






本文以Dify为例介绍如何使用OpenSearch LLM智能问答版对接大模型应用开发平台构建RAG系统。
背景
随着AIGC技术日新月异的发展,LLM应用也在持续迭代。基于LLM、Agent框架、工作流编排能力等,可以搭建不同场景下丰富的应用服务。其中,检索增强生成(RAG)系统已经成为企业知识库、智能客服、电商导购等场景的核心环节。
OpenSearch LLM智能问答版内置数据解析与处理、切片、向量化、文本&向量检索、多模态LLM等模型和功能。本文将介绍如何使用OpenSearch LLM智能问答版对接大模型应用开发平台构建RAG系统。
大模型应用平台
在大模型行业中有越来越多的应用框架、开发平台,比如阿里云百炼、Dify等。开发者可以基于这些框架、平台快速搭建业务应用,RAG系统也是其中的常见环节。因此,大模型应用开发平台通常会内置RAG系统。
阿里云百炼:
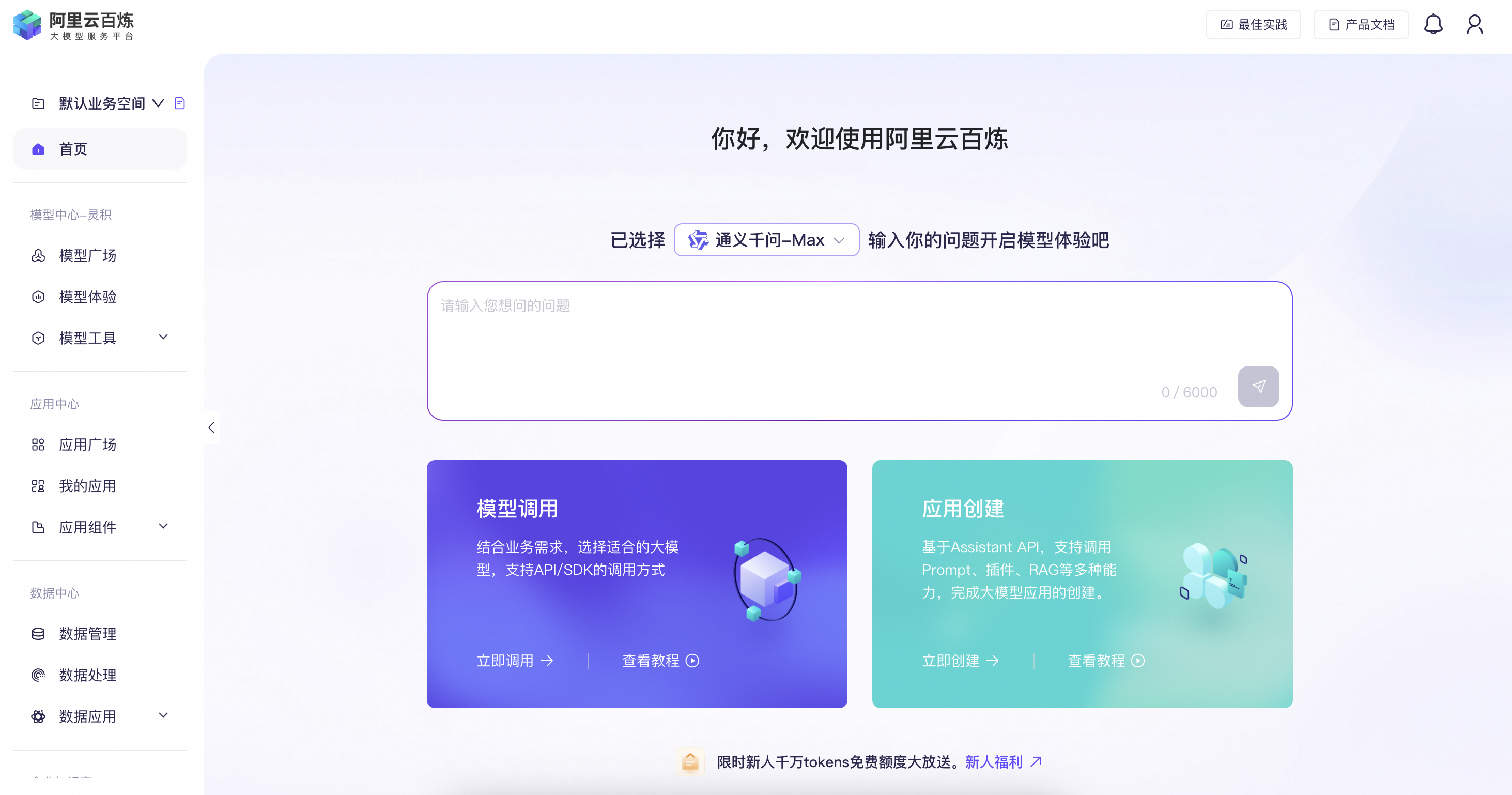
Dify:

