







案例:手写数字识别案例
##########################################################################
1、导入框架
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
from sklearn.model_selection import train_test_split
from sklearn import svm2、获取数据
train = pd.read_csv("C:/Users/34248/Desktop/桌面文件/Jupyter/SVM/train.csv/train.csv")
train.head() 
导入数据后,数据为784个特征列+1个目标列组成的数据 ,每一行都代表一个数字,只不过将这一个数字写成了以行为单位的像素值的形式
3、拆分数据
train_image = train.iloc[:,1:]
train_label = train.loc[:,"label"]将数据拆分成特征数据和目标数据并储存在train_image和train_label中
1. 基于位置索引 - iloc
iloc 是基于整数位置的索引,它通过行和列的整数位置来选取数据。其使用形式为 DataFrame.iloc[row_indexer, column_indexer],其中 row_indexer 和 column_indexer 可以是整数、整数列表、切片对象等。
2. 基于标签索引 - loc
loc 是基于标签的索引,它使用行标签和列标签来选取数据。其使用形式同样为 DataFrame.loc[row_indexer, column_indexer],这里的 row_indexer 和 column_indexer 是标签值、标签列表、布尔数组等。
4、查看图像
num = train_image.loc[0,:].values.reshape(28,28)
plt.imshow(num)
plt.axis("off")
plt.show()
train_image.loc[0,:].value,取第一行数据并转换成numpy数组的形式,再重塑为 28x28 的二维数组,模拟图像的原始形状,并赋值给 num,之后用图像显示功能显示其图像
5、特征归一化
train_image.values
train_image = train_image.values/255
train_label = train_label.values数据中数值数量级差距比较大的时候,需要将数据做归一化处理,此处比较简单因为数据的上限都是255,所以直接除以255就可以了。
6、据集分割
x_train,x_test,y_train,y_test = train_test_split(train_image,train_label,test_size=0.2,random_state=0)7、数据降维和训练
定义函数,作用是对上数据进行降维并且训练数据,然后将训练准确率存储在accuracy变量中。
# 特征降维和模型训练
import time
from sklearn.decomposition import PCA
# 多次使用pca,确定最后的最优模型
def n_components_analysis(n,x_train,x_test,y_train,y_test):
# 记录开始时间
start = time.time()
# pca降维
pca = PCA(n_components = n)
print("特征降维,传递的参数为:{}".format(n))
pca.fit(x_train)
# 在训练集和测试集进行降维
x_train_pca = pca.transform(x_train)
x_test_pca = pca.transform(x_test)
# 利用svc进行训练
print("开始使用svc进行训练")
ss = svm.SVC()
ss.fit(x_train_pca,y_train)
# 获取accuracy结果
accuracy = ss.score(x_test_pca,y_test)
# 记录结束时间
end = time.time()
print("准确率是:{},消耗时间为:{}s".format(accuracy,int(end-start)))
return accuracy pca.fit(x_train)
x_train_pca = pca.transform(x_train)
x_test_pca = pca.transform(x_test)
此语句中,一定要先进行fit然后再transform转化,pca.fit可以看成是函数对x_train数据进行特征识别识别方差、标准差通过这些计算来识别出哪些特征是关键特征。识别好了之后再在下面语句中对现有的数据进行特征转化降维处理。这样可以保证所要降维的所有数据,都是基于上面识别之后的特征来进行降维的,数据特征具有一致性(不知道这么表述是否正确)。
