







案例:用户评论情感分析案例
##########################################################################
1、导入数据库
1.1 导入数据库读取相关文件
import pandas as pd
data = pd.read_csv("C:/Users/34248/Desktop/桌面文件/Jupyter/Bayes/Comments.txt")
data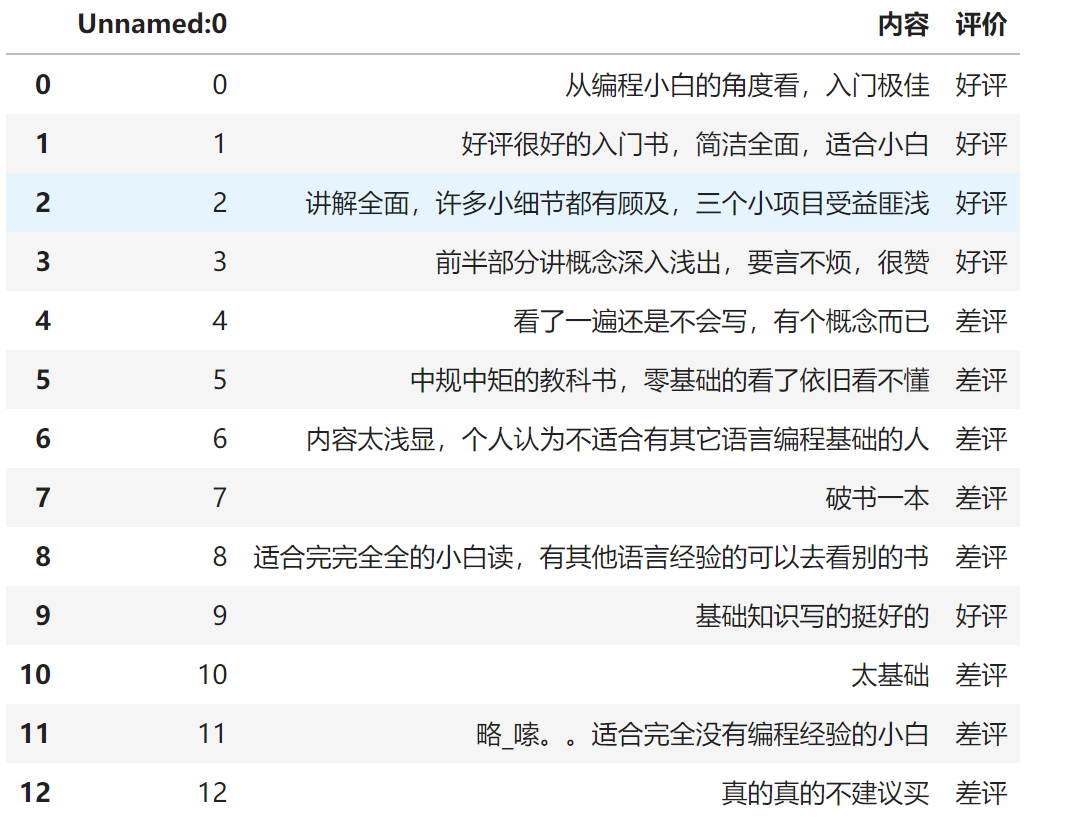
2、数据处理
2.1 数据读取与备用
# 读取data中标签为“内容”的列
content = data["内容"]
content
# 读取data中标签为“评价”的列,这里也可以跟上面读取内容一样直接用data["评价"]直接读取
data.loc[:, "评价"]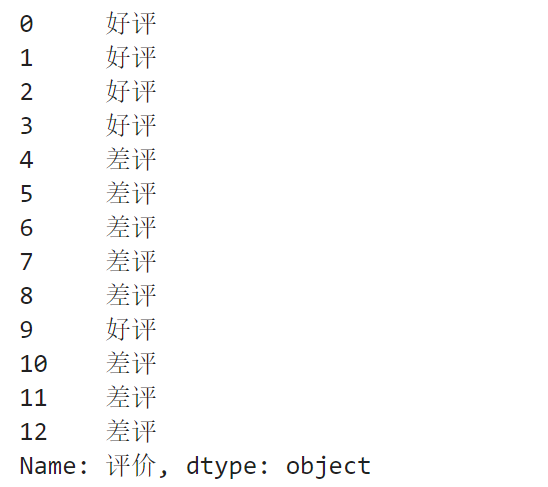
2.2 将评价列转换为0和1的形式
疑问点是这里转换了0和1,但是到最后并没有用到?
