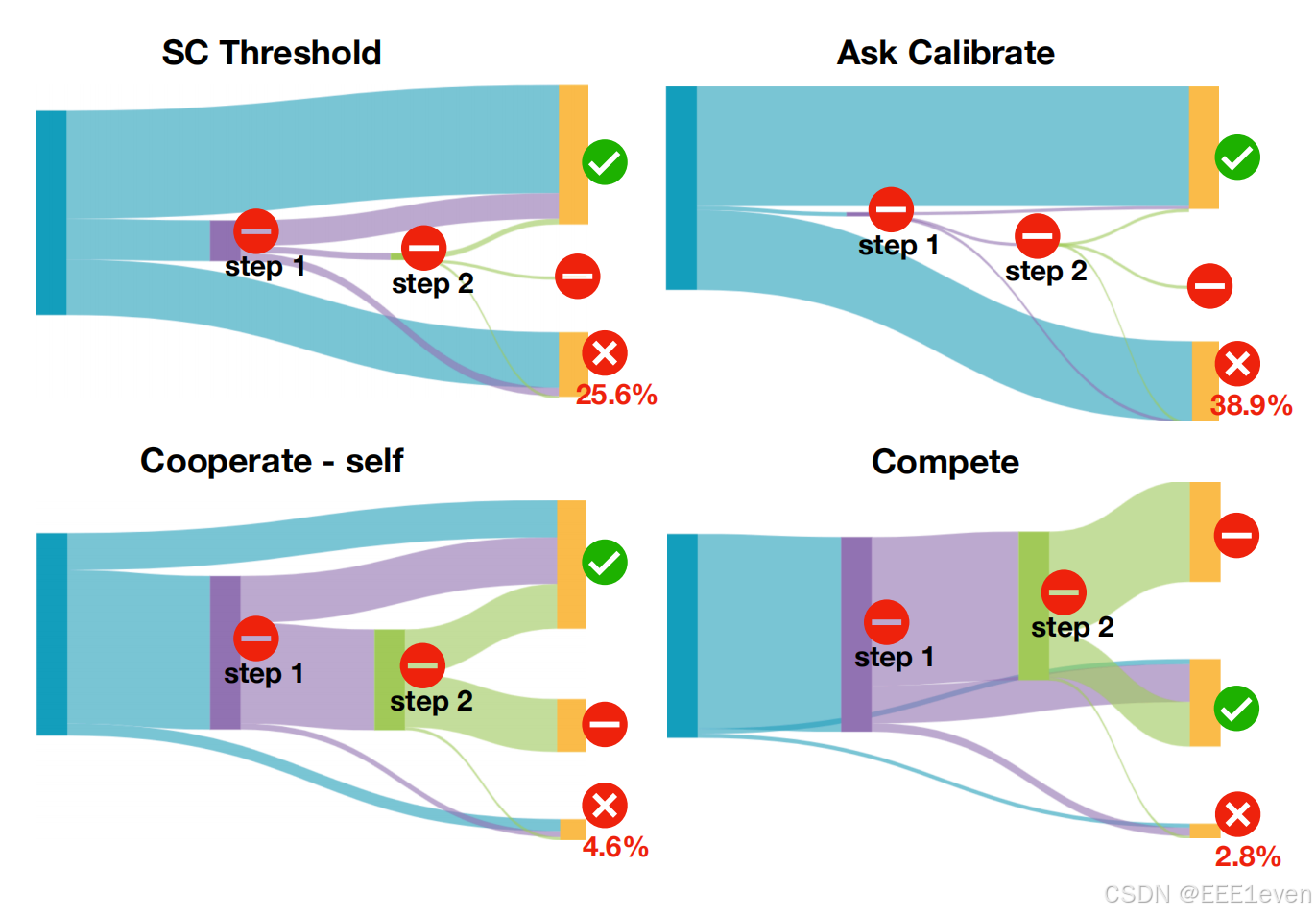
弃权实验,在100%需要放弃的情况下效果如何
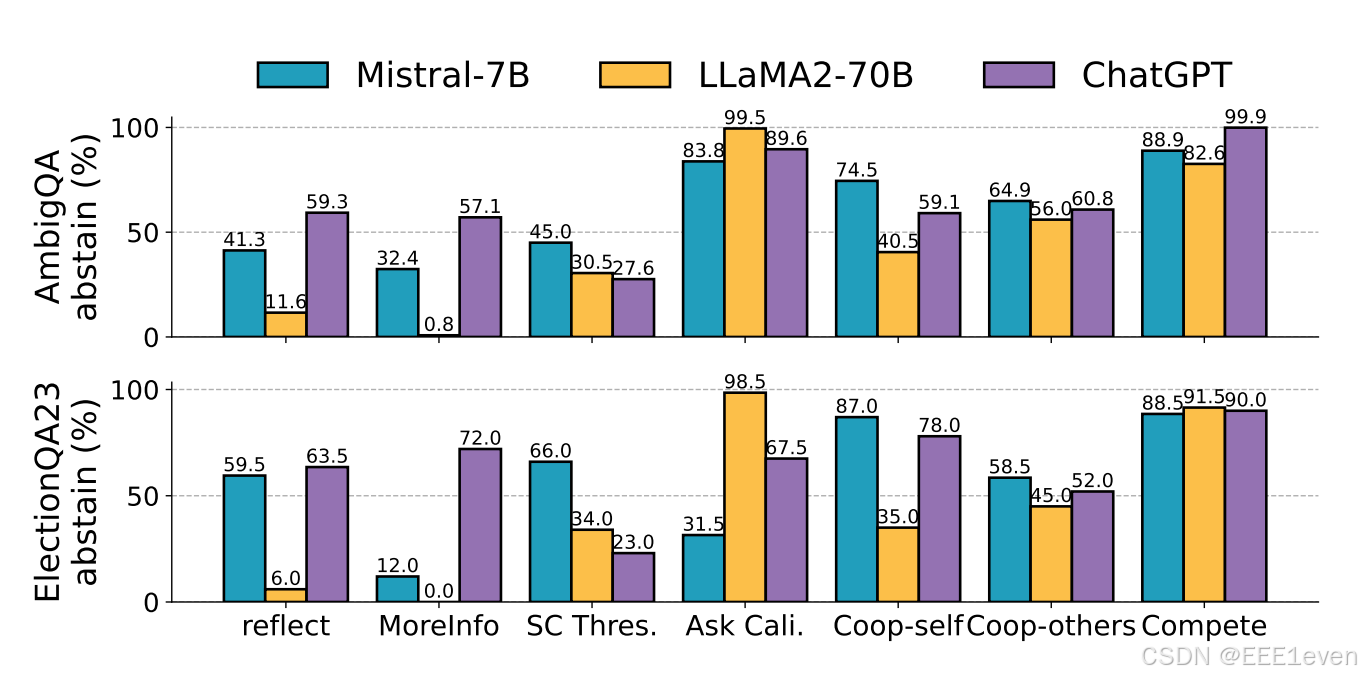
展现了LLM在100%需要弃权情况下的表现,可以看到竞争弃权的方式非常有效。
检索增强生成(RAG)
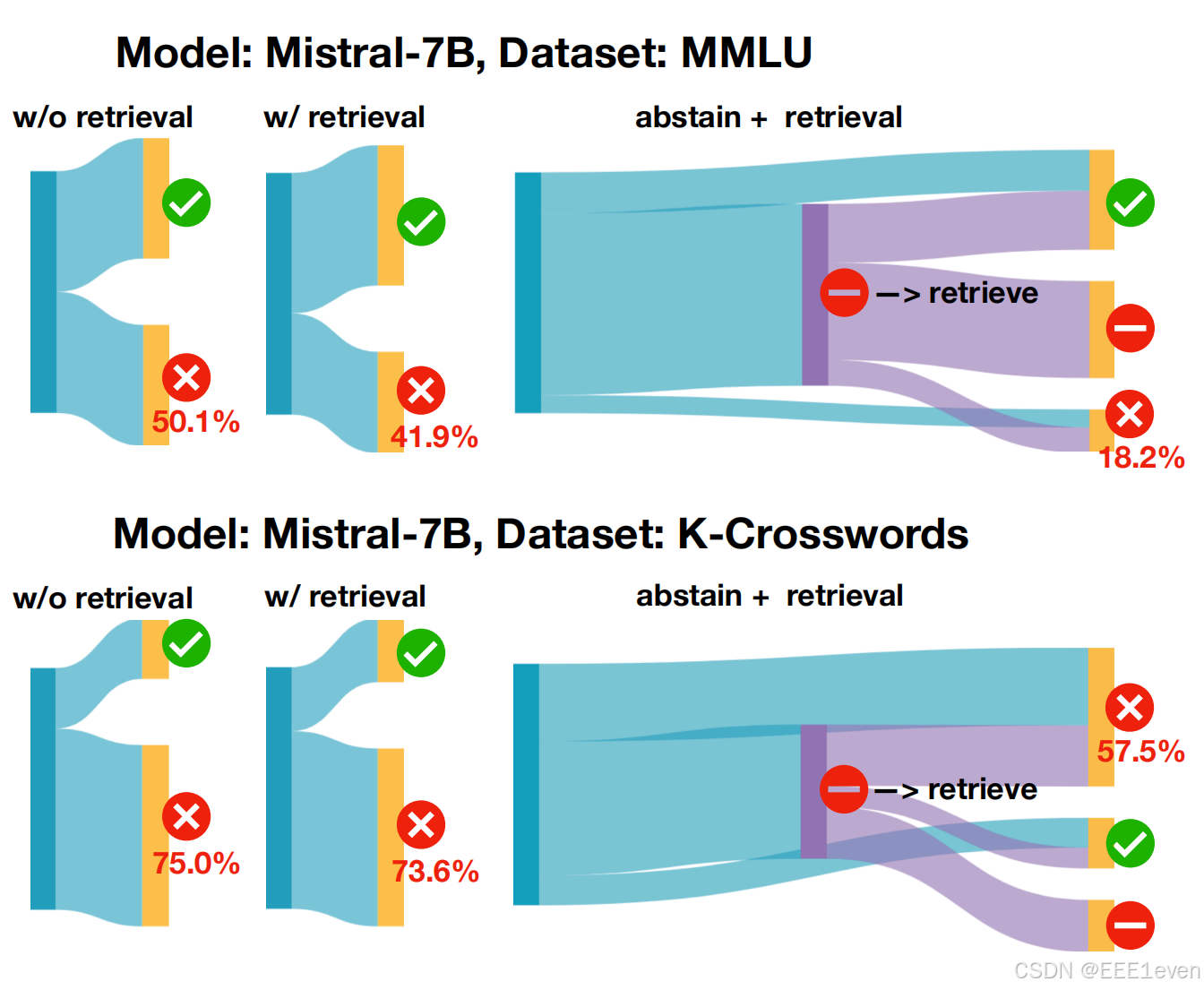
step1(图中蓝色部分): 在获取问题时,先不检索,让模型直接生,然后使用论文提出的方法来判断是否需要放弃。
step2(图中紫色部分): 如果放弃,则进行检索步骤,对搜索出来的答案再进行一次判断,确定是否需要放弃输出。
结果表明能降低 21.2% 的错误
多跳问题
思路: 论文尝试探索多跳问题中,在知识缺失时进行放弃,而不是出现幻觉
结果表明,至少能降低 82% 的错误率
总结与思考
- 通过该方法可以很大程度上减轻模型幻觉的出现,但是需要的算力很大(因为涉及到多个不同的LLM)
- 在检索增强和多跳问题中,遇到知识瓶颈、或是没有检索到相关知识时,选择放弃回答是一个解决思路,也能很好的降低幻觉输出的风险。
- 在进行训练时的数据增强的方式是一个值得深挖的过程,论文的方法也可以理解成一种数据增强的方式,通过结合不同LLM的输出,来提高数据不同维度的特征,帮助LLM更好的进行判断和推理。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











