






装载工具概述
功能简介
DM提供了两种形式的快速装载工具:一是dmfldr;二是dmldrc和dmldrp。用户通过使用快速装载工具能够把按照一定格式排序的文本数据以简单、快速、高效的方式载入到 DM数据库中,或把DM数据库中的数据按照一定格式载出到文本文件中。
在软硬件资源充裕的情景下,选择dmfldr工具,部署在一台机器上可以独立完成快速装载任务,简单高效。
在机器资源匮乏的极端情景下,选择dmldrc和dmldrp工具,分别部署在两台机器上,各自占用较少的机器资源,相互配合共同完成快速装载任务。
其中,表及表的同义词支持数据载入和载出,视图及视图的同义词仅支持数据载出。
系统结构
1.dmfldr结构
dmfldr(DM Fast Loader)包含dmfldr客户端和dmfldr模块两部分。dmfldr客户端实现初始化快速装载环境、读取数据、打包数据和发送数据功能。dmfldr功能模块嵌入在数据库服务器中,实现装载功能。两者相互协作,共同完成dmfldr的各项功能。
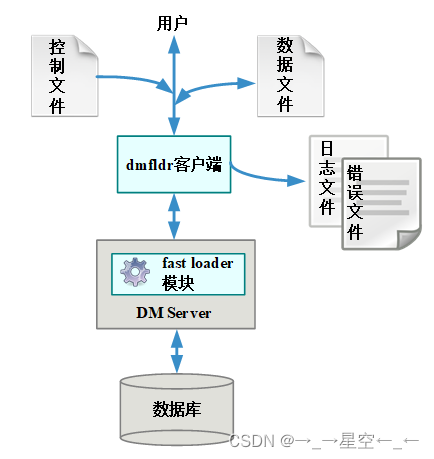
当进行数据载入时,dmfldr客户端接收用户提交的命令与参数,分析控制文件与数据文件,将数据打包发送给服务器端的dmfldr模块,由dmfldr模块完成数据的真正装载工作。并分析服务器返回的消息,必要时根据用户参数指定生成日志文件与错误数据文件。
当进行数据载出时,dmfldr客户端接收用户提交的命令与参数,分析控制文件,将用户要求转换成相应消息发送给服务器端的dmfldr模块。dmfldr模块解析并打包需要导出的数据,发送给dmfldr客户端,客户端将数据写入指定的数据文件,必要时根据用户参数指定生成日志文件。
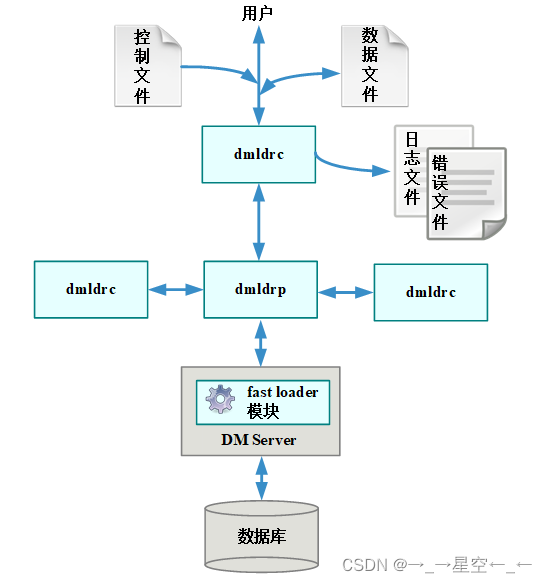
2.dmldrc和dmldrp结构
为了应对机器资源匮乏的情况,DM提供了一种轻量型的快速装载工具套装:dmldrc和dmldrp。
dmldrc为轻量级快速装载工具的客户端,负责初始化快速装载环境和数据处理功能;dmldrp为轻量级快速装载工具的服务器,负责任务处理和任务发送功能。两者相互配合完成和dmfldr客户端一样的功能。
dmldrc和dmldrp可部署在不同的机器上,将快速装载工具的任务分配到两个独立的工具上,并部署在不同的机器上,减轻机器的软硬件压力。
dmfldr参数
查看参数
命令:./dmfldr help
关键字 说明(默认值)
--------------------------------------------------------------------------------
USERID 用户名/口令, 格式:{<username>[/<password>] | /}[@<connect_identifier>][<option>] [<os_auth>]
<connect_identifier> : [<svc_name> | host[:port] | <unixsocket_file>]
<option> : #{<extend_option>=<value>[,<extend_option>=<value>]...}
--此行外层{}是为了封装参数之用,书写时需要保留
<os_auth> : AS {SYSDBA|SYSSSO|SYSAUDITOR|USERS|AUTO}
CONTROL 控制文件,字符串类型
LOG 日志文件,字符串类型 (fldr.log)
BADFILE 错误数据记录文件,字符串类型 (fldr.bad)
SKIP 初始忽略逻辑行数 (0)
LOAD 需要装载的行数 (ALL)
ROWS 提交频次 (50000), DIRECT为FALSE有效
DIRECT 是否使用快速方式装载 (TRUE)
SET_IDENTITY 是否插入自增列 (FALSE)
SORTED 数据是否已按照聚集索引排序 (FALSE)
INDEX_OPTION 索引选项 (1)
1 不刷新二级索引,数据按照索引先排序,装载完后再
将排序的数据插入索引
2 不刷新二级索引,数据装载完成后重建所有二级索引
3 刷新二级索引, 数据装载的同时将数据插入二级索引
ERRORS 允许的最大数据错误数 (100)
CHARACTER_CODE 字符编码,字符串类型 (GBK, UTF-8, SINGLE_BYTE, EUC-KR)
MODE 装载方式,字符串类型 IN表示载入,OUT表示载出,
OUTORA表示载出ORACLE (IN)
CLIENT_LOB 大字段目录是否在本地 (FALSE)
LOB_DIRECTORY 大字段数据文件存放目录
LOB_FILE_NAME 大字段数据文件名称,仅导出有效 (dmfldr.lob)
BUFFER_NODE_SIZE 读入文件缓冲区的大小 (10MB),有效值范围1~2048
LOG_SIZE 日志信息缓冲区的大小 (1MB),有效值范围1~100
READ_ROWS 工作线程一次最大处理的行数 (100000),最大支持2^26-10000
NULL_MODE 载入时NULL字符串是否处理为NULL
载出时空值是否处理为NULL字符串 (FALSE)
NULL_STR 载入时视为NULL值处理的字符串
SEND_NODE_NUMBER 运行时发送节点的个数 (20),有效值范围16~65535
TASK_THREAD_NUMBER 处理用户数据的线程数目,默认与处理器核数量相同,有效值范围1~128
BLDR_NUM 服务器BLDR数目 (64),有效值范围1~1024
BDTA_SIZE bdta的大小 (5000),有效值范围100~10000
COMPRESS_FLAG 是否压缩bdta (FALSE)
MPP_CLIENT MPP环境,是否本地分发 (TRUE)
SINGLE_FILE MPP/DPC环境,是否只生成单个数据文件(FALSE)
LAN_MODE MPP/DPC环境,是否以内网模式装载数据(FALSE)
UNREP_CHAR_MODE 非法字符处理选项(0),为0时表示跳过该数据行,为1时表示使用(*)替换错误字节
SILENT 是否静默方式装载数据(FALSE)
BLOB_TYPE BLOB类型字段数据值的实际类型,字符串类型 (HEX_CHAR)