然而,RAG系统的准确性与搜索效果息息相关,应用开发平台经常会面临以下问题:
1、易用性差:对知识库文档格式、数量、大小等有各种各样的限制,开发者需要进行复杂的数据预处理,或无法满足实际应用的需求。
2、专业性差:大多是黑盒系统,开发者难以针对核心链路进行定制化调优和扩展,导致整体应用效果差。
3、企业级能力弱:不支持企业级权限隔离、数据快速导入/更新等能力,难以落地到实际生产应用中。
针对上述问题,可以使用OpenSearch LLM智能问答版作为RAG系统,应用到工作流程中,快速搭建企业级应用。目前OpenSearch已支持对接百炼中的模型,从而丰富LLM选型,实现定制级RAG效果,具体使用方式可参考:LLM管理。
此外,OpenSearch支持丰富的调用、鉴权机制,灵活对接百炼、Dify等应用开发平台。
下面将以Dify为例,介绍对接开源应用平台的最佳实践。
整体架构
开发者预先将知识库导入OpenSearch,并用工作流处理后的对话请求访问OpenSearch中的RAG系统。OpenSearch会基于知识库、LLM,返回对话结果、参考链接、参考图片。开发者再根据业务需求,通过工作流处理结果,并最终输出给终端用户。

在OpenSearch LLM智能问答版中搭建RAG系统
1.搭建RAG系统
OpenSearch LLM智能问答版是一站式RAG产品,可分钟级搭建RAG系统,并可以在控制台进行可视化模型选择、Prompt定制、效果调优等。详情请参见通过控制台实现企业知识库问答。
2.创建并获取API Key
创建并获取公网API域名、API Key并妥善保存,详情请参见管理API Key。