# 第一种方法:
data.loc[data.loc[:, "评价"] == "好评","评论编号"] = 1
data.loc[data.loc[:, "评价"] == "差评","评论编号"] = 0
# 第二种方法:可以用之前案例中的方法LabelEncoder
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
data['评论标号'] = le.fit_transform(data['评价'])
2.3 选择停用词
2.3.1 在网上下载停用词库
# 先建立一个空的stopword列表,然后在指定位置打开文件,然后把文件中的每一行内容当作一个元素存放在列表lines中
stopword = []
with open ("C:/Users/34248/Desktop/桌面文件/Jupyter/Bayes/停用词库.txt","r",encoding = "UTF-8") as f:
lines = f.readlines()
# 遍历列表,把列表中的每个元素前后空白元素去除,之后给到line,然后用append语句插入到stopword中
for tmp in lines:
line = tmp.strip()
stopword.append(line)# 先将stopword转化为set集,set集具有数据唯一性特点,然后再转化成list最后传回给stopword,这句的作用就是去重
stopword = list(set(stopword))到这里,停用词库就整理好了。以列表的形式储存在stopword中
2.4 将评论内容分词
comment_list = [] # 先建立空列表
import jieba # 导入jieba分词模块
for tep in content: #遍历content中的内容
seg_list = jieba.cut(tep,cut_all=False) #对每个元素内容进行分词
words_list = list(seg_list) #因为jieba.cut分词之后返回的 # 是generator类型,所以无法直接打#
#印查看,进行list转换然后储存在新列表words_list中
words_str = ",".join(words_list) # 用“,”连接word_list中的每个元素,然后放入一个新的字符串
comment_list.append(words_str) # append插入comment_list中,append后面的words_str必须是字#
# 符串类型,所以才有上面的操作comment_list 
到这里,评论内容就准备好了,是用逗号分割开的以content每行去重之后的内容为一个字符串的列表。
两个数据都准备好了,都是列表形式
2.5 特征提取
2.5.1 下面语句的作用应该是在上面comment_list中的词把stopword中涵盖的词挑出来,然后统计comment_list中,去除了stopword后的此出现的次数以形成的词频矩阵。具体应用可以参照结尾小例子
from sklearn.feature_extraction.text import CountVectorizer
con = CountVectorizer(stop_words = stopword)
X = con.fit_transform(comment_list)
X.toarray()con.get_feature_names_out()
3、训练和测试
3.1 准备训练集和测试集
x_train = X.toarray()[:10,:]
y_train = data['评价'][:10]
x_test = X.toarray()[10:,:]
y_test = data['评价'][10:] 3.2 机器学习
from sklearn.naive_bayes import MultinomialNB
mb = MultinomialNB(alpha=1)
mb.fit(x_train,y_train)
y_pre = mb.predict(x_test)
y_pre
# array(['差评', '差评', '差评'], dtype='<U2')print("预测值:",y_pre)
预测值: ['差评' '差评' '差评']print("真实值:",y_test)
真实值: 10 差评
11 差评
12 差评
Name: 评价, dtype: object3.3 评估模型准确性
mb.score(x_test,y_test)
1.0##########################################################################
CountVectorizer应用小例子
from sklearn.feature_extraction.text import CountVectorizer
# 定义文本数据
texts = ["apple banana", "banana cherry", "cherry date"]
# 创建CountVectorizer对象
vectorizer = CountVectorizer()
# 将文本数据转换为词频矩阵
X = vectorizer.fit_transform(texts)
# 获取特征名称(词汇表)
feature_names = vectorizer.get_feature_names_out()
# 打印词频矩阵和特征名称
print("词频矩阵:")
print(X.toarray())
print("特征名称(词汇表):")
print(feature_names)
词频矩阵:
[[1 1 0 0]
[0 1 1 0]
[0 0 1 1]]
特征名称(词汇表):
['apple' 'banana' 'cherry' 'date']
- 构建词汇表:运行上述代码,
CountVectorizer遍历texts中的所有文本,构建的词汇表为['apple', 'banana', 'cherry', 'date']。 - 统计词频:
- 对于第一个文本 “apple banana”,词频向量为
[1, 1, 0, 0],表示 “apple” 出现 1 次,“banana” 出现 1 次,“cherry” 和 “date” 未出现。 - 第二个文本 “banana cherry” 的词频向量是
[0, 1, 1, 0]。 - 第三个文本 “cherry date” 的词频向量为
[0, 0, 1, 1]。
- 对于第一个文本 “apple banana”,词频向量为
- 输出结果:
- 最终的词频矩阵
X.toarray()输出为: -
[[1 1 0 0] [0 1 1 0] [0 0 1 1]]
- 最终的词频矩阵

















 4185
4185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