HEX表示值为十六进制,HEX_CHAR表示值为十六进制字符类型
仅在direct=FALSE有效
OCI_DIRECTORY OCI动态库所在的目录
DATA 指定数据文件路径
ENABLE_CLASS_TYPE 允许用户导入CLASS类型数据 (FALSE)
FLUSH_FLAG 提交时是否立即刷盘 (FALSE)
IGNORE_BATCH_ERRORS 是否忽略错误数据继续导入 (FALSE)
SINGLE_HLDR_HP 是否使用单个HLDR装载HUGE水平分区表 (TRUE)
EP 指定需要发送数据的站点序号列表,仅向MPP/DPC环境导入数据时有效
PARALLEL 是否开启并行装载(FALSE)
SQL 使用自定义查询语句,仅导出模式有效
SQLFILE 自定义查询语句所在文件,仅导出模式有效
TABLE 导入/出表
ROW_SEPERATOR 行分隔符
FIELD_SEPERATOR 列分隔符
COMMIT_OPTION 提交选项(0), 0:每发送一批数据后提交, 1:发送完所有数据后提交
APPEND_OPTION 追加选项(0), 0: 追加方式, 1: 替代方式, 2: 插入方式
COLNAME_HEADING 是否在导出文件头中打印列名(FALSE)
IGNORE_AIMLESS_DATA 是否忽略无目标数据(FALSE)
LOB_AS_VARCHAR 是否将CLOB作为VARCHAR进行导入导出(FALSE)
LOB_AS_VARCHAR_SIZE 将CLOB作为VARCHAR进行导入导出时, lob数据最大大小(10MB)
LOG_LEVEL 记录错误数据信息级别(3), 0: 不记录 1: 只记录到log文件 2: 只记录到bad文件 3: 记录到log和bad文件 4: 错误仅输出到屏幕
FLDR_INI 配置文件路径,字符串类型
RECONN 自动重连次数(0)
RECONN_TIME 自动重连等待时间(5), 单位(s), 有效值范围(1~10000)
WIDTH 设置列数据宽度
SEDF 被替换的字符列表
SEDT 用于替换的字符列表
ESCAPE 转义符
DB2_MODE 兼容DB2模式
PRIORITY_ENCLOSE DB2模式下, enclose优先级最高
EXPORT_MODE MPP/DPC环境, 使用sql语句时的导出模式(0), 0: 普通模式 1: 快速模式 LOCAL方式连接
BAD_FILE_MODE 错误数据文件模式(0), 0: 普通模式 1: 纯数据模式
HELP 打印帮助信息
参数简介
1.USERID
USERID 用于指定数据库的连接信息。必选参数,且必须位于参数位置的第一个。
2.CONTROL
控制文件的路径,字符串类型。
控制文件用于指定数据文件的路径和数据格式。
3.LOG
dmfldr的日志文件路径,字符串类型。
默认日志文件名为fldr.log。
日志文件记录了dmfldr运行过程中的工作信息、错误信息以及统计信息。
4.NULL_STR
指定数据文件中NULL值的表示字符串,字符串类型,默认忽略此参数。
若设置了NULL_STR,则此参数值将成为数据文件中NULL值的唯一表示方式。
NULL_STR区分字符串大小写,并且长度不允许超过128个字节。
5.BADFILE
记录错误数据的文件路径,字符串类型。
默认的错误文件名为 fldr.bad。
文件记录的信息为数据文件中存在格式错误的行数据以及转换出错的行数据。
作用于 MODE 为 IN 的情况下,当 MODE 为 OUT 时无效。
6.SKIP
跳过数据文件起始的逻辑行数,整型数值。
默认的跳过起始行数为0行。
如果用户指定了多个文件,且起始文件中的行数不足SKIP所指定的行数,则dmfldr工具会扫描下一个文件直至累加的行数等于SKIP所设置的行数或者所有文件都已扫描结束。
SKIP参数在MPP和分布计算集群DPC环境下无效。若在MPP环境下使用本地连接,则SKIP参数仍有效。
7.LOAD
装载的最大行数,整型数值。
默认的最大装载行数为数据文件中的所有行数。
LOAD指定的值不包括SKIP指定的跳过的行数。
LOAD参数在MPP和分布计算集群DPC环境下无效。若在MPP环境下使用本地连接,则LOAD参数仍有效。
8.ROWS
每次提交的行数,整型数值。
默认的提交行数为50000行。
提交行数的值表示提交到服务器的行数,并不一定代表按照数据文件中的数据顺序的行数。用户可以根据实际情况调整每次提交的行数,以达到性能的最佳点。
作用于MODE为IN且DIRECT为FALSE的情况下,其他情况下无效。
9.DIRECT
数据装载方式,布尔值。
缺省为TRUE。
DIRECT为TRUE时,dmfldr选择快速的载入模式,通过数据的转换和数据的封装直接对B树进行操作,提升了装载的效率,但对于约束的检查等由用户保证,dmfldr将不处理有约束冲突的数据。
当为FALSE时,dmfldr选择普通的插入方式装载数据,可以保证数据的正确性和约束的有效性,效率比前者要低。
作用于MODE为IN的情况下,当MODE为OUT时无效。
10.SET_IDENTITY
设置自增列选项,布尔值。
缺省为 FALSE。
SET_IDENTITY值为TRUE,则dmfldr将把从数据文件中读取的自增列值作为目标值插入数据库表中,用户应当保证每一行的自增列的值符合自增列的规则。
SET_IDENTITY值为FALSE,则dmfldr将忽略数据文件中对应自增列的值,服务器将自动生成自增列的值插入每一行的对应列。
仅在MODE为IN、DIRECT为TRUE且非DMDPC环境下有效,DMDPC环境下暂不支持自增列装载。
11.SORTED
数据是否已经按照聚集索引排序,布尔值。
缺省为FALSE。
如果设置为TRUE,则用户必须保证数据已按照聚集索引排序完成,并且如果表中存在数据,需要插入的数据索引值要比表中数据的索引值大,服务器在做插入操作时顺序进行插入。
如果设置为FALSE,则服务器对于每条记录进行定位插入。
作用于MODE为IN且DIRECT为TRUE的情况下,对于其他情况此参数无效。
12.INDEX_OPTION
索引的设置选项,整型数值。
缺省为 1。
INDEX_OPTION 的可选项有 1、2 和 3。
1代表服务器装载数据时先不刷新二级索引,而是将新数据按照索引预先排序,在装载完成后,再将排好序的数据插入索引。