在应用平台中搭建业务应用
Step 1:在大模型应用平台中创建工作流
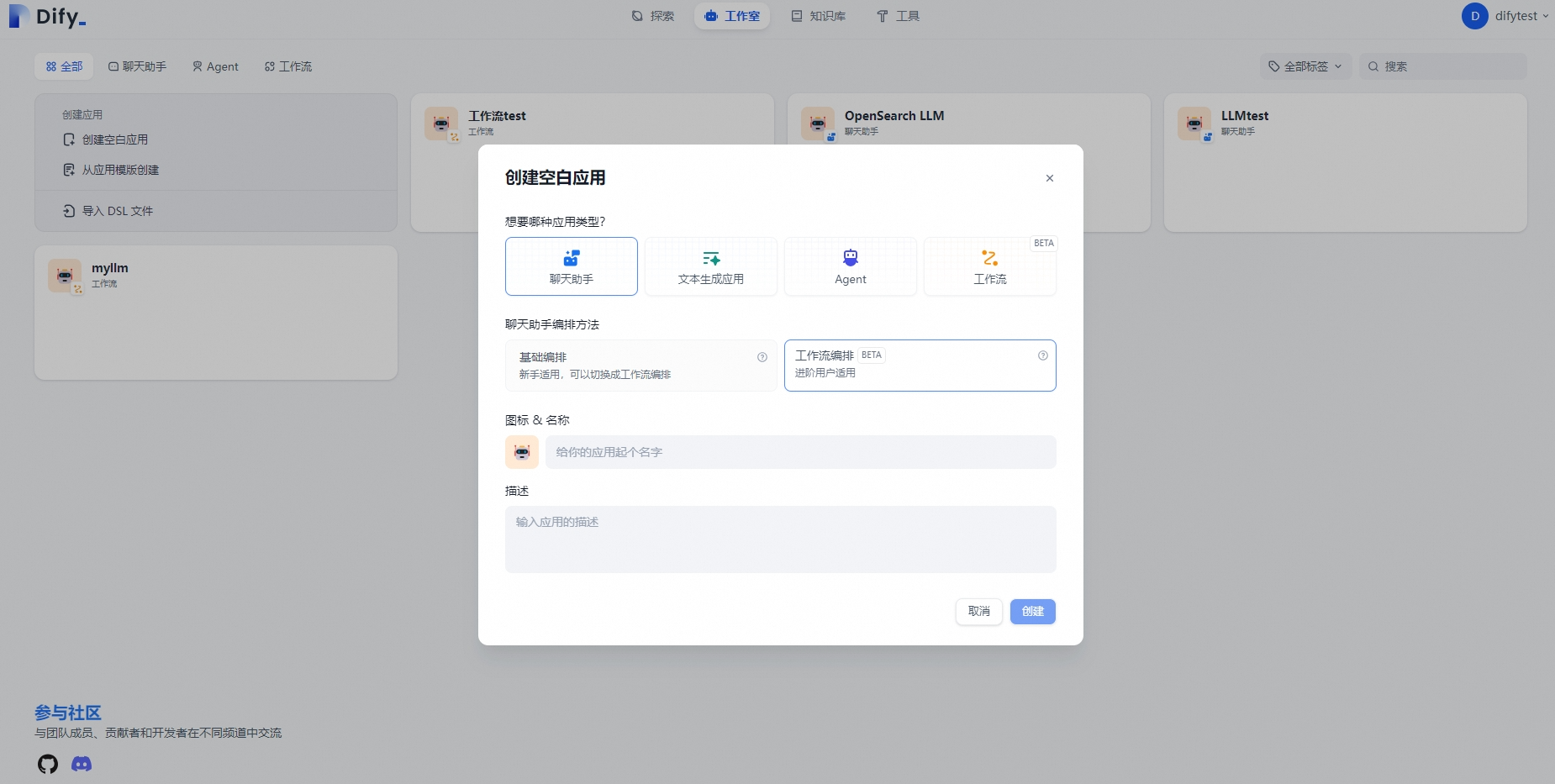

基础RAG工作流包含四个环节:
开始:获取用户输入的对话内容。
OpenSearch LLM智能问答版(HTTP请求):将对话内容输入OpenSearch,并基于RAG系统返回输出结果。
解析输出结果(代码执行):解析结果中的对话内容。
返回答案:向用户返回最终结果。
Step 2:使用HTTP请求访问OpenSearch RAG系统
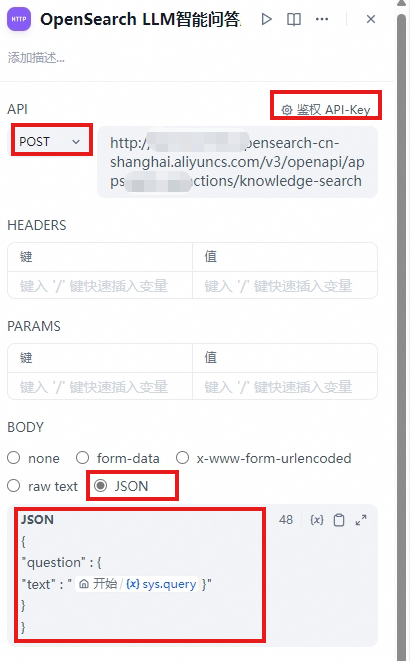
鉴权API-Key:
- 鉴权类型:API-Key
- API鉴权类型:Bearer
- API key:OpenSearch LLM智能问答版中获取的API Key。
URL地址:OpenSearch LLM智能问答版中获取的公网API域名 + OpenSearch接口地址(参考URL:v3/openapi/apps/[app_name]/actions/knowledge-search)
BODY:选择JSON格式,具体的内容和参数可参考:SearchKnowledge-问答文档查询。
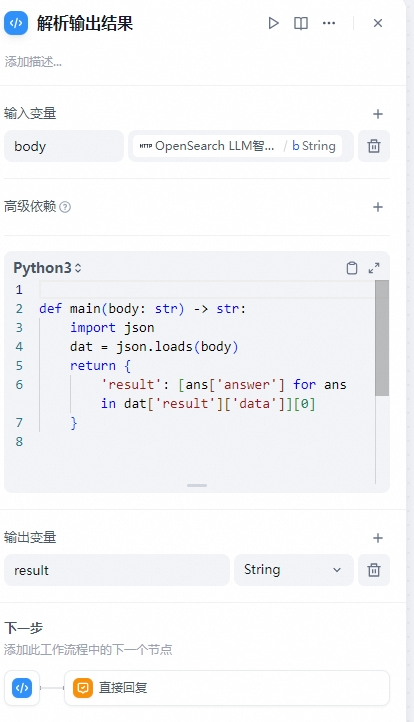
Step 3:解析输出结果
OpenSearch的接口返回结果为JSON格式,包含对话结果、参考链接、参考图片等。开发者可以使用代码执行解析输出结果,按需获取返回结果。
只获取输出结果的参考代码:
def main(body: str) -> str:
import json
dat = json.loads(body)
return {
'result': [ans['answer'] for ans in dat['result']['data']][0]
}
效果预览