8、n_components参数最优化
定义循环函数,多次执行上述定义好的n_components函数,将每次所得的accuracy值输入到列表中,程序一直执行到n取完了0.85之后就不再继续执行了。这时候accuracy中有5个准确率的值。
# 传递多个n_components,寻找合理的n_components:
n_s = np.linspace(0.70,0.85,num = 5)
accuracy = []
for n in n_s:
# 检查x_train和x_test的形状,如果是一维则重塑
if len(x_train.shape) == 1:
x_train = x_train.reshape(1, -1)
if len(x_test.shape) == 1:
x_test = x_test.reshape(1, -1)
tmp = n_components_analysis(n, x_train, x_test, y_train, y_test)
accuracy.append(tmp) if len(x_train.shape) == 1:
x_train = x_train.reshape(1, -1)
if len(x_test.shape) == 1:
x_test = x_test.reshape(1, -1)
此句是因为函数当中的pca.fit和svm都要求输入进去的数据是二维的,所以需要检查数据长度,如果是以为的就转化成二维数据在重新储存进原函数中。
-
reshape函数的基本原理- 在
numpy中,reshape函数用于改变数组的形状。它接受一个表示新形状的元组作为参数。对于x_train.reshape(1, -1),(1, -1)就是定义新形状的元组。 - 其中,第一个参数
1明确指定了新数组的第一维大小为1,这意味着新数组将只有一个样本(在机器学习数据的语境中,通常将数据的第一个维度视为样本维度)。 - 第二个参数
-1是一个特殊值。它告诉numpy根据原数组x_train的元素总数,自动计算这一维的大小。numpy会确保重塑后的数组元素总数与原数组相同。
- 在
-
示例说明
- 假设
x_train是一个一维numpy数组,包含 784 个元素,例如x_train = np.array([1, 2, 3, ..., 784]),其形状为(784,)。 - 当执行
x_train.reshape(1, -1)时,numpy会根据元素总数 784 和第一个维度为 1,计算出第二个维度的大小为 784(因为784÷1=784)。 - 所以重塑后的数组形状变为
(1, 784),即[[1, 2, 3, ..., 784]],从原来的一维数组转换为了二维数组,其中第一维表示样本数量(这里是 1 个样本),第二维表示每个样本的特征数量(这里是 784 个特征)。
- 假设
9、可视化准确率
# 准确率可视化
plt.plot(n_s,np.array(accuracy),"g")
plt.show()plt.plot传入的数据的格式都是numpy数组。
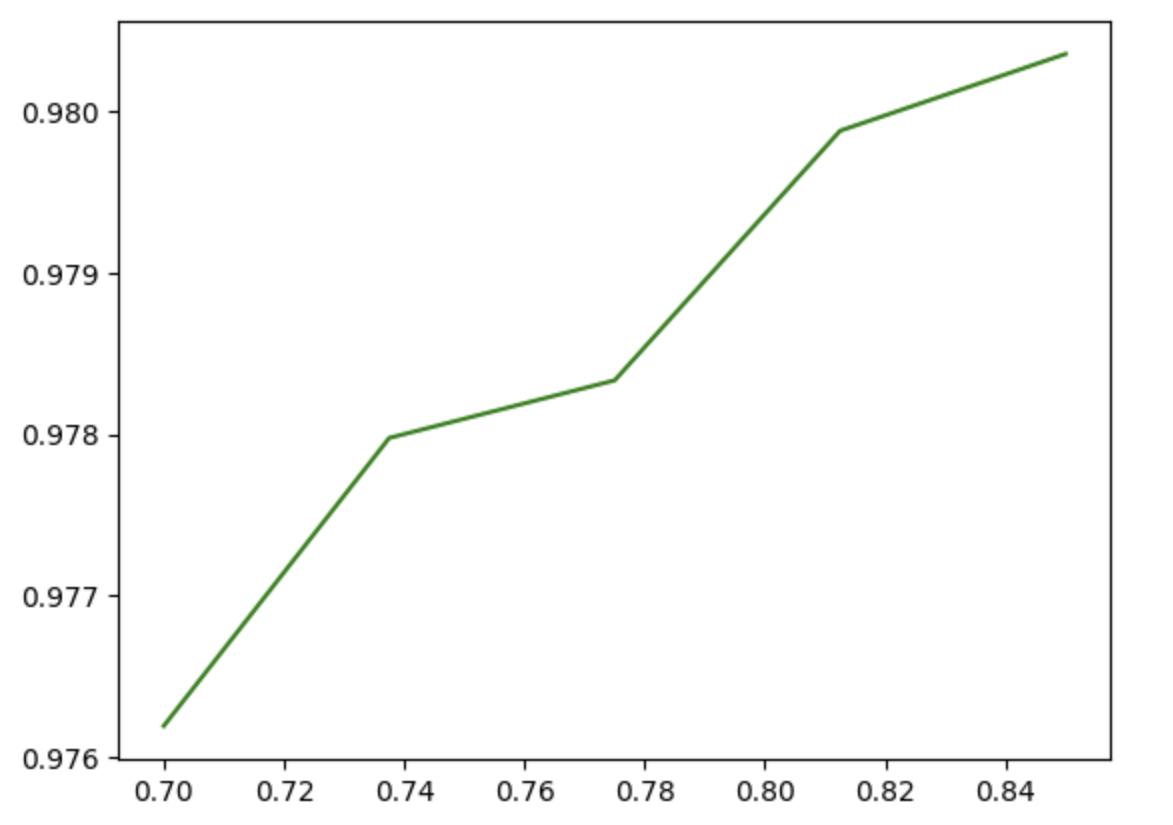
根据曲线确定最优的n_components值,但是不知道原则是什么,不是accuracy越高越好么?本案例取0.8
10、确定最优模型,并最终训练数据
因为最终选择参数为0.8,所以对数据最终训练,得到准确率为0.9785714。
# 确定最优模型,确定最终保留特征数量
pca = PCA(n_components=0.8)
pca.fit(x_test)
pca.n_components_
# np.int64(43)
x_train_pca = pca.transform(x_train)
x_test_pca = pca.transform(x_test)
x_train_pca.shape,x_test_pca.shape
# ((33600, 43), (8400, 43))
# 训练模型,计算accuracy
ssl = svm.SVC()
ssl.fit(x_train_pca,y_train)
ssl.score(x_test_pca,y_test)
# 0.978571428571428511、拓展测试
随机生成一个数字给模型进行预测,并输出结果:5
new_data = np.random.rand(28 * 28).reshape(1, -1)
# 数据归一化处理,与训练数据预处理一致
new_data = new_data / 255
# 使用 PCA 对新数据进行降维
new_data_pca = pca.transform(new_data)
# 使用 SVM 进行预测
prediction = ssl.predict(new_data_pca)
print(prediction)
# [5]

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