2代表服务器在快速装载过程中不刷新二级索引数据,只在装载完成时重建所有二级索引。
3代表服务器使用追加模式来进行二级索引的插入,在数据装载的过程中,同时进行二级索引的插入。若未禁用全局索引,则在非DPC环境下,全局索引可通过设置INDEX_OPTION为 3进行插入。
作用于MODE为IN且DIRECT为TRUE的情况下,对于其他情况此参数无效。
13.ERRORS
最大的容错个数,整型数值。
取值范围为 0~4294967295,缺省为 100。
当dmfldr在装载过程中出现错误的个数超过了ERRORS所设置的数目,则dmfldr将当前时间点已成功装载且未提交的所有正确数据提交到服务器,随后结束装载。
如果载入过程中不允许出现错误则可以设置ERRORS为0,如果允许所有的错误出现,则可以设置ERRORS为一个非常大的数。
ERRORS 所统计的错误包含在数据转换和数据插入过程中所产生的数据错误。
作用于 MODE 为 IN 的情况下,当 MODE 为 OUT 时无效。
14.CHARACTER_CODE
数据文件中数据的编码格式,字符串类型。
默认与当前机器编码格式一致。
CHARACTER_CODE 的可选项有五种:
GBK 和 GB18030 对应中文编码;
UTF-8 对应 UTF-8 国际编码;
SINGLE_BYTE 对应单字节字符编码;
EUC-KR 对应韩文字符集。
在MODE为IN的情况下,指定编码格式为SINGLE_BYTE时,dmfldr将不做字符完整性检查,按单字节顺序读取每个字符。
指定编码格式为GBK、GB18030或UTF-8时,dmfldr将对每一个字符做字符的完整性检查,确保数据的正确性。
用户在使用dmfldr时可以根据不同的数据文件调整编码的格式确保装载的正确性,同时如果可以确保数据文件中的数据为单字节字符,则指定SINGLE_BYTE的载入效率将优于指定其他字符集。
当MODE为非IN时,不支持SINGLE_BYTE。
15.MODE
dmfldr的装载模式,字符串类型。缺省值为IN。MODE的可选项有IN、OUT、OUTORA和 LOCAL_FILE四种。
IN模式指从数据文件中将数据装载入数据库,这种模式下控制文件的格式对应为数据文件中现有数据的格式;
OUT模式指从数据库中将数据导出到数据文件,这种模式下控制文件所指定的格式为数据存放在数据文件中的格式。
在 OUT 模式下,如果指定了多个数据文件,则 dmfldr 最终只会将数据写入第一个数据文件。
OUT模式下的控制文件与IN模式下的控制文件格式相同,用户可以通过使用同一个文件进行载入和导出数据。
OUTORA模式表示导出ORACLE表的数据,此模式下暂不支持带有大字段表的导出。
LOCAL_FLIE表示数据导入时,不向服务器发送数据,而是将数据写入成本地文件。通常用于多站点场景下,将数据按站点分类重新组织数据。
16.CLIENT_LOB
指明 LOB_DIRECTORY 表示的目录是否是客户端本地目录,布尔类型,缺省值为 FALSE。
CLIENT_LOB仅在MODE为IN且DIRECT为TRUE时有效,指明在载入大字段对象数据时,LOB_DIRECTORY参数指定的目录是否是客户端本地目录。
若为 TRUE,表示目录为客户端本地目录,且此时待载入的大字段长度不得超过 2G,否则无法成功载入大字段;
若为 FALSE,表示目录为 DM 服务器所在主库的目录。
17.LOB_DIRECTORY
指明 dmfldr 使用的大字段数据存放的目录,字符串类型。
当MODE为OUT时,dmfldr生成大字段对应的数据文件,文件名由LOB_FILE_NAME指定,并存放于LOB_DIRECTORY指定的目录,如果未指定LOB_DIRECTORY则存放于指定的导出数据文件同一目录。
对于 MODE 为 OUT 的情况,此参数为可选参数。
当 MODE 为 IN 且 DIRECT 为 TRUE 时,此时数据载入若涉及到大字段对象,需要用户指定大字段数据文件。
若 CLIENT_LOB 为 TRUE,LOB_DIRECTORY 应指定大字段数据文件所在的客户端本地目录;若 CLIENT_LOB 为 FALSE,用户必须先把相关文件传送到 DM 服务器所在主库,然后使用 LOB_DIRECTORY 指明存放目录。此时此参数为必选参数。
当 MODE 为 IN 且 DIRECT 为 FALSE 时,此参数无效。
18.LOB_FILE_NAME
指明 dmfldr 导出大字段数据的文件名,字符串类型,缺省为dmfldr.lob。
当 MODE 为 OUT 时,dmfldr 生成大字段对应的数据文件名由LOB_FILE_NAME指定,
若未指定默认为 dmfldr.lob,文件存放于LOB_DIRECTORY指定的目录。
作用于 MODE 为 OUT 的情况下,当 MODE 为 IN 时无效。
19.BLOB_TYPE
指定 BLOB 数据值的实际类型,字符串类型。
可选项为HEX表示值为十六进制,HEX_CHAR表示值为十六进制字符,默认为HEX_CHAR。
只在 DIRECT 参数为 FALSE 的情况下有效。
注意:
不支持使用包含BLOB列的表生成的导出数据文件在导入时指定BLOB_TYPE为HEX_CHAR。
20.BUFFER_NODE_SIZE
指定读取文件缓冲区页大小,整数类型,单位为MB,取值范围为1~2048,缺省为10。
BUFFER_NODE_SIZE的值越大,缓冲区的页越大,每次读取的数据就越多,每次发送到服务器的数据也就越多,效率越高。
其大小受dmfldr客户端内存大小限制。
21.LOG_SIZE
指定日志系统中缓冲区结点的大小,整数类型,单位为MB,取值范围为1~100,缺省为1。
在装载过程中产生的错误数据和错误描述信息,将首先写入到日志系统的缓冲区结点中,缓冲区写满后,将缓冲区中的错误数据刷盘到错误数据文件中,并将缓冲区中的错误描述信息刷盘到日志文件中。
若错误数据或错误描述信息的大小超过缓冲区结点的大小,则系统直接将该错误数据或错误描述信息刷盘到错误数据文件或日志文件中。
22.READ_ROWS
指定读取缓冲区每次读取的最大行数,整数类型,取值范围为 0~(2^26-10000),缺省为 100000。