在此基础上,可以配合搭建其他工作流,构建丰富的业务应用流。
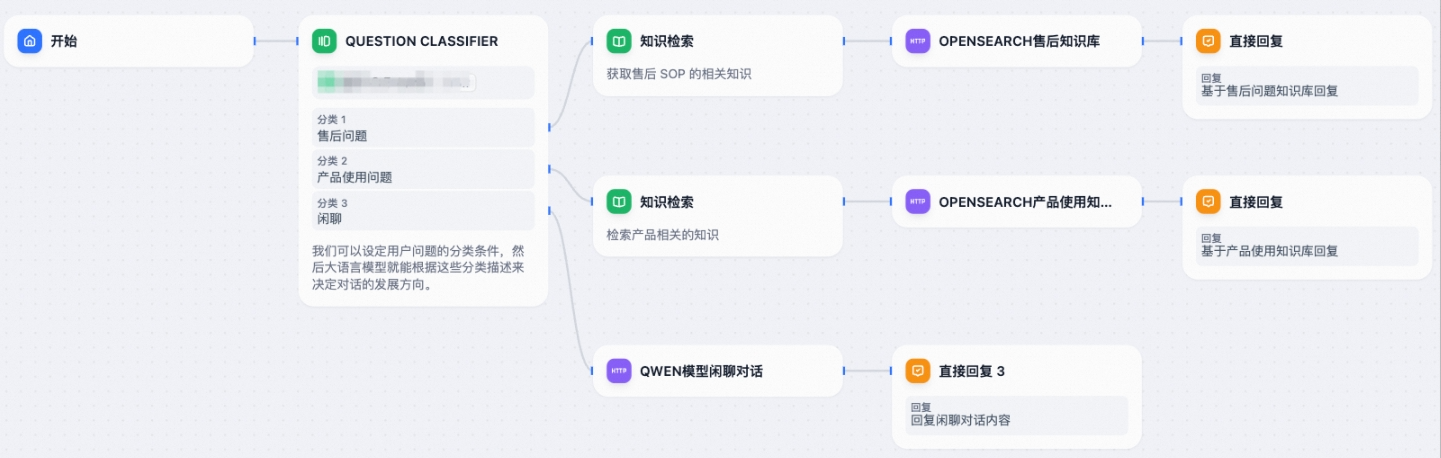
例如,以下是一个基于OpenSearch、Qwen模型构建的智能对话助手。
首先,会判断用户对话的意图并进行分类,分为售后问题、产品使用问题和闲聊。
针对售后问题、产品使用问题,分别访问OpenSearch中的相应知识库,使用RAG系统进行回复。
对于闲聊类问题,访问Qwen模型与用户进行闲聊对话,解决通用类问题。
除使用一站式RAG产品搭建工作流外,还可使用阿里云AI搜索开发工作台,通过工作台提供的文档解析、向量化、搜索、重排等原子化能力,自定义dify工具,从而快速定制优化RAG系统的各个环节。
- 了解OpenSearch LLM智能问答版详情,可参考:https://www.aliyun.com/activity/bigdata/opensearch/llmsearch
- 如有RAG系统相关问题,欢迎加入OpenSearch LLM智能问答版钉钉支持群,了解更多技术细节和使用详情。
- 钉钉群号:34895000837















 1696
1696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