在某些情况下,1MB的BUFFER_NODE_SIZE读入的数据行数很大,而后续操作处理不了这么大的行数,此时可以用READ_ROWS来限制处理的行数。
dmfldr取READ_ROWS 和 BUFFER_NODE_SIZE 中较小的值作为一次处理的行数。
23.NULL_MODE
指定载入和导出数据时对 NULL 字符串和空值的处理方式,布尔类型,缺省为 FALSE。
若NULL_MODE为TRUE,数据载入时将NULL字符串处理为空值,数据导出时则空值处理为NULL字符串;
若设置为FALSE,数据载入时将NULL字符串处理为字符串,数据导出时将空值处理为空串。
24.SEND_NODE_NUMBER
指定dmfldr在数据载入时发送节点的个数,整数类型,取值范围为16~65535,默认有20个数据节点。
只在 MODE 为 IN 的情况下有效。
25.TASK_THREAD_NUMBER
指定dmfldr在数据载入时处理用户数据的线程数目,整数类型,取值范围为1~128。
默认情况下,dmfldr将该参数值设为系统CPU的个数,但无论设定值是多少,dmfldr至少会创建2个任务线程。
在多核CPU环境下,增大TASK_THREAD_NUMBER值可以提升dmfldr装载性能。
注意:
在导出模式下,当TASK_THREAD_NUMBER设置为大于16而小于128时,dmfldr不会报错,但会将TASK_THREAD_NUMBER自动置为16。
26.BLDR_NUM
水平分区表装载时,指定服务器 BLDR 的最大个数,整数类型,取值范围为 1~1024,缺省为64。
服务器的BLDR保存水平分区子表相关信息,BLDR_NUM的设置也就指定了服务器能同时载入的水平分区子表的个数。
作用于 MODE 为 IN 的情况下,当 MODE 为 OUT 时无效。
27.BDTA_SIZE
BDTA(Batch DaTA)的大小,整数类型,取值范围为100~10000,缺省为5000。
BDTA代表DM数据库批量数据处理机制中一个批量,在内存、CPU允许的条件下,增大 BDTA_SIZE能加快装载速度;在网络是装载性能瓶颈时,增大BDTA_SIZE影响不大。
作用于 MODE 为 IN 的情况下,当 MODE 为 OUT 时无效。
28.COMPRESS_FLAG
指定是否压缩 BDTA,布尔类型,缺省为 FALSE。
压缩 BDTA 能节省网络带宽,但同时也会加重 CPU 的负担。
29.MPP_CLIENT
指定当服务器环境为MPP环境时dmfldr的数据装载模式,布尔类型,缺省为TRUE。
当服务器环境为MPP环境时,若MPP_CLIENT为TRUE,为客户端分发模式,数据在dmfldr客户端分发好后直接往指定站点发送数据;
若MPP_CLIENT为FALSE,为本地分发模式,dmfldr 客户端将数据全部发往连接的 MPP EP 站点。
MPP 环境下要配置 dmmal.ini 文件中的 MAL_INST_HOST和MAL_INST_PORT参数。
此参数只有当服务器环境为 MPP 环境时才有效。
30.SINGLE_FILE
指定当服务器环境为MPP/DPC环境时,dmfldr的导出数据文件是否为单个文件,布尔类型,缺省为FALSE。
此参数只在MPP/DPC环境下且MODE为OUT 时有效。
参数值为TRUE表示仅生成一个数据导出文件,MPP/DPC各个站点的数据将导出到同一个数据文件;
值为FALSE表示可以生成多个数据文件,每一个MPP/DPC站点都有专门的数据文件接收该站点的数据。
31.LAN_MODE
指定当服务器环境为MPP/DPC 环境时,dmfldr 导入/导出数据是否使用局域网,布尔类型,缺省为FALSE。
此参数只在MPP/DPC环境下有效。
值为 TRUE 表示使用局域网,此时服务器的 MAL 系统必须配置了局域网 IP,否则 dmfldr 依然采用服务器对外服务的外网 IP;
值为 FALSE 表示不使用局域网。
32.UNREP_CHAR_MODE
指定是否将不完整的字符用“*”替换。1 是,0 否,缺省为 0。
设置为1时,dmfldr 装载过程中遇到包含不完整字符的数据时,将用"*"替换不完整的字符;为 0 时,该行数据可能会被丢弃。
33.SILENT
指定是否以静默方式进行数据装载,布尔类型,缺省 FALSE。
当设置为TRUE时,dmfldr装载过程中将忽略反馈式的消息,例如装载进度提示信息、错误信息等,但仍然会在装载的开始和结束阶段打印一些静态/统计信息。
静默方式只作于客户端的屏幕打印,dmfldr日志依然会完整地记录装载过程中的详细信息。
34.OCI_DIRECTORY
指定 ORACLE OCI 动态库所在的目录,字符串类型。
该参数与MODE参数配合使用,当MODE指定为OUTORA时,使用OCI_DIRECTORY 指定OCI 的动态库来构建导出环境。
35.DATA
指定数据文件路径,字符串类型。
一般情况下数据文件路径在控制文件中指定。
如果控制文件缺省或控制文件中数据文件路径指定为‘*’,那么会使用命令行或dmfldr.ini配置文件中DATA参数指定的数据文件。
优先使用命令行中指定的 DATA 参数指定的数据文件。
36.ENABLE_CLASS_TYPE
指定是否以 BLOB 方式载入或导出 CLASS 类型列数据,布尔类型,缺省为 FALSE。
CLASS 类型是 DM 数据库服务器内部实现的数据类型,实际以 BLOB 类型存储。
如果通过交互式工具或 DM 提供的接口等正常途径创建的 CLASS 类型数据,内部会转换成 BLOB 存储。
通过 dmfldr 直接导 CLASS 数据,没有进行转换,有可能出现载入的大对象数据无法转换成对应的 CLASS 类型。
因此,当将 ENAME_CLASS_TYPE 设为 TRUE 时,用户要保证对应的 BLOB 数据能正确转换成对应的 CLASS 类型。
37.FLUSH_FLAG
指定提交数据时服务器的处理方式,布尔类型,缺省为 FALSE。
该参数用于dmfldr向服务器发送commit请求时,是否要求服务器提供可靠的服务响应,
若设置为 TRUE,则服务器会等数据写入磁盘后才将响应结果返回给 dmfldr,此种方式会降低数据装载的效率,但提供可靠的服务,不存在数据丢失的情况;
若为 FALSE,则服务器在确认数据正确无误后便将响应结果返回,随后再写入磁盘,此种方式装载效率高,但若遇到掉电、机器故障、服务器崩溃等灾难性情况下,有可能会导致数据来不及写入磁盘而导致数据丢失。
作用于MODE为IN 的情况下,当MODE为OUT时无效。
38.SINGLE_HLDR_HP
是否使用单个 HLDR 装载 HUGE 水平分区表主表。取值 TRUE 或 FALSE,缺省值为 FALSE。TRUE 表示使用单个 HLDR 装载 HUGE 水平分区表主表。
FALSE 表示装载涉及到的每个叶子子表都各使用一个HLDR。
HLDR 是服务器端装载 HUGE 表时用到的处理装置。
SINGLE_HLDR_HP的设置相当于指定了服务器装载HUGE水平分区主表时可以使用资源的模式。
TRUE 的方式更节约空间,FALSE 的方式装载速度更快。
39.IGNORE_BATCH_ERRORS
指定用户在数据装载过程中遇到数据错误时,是否忽略错误继续装载,还是报错返回,布尔类型,缺省为 FALSE。
该参数只在 DIRECT 为 FALSE 时有效。
在普通数据装载方式下,以绑定插入的方式向服务器发送数据,服务器检查 IGNORE_BATCH_ERRORS参数,为TRUE时,将处理所有接受到的数据,如果有不合要求的数据,服务器保存该数据的错误信息,直到当前批次所有数据处理完毕后,再将执行的结果返回 dmfldr,dmfldr 根据服务器返回的错误信息向错误数据文件写入错误数据。
当 IGNORE_BATCH_ERRORS 参数值为 FALSE 时,服务器一旦遇到不合要求的数据,则终止当前批次数据的装载,向 dmfldr 返回错误信息,dmfldr 则直接废弃当前批次的所有数据。
作用于 MODE 为 IN 且 DIRECT 为 FALSE 的情况下,当 MODE 为 OUT 时无效。
40.EP
指定 dmfldr 只能向指定的 MPP/DPC 站点发送数据,对于其他站点的数据直接丢弃。EP 站点序号用整型数字表示,各站点间用逗号分隔,整个EP参数值用括号括起来。
该参数仅在 MPP/DPC 环境有效,dmfldr只能向EP指定的站点上的表上锁并发送数据,其他站点的表操作与其无关。
需要注意的是,客户端 A 连接 EP1,客户端 B 连接 EP2,那么 EP1 的表数据只能有 A 来发送,不能由 B 发送,否则会导致锁等待或锁超时错误。
在 MODE 为 IN 且 direct 为 TRUE 的情况下有效。
41.PARALLEL
dmfldr 向服务器导入数据时,是否开启并行模式。
开启并行参数后,可以运行多个用户同时向同一张表装载数据,此模式可以充分利用客户端的数据处理能力,服务器接收到各个客户端发送过来的数据后,再进行统一的数据处理和刷盘。
若存在以下情况,并行参数不可开启:
装载表存在二级索引;
装载表存在自定义的聚集索引;
装载表开启了逻辑日志或者高级日志;
装载表为列存储表(HUGE 表)。
在 MODE 为 IN 且 direct 为 TRUE 的情况下有效。
42.SQL
用户指定 SQL 查询语句,用于导出自定义查询结果数据,在 MODE 为 OUT的情况下有效。
自定义 SQL 查询语句会将 SQL 语句发送到服务器进行分析执行,若发现 SQL 语句不是查询语句,dmfldr 将报错返回。
SQL 语句可以实现用户的个性化数据导出需要,可以选择需要导出的列,需要过滤的结果。
SQL 查询语句需要使用双引号括起来。
43.SQLFILE
用户指定 SQL 查询语句所在文件路径,用于导出自定义查询结果数据,在 MODE 为 OUT的情况下有效。
当 SQL 查询语句过长时,用户可以将 SQL 查询语句写入文件中,然后使用 SQLFILE 参数指定 SQL 查询语句所在文件路径。
44.TABLE
指定导入或导出表的表名,可以包含模式名。
若导出时指定SQL或SQLFILE参数,则该选项失效。
45.ROW_SEPERATOR
指定行分隔符,分隔符额外指定 X 表示十六进制的分隔符,长度应小于 128。
46.FIELD_SEPERATOR
指定列分隔符,分隔符额外指定 X 表示十六进制的分隔符,长度应小于 255。
47.COMMIT_OPTION
提交选项。
取值:0 表示每发送一批数据进行提交;1表示数据全部装载完毕后进行提交。默认为0。导入时有效。
48.APPEND_OPTION
dmfldr 的追加模式。
取值:0表示APPEND追加方式;1表示REPLACE替代方式;2表示INSERT插入方式。缺省为 0。
当dmfldr处于数据装载模式时:
APPEND追加方式,在表中追加新记录;
REPLACE 替代方式,先清空表再插入新记录;
INSERT 插入方式,向空表插入新记录(如果不是空表则会报错无效的装载模式)。
当 dmfldr 处于导出数据模式时:
APPEND追加方式,若数据文件已存在则以追加的方式写入数据,否则直接创建新文件。REPLACE替代方式,若数据文件已存在则先删除文件再重新创建新文件,否则直接创建新文件;
INSERT插入方式, 直接创建新文件,若数据文件已存在则报错创建文件失败,否则直接创建新文件成功。
如果导出数据含有大字段数据,且未指定 LOB_AS_VARCHAR=TRUE,则新创建的数据文件会包含普通数据文件(由 DATA 指定名称)和大字段数据文件(由LOB_FILE_NAME指定名称,缺省为dmfldr.lob);如果不包含大字段数据,则导出文件只有普通数据文件。
49.COLNAME_HEADING
是否在导出文件头中打印列名。取值 TRUE 或 FALSE,缺省值为 FALSE。
TRUE 表示在导出文件头中打印列名,列名之间使用列分隔符进行分隔,列名与数据之间使用行分隔符进行分隔。
导出时有效。
50.IGNORE_AIMLESS_DATA
是否忽略无目标数据。取值 TRUE 或 FALSE,缺省值为 FALSE。
TRUE 表示在导入数据时忽略无目标数据,即未找到对应分区的分区表数据,该错误不影响其他数据的导入,相关错误个数不会计入 ERRORS,并且不会显示相关错误信息,导入结束后用户可通过提交总数、读取逻辑记录总数、拒绝逻辑记录总数以及跳过逻辑记录总数的差值来获取忽略的无目标数据的总数。
导入时有效。
51.LOB_AS_VARCHAR
是否将CLOB作为VARCHAR进行导入导出。取值 TRUE 或 FALSE,缺省值为 FALSE。
TRUE表示进行数据导入导出时将CLOB类型数据作为VARCHAR类型数据处理,此时CLOB类型数据内容为实际数据内容。
52.LOB_AS_VARCHAR_SIZE
指定将CLOB作为VARCHAR进行导入导出时,支持的LOB数据的最大大小,整数类型,单位为MB,范围为1~20,缺省为10。
仅在 LOB_AS_VARCHAR 为TRUE时有效。
53.LOG_LEVEL
指定记录错误数据信息的级别,可取值 0、1、2、3、4,缺省为 3。
0:不记录错误信息和错误数据;
1:仅记录错误信息;
2:仅记录错误数据;
3:记录错误信息和错误数据;
4:仅将错误输出到屏幕,不记录到文件中。
其中,错误信息指错误原因等信息,记录在日志文件(.lob 文件)中;错误数据指因为格式或数据本身错误而导致导入导出失败的数据,记录在错误文件(.bad 文件)中。
54.FLDR_INI
指定 dmfldr.ini 配置文件路径,字符串类型。用户可在dmfldr.ini文件中指定除USERID、CONTROL、HELP以外的所有dmfldr参数值。
未指定该参数时,默认在当前目录下查找dmfldr.ini配置文件。
文件中每个参数值对之间使用空格或者换行分隔。
dmfldr.ini 配置文件中指定 SQL 参数时,对于 SQL 语句中出现的单引号需要使用单引号括起来。
55.RECONN
指定自动重连次数,范围为 0~4294967295。缺省为 0,表示不进行自动重连。
在服务器未启动时,该参数在 COMMIT_OPTION=1 时可以正常生效,当 COMMIT_OPTION=0 时,该参数可能不生效。
在数据导入过程中,如果出现可恢复的环境错误(如主备切换、故障重启等)或网络错误(如网络超时、连接断开重连等)等问题,dmfldr 根据 RECONN 参数进行指定次数的自动重连处理,若自动重连成功,则 dmfldr 继续执行数据导入任务,若重连失败,则 dmfldr 根据 COMMIT_OPTION 采取相应的处理策略:若 COMMIT_OPTION=0,则未提交数据全部回滚;若 COMMIT_OPTION=1,则所有数据全部回滚。
仅在 MODE 为 IN 的情况下有效。
56.RECONN_TIME
指定自动重连等待时间,单位为 S,取值范围为 1~10000,缺省为 5。
当数据导入过程中出现可恢复的环境错误或网络错误等问题时,若 RECONN 不为 0,则 dmfldr 每间隔 RECONN_TIME 时间进行下一次自动重连。
仅在 MODE 为 IN、RECONN 不为 0 的情况下有效。
57.WIDTH
指定导出列的数据宽度,单位为字节,取值范围为 1~65535。不足指定宽度时填充空格,超出指定宽度时进行截断。未指定该参数时,导出列按实际长度导出。
不同列的指定宽度之间使用“:”进行分隔。若WIDTH指定的列个数少于实际导出列个数,则最后几列视为未设置WIDTH,其导出列按实际数据长度导出。
仅在MODE为OUT的情况下有效。
58.SEDF
指定被替换的字符列表,以单个字符为单位进行替换,“0x”开头表示十六进制格式,系统自动将其转换为 ASCII 字符。
与参数 SEDT 一同使用。
59.SEDT
指定用于替换的字符列表,以单个字符为单位进行替换,“0x”开头表示十六进制格式,系统自动将其转换为 ASCII 字符。
将参数 SEDF 指定的字符列表逐个替换为 SEDT 指定的字符列表,参数 SEDF 和 SEDT 指定的字符个数必须相同。
与参数 SEDF 一同使用。
60.ESCAPE
指定转义符,“0x”开头表示十六进制格式,系统自动将其转换为 ASCII 字符。仅支持指定一个转义符。
导出数据时,对于指定转义符会输出两个相邻的指定转义符;导入数据时,若存在两个相邻的指定转义符,则仅输入一个指定转义符。
61.DB2_MODE
DB2 兼容模式,布尔值,缺省为 FALSE。开启后,支持功能:
- 字符串列封闭符默认为",全局封闭符只针对字符串列生效;
- 大字段导入导出文件的数据文件格式更换为:filename.nnn.mmm/,其中 filename 是大字段文件名,nnn 是文件偏移(取值范围 0BIGINT),mmm 是大字段长度(取值范围 0BIGINT);
- 支持PRIORITY_ENCLOSE参数;
- 数据没有封闭,则被认为是空值,存在封闭符但没有数据,则认为是空串。
62. PRIORITY_ENCLOSE
DB2 兼容模式下封闭符优先级是否高于行分隔符,布尔值,缺省为 FALSE。
需要开启 DB2 兼容模式后才生效,生效后,数据文件中的封闭符优先级高于行分隔符。
仅当开启 DB2_MODE 时生效。
63.EXPORT_MODE
MPP/DPC 导出模式,可取值 0、1,缺省为 0。
在使用 SQL 参数进行数据导出时,
0:使用普通模式,数据通过一个 GLOBAL 连接获取;
1:使用快速模式,数据通过多个 LOCAL 连接从各个节点获取。
快速模式不支持 SQL 结果集包含多表数据,不支持 SQL 为非表的查询语句;
快速模式因为是通过多个 LOCAL 连接从各节点获取数据,因此当涉及跨节点数据的连接等查询语句时,数据可能缺失,此类情况不建议使用。
64.BAD_FILE_MODE
错误数据文件 BADFILE 的模式。取值 0 或 1,缺省为 0。
0: 普通模式,错误数据文件中包含文件头、数据头和数据等;
1: 纯数据模式,错误数据文件中只包含数据内容。
当 BAD_FILE_MODE=1 时,默认 bad 文件名为“数据文件名.bad”。
对于多表装载,还会为 bad 文件增加编号,编号顺序为控制文件中该数据文件对应表格的顺序。
65.HELP
获取帮助信息。
dmfldr实战
dmfldr 控制文件
控制文件 CONTROL 是启动 dmfldr 必须要指定的参数,用于指定数据文件中数据的格式。在数据载入时,dmfldr 根据控制文件指定的格式来解析数据文件;
导出数据时,dmfldr 也会根据控制文件指定的列分隔符、行分隔符等生成数据文件。
dmfldr 控制文件的语法如下所示:
[OPTIONS(
<id>=<value>
……
)]
LOAD [DATA]
INFILE < <file_option>|<directory_option> >
[BADFILE <path_name>]
[APPEND|REPLACE|INSERT]
<into_table_clause>
<id> ::=参数
<value> ::=值
<file_option> ::= [LIST] <path_name> [<row_term_option>] [,<path_name>
[<row_term_option>]]
<directory_option> ::= DIRECTORY <path_name> [<row_term_option>]
<path_name> ::=文件地址
<row_term_option> ::=STR [X] <delimiter>
<into_table_clause> ::= <into_table_single>{<into_table_single>}
<into_table_single> ::=INTO TABLE [<schema>.]<tablename>
[EP <ep_option>]
[WHEN <field_conditions>]
[FIELDS [TERMINATED BY] [X] <delimiter>]
[<enclosed_option>]
[TRAILING NULLCOLS]
[<coldef_option>]
<schema> ::=模式名
<tablename> ::=表名
<ep_option> ::=(<ep_list>)
<ep_list> ::=整型数字列表,以逗号分隔
<field_conditions> ::= <field_condition>{ AND <field_condition>}
<field_condition> ::= [(] <cmp_exp><cmp_ops><cmp_data>[)]
<cmp_exp> ::= <colid> | (p1:p2)
<cmp_ops> ::= = | <> | !=
<cmp_data> ::= [X] '<字符串常量>' | BLANKS | WHITESPACE
<delimiter> ::= '<字符串常量>'
<coldef_option> ::= (<col_def>{ ,<col_def>})
<col_def> ::= <col_id> [FILLER][<property_option>][<dtype_option>][<fmt_option>][<term_option>][<enclosed_option>][<constant_option>][<fun_option>]
<col_id> ::= 列名
<property_option> ::= <position_option> | NULL
<position_option> ::= position(p1:p2) | position(p1) | position(*)
<dtype_option> ::= DATE | CHAR
<fmt_option> ::= FORMAT '<日期格式>'
<term_option> ::= TERMINATED [BY] <wx_option>
<wx_option> ::= WHITESPACE|[X] <delimiter>
<enclosed_option> ::= [OPTIONALLY] ENCLOSE [BY] [X] <delimiter>
<constant_option> ::= CONSTANT "<常量>"
<fun_option> ::= "<函数>"
指定数据文件
指定数据文件的方式有三种:
- 在控制文件中指定;
- 通过命令行参数 DATA 直接指定;
- 使用dmfldr.ini指定。使用其中一种方式指定即可。
当 dmfldr 工作在 IN 模式时,从数据文件中读取数据并载入数据库;
当工作在 OUT 模式时,从数据库中将指定数据导出到数据文件。
数据文件通常为文本文件,列与列之间由列分隔符隔开,行与行之间由行分隔符隔开。
数据文件中的列分隔符和行分隔符由用户指定,并在控制文件中设置为与数据文件中的一致。
1.在控制文件中指定数据文件
可以在控制文件的 LOAD 节点中指定数据文件
2.使用 DATA 参数指定数据文件
可以使用 DATA 参数指定 dmfldr 的数据文件。
用户可以在命令行中直接指定 DATA 参数,也可以在 dmfldr.ini 配置文件中指定 DATA 参数。如果控制文件中数据文件路径指定为‘**’*,那么会使用命令行或 dmfldr.ini 配置文件中指定的 DATA 参数来替换‘*’,优先使用命令行中指定的 DATA 参数进行替换。
数据转换与错误数据文件
dmfldr 使用的数据文件都是文本格式的,其中的列值都是以字符串的方式保存在数据文件中。要想将这些数据载入数据库表中,需要将字符串转换成数据库表各列对应的数据类型。dmfldr 支持所有 DM 数据库支持的列定义类型,包括字符串、数值、时间日期、时间日期间隔、大字段类型等。
若数据文件的编码方式与 DM 数据库服务器的编码方式不一样,dmfldr 还需要进行字符编码的转换。dmfldr 支持 UTF-8、GBK 和 GB18030 编码之间的相互转换。
数据类型和编码转换工作由 dmfldr 客户端进行,在这个过程中如果出现错误,dmfldr 会跳过该行继续后面的工作,并记录错误行到 BADFILE 指定的文件。常见的出错的情况有以下几种:
- 编码转换失败
- 目标列为字符串类型时,数据长度大于列定义长度
- 目标列为数值类型时,数据包含非法字符或者转换后超出该数值的范围
- 目标列为日期类型时,dmfldr 默认按 yyyy-mm-dd hh:mi:ss 的格式解析,如果数据不是这样的格式,需要指定对应列的时间日期 fmt 格式
dmfldr 错误数据的文件路径由 BADFILE 参数设置,默认的错误文件名为 fldr.bad。用户也可以通过设置控制文件中的 OPTIONS 选项来指定错误数据文件的路径,同时也可以在控制文件的 LOAD 节点中指定错误数据文件的路径。
错误数据文件路径最终值的优先选择顺序为命令行中指定的参数值,控制文件的 LOAD 节点选项,控制文件的 OPTIONS 选项,dmfldr.ini 配置文件中指定的参数值,用户可以同时对四种设置方式中的一个或多个设置,但最终的值只取一个。BADFILE 仅作用于 dmfldr 的工作 MODE 为 IN 的情况下,MODE 为 OUT 时无效。
当数据类型和编码转换中存在错误数据,而错误数在允许的最大错误数范围内时,dmfldr 会将出错的数据记录到错误数据文件中。文件记录的信息为执行程序、时间、目标表、数据文件中存在格式错误的行数据以及转换出错的行数据。
允许的最大容错个数由 ERRORS 选项设置,取值范围为 [0,4294967295] 之间的整数,默认为 100。当 dmfldr 客户端在数据类型和编码转换过程中出现的错误个数超过了 ERRORS 所设置的数目,dmfldr 会停止载入,当前时间点的所有正确数据将会被提交到服务器端。如果载入过程中不允许出现错误则可以将 ERRORS 设置为 0;如果允许所有的错误出现,则可以将 ERRORS 设置为一个非常大的数。
服务器端错误数据处理
dmfldr 客户端将载入的数据进行数据转换和编码转换后,将转换正确的数据发往 DM 服务器的 dmfldr 模块,也就是 dmfldr 的服务器端,由其进行真正的数据载入工作。
dmfldr 客户端每次向服务器端发送一批数据,在服务器端插入数据的过程中,由于目的表上可能存在约束等原因,导致某些数据无法插入成功,此时服务器端会将这一批数据全部回滚,并将这批数据全部记为错误数据,但服务器端插入时的错误数据并不会记录到 BADFILE 中。
ERRORS 所统计的错误包含在数据转换和数据插入过程中所产生的数据错误,因此当服务器端插入数据记录的错误数据数加上客户端数据转换时的错误数据数超过 ERRORS 参数的指定值时,dmfldr 服务器会停止插入数据。
大字段数据处理
dmfldr支持对DM数据库的大字段类型数据的载入和导出,DM数据库支持的大字段数据类型有TEXT、LONGVARCHAR、IMAGE、LONGVARBINARY、BLOB以及CLOB。
1.大字段数据的导出
当 dmfldr 工作在导出模式即MODE为OUT时,dmfldr生成大字段对应的数据文件名由LOB_FILE_NAME指定,若未指定默认为dmfldr.lob,文件存放于LOB_DIRECTORY指定的目录,如果未指定LOB_DIRECTORY则存放于指定的导出数据文件同一目录。
2.DIRECT 为 TRUE 时大字段数据的载入
当MODE为IN且DIRECT为TRUE时,此时数据载入若涉及到大字段对象,需要用户指定大字段数据文件。若CLIENT_LOB为TRUE,LOB_DIRECTORY应指定大字段数据文件所在的客户端本地目录,且此时待载入的大字段长度不得超过2G,否则无法成功载入大字段;若 CLIENT_LOB为FALSE,用户必须先把相关文件传送到DM服务器所在主库,然后使用 LOB_DIRECTORY指明存放目录。
大字段数据文件在数据文件中指定,可以是任意格式的文件。在数据文件中,大字段以“文件名:起始偏移:长度”的形式记录在数据文件中。指定的文件名无效时,dmfldr会报错,装载失败。对于CLOB类型字段,当指定的偏移、长度范围内带有不完整字符时,dmfldr将装载失败。
3.DIRECT 为 FALSE 时大字段数据的载入
当MODE为IN且DIRECT为FALSE时,数据文件中大字段列数据即字段内容。此时,大字段数据长度不允许超过32KB。BLOB_TYPE 参数指定 BLOB 列内容为十六进制或者字符串:
BLOB_TYPE 为 HEX_CHAR 时,数据文件中 BLOB 列当作为十六进制内容;
BLOB_TYPE 为 HEX 时,数据文件中 BLOB 列为字符串形式内容,导入后会转换为十六进制。
BLOB_TYPE 参数只对 DIRECT 为 FALSE 时有效,默认为 HEX_CHAR。
注意
不支持使用包含BLOB列的表生成的导出数据文件在导入时指定BLOB_TYPE为HEX_CHAR。
日志文件及日志信息
dmfldr 的日志文件路径由 LOG 参数设置,默认日志文件名为 fldr.log。文件记录了装载过程中的装载信息和错误信息以及统计信息。用户也可以通过设置控制文件中的 OPTIONS 选项来指定日志路径。如果参数及 OPTION 中同时指定了日志路径则其将以 OPTION 中指定的路径为最终路径。
自增列装载
自增列是比较特殊的列,为了保证数据库中自增列列值的正确性,用户在进行数据载入时需要特别注意。
当DIRECT参数为FALSE时,dmfldr将把从数据文件中读取的自增列值作为目标值插入数据库表中,用户应当保证每一行的自增列的值符合自增列的规则,否则将造成数据混乱。
当DIRECT参数为TRUE时,dmfldr提供了SET_IDENTITY参数(缺省为 FALSE)对数据载入时自增列的处理进行设置:
如果指定 SET_IDENTITY 选项值为 TRUE,则 dmfldr 将把从数据文件中读取的自增列值作为目标值插入数据库表中,用户应当保证每一行的自增列的值符合自增列的规则,否则将造成数据混乱;
如果 SET_IDENTITY 选项值设置为 FALSE,则 dmfldr 将忽略数据文件中对应自增列的值,服务器将根据自增列定义和表中已有数据自动生成自增列的值插入每一行的对应列。
DMDPC 环境下暂不支持自增列装载。
数据排序
SORTED 参数用来设置数据是否已经按照聚集索引排序,缺省为 FALSE。
如果设置为 TRUE,则用户必须保证数据已按照聚集索引排序完成,并且如果表中存在数据,需要插入的数据索引值要比表中数据的索引值大,服务器在做插入操作时顺序进行插入。若数据并未按照索引排序,则 dmfldr 会报错,装载失败。对于存在分区表的情况,当数据未按照索引排序时,使用 dmfldr 向分区表进行装载,可能能够成功装载全部数据;也可能仅能成功装载部分数据或装载失败,此时 dmfldr 会报错;成功装载入子表的数据排序正确。
如果设置为 FALSE,则服务器对于每条记录进行定位插入。
此参数仅在 MODE 为IN且DIRECT为TRUE的情况下有效。
在数据量大,并且确定数据已按照聚集索引排序完成的情况下,将SORTED参数设置为TRUE,可以提升装载性能。
空值处理
dmfldr通过设置NULL_MODE参数来处理空值。
设置为TRUE,载入时NULL字符串处理为NULL,载出时空值处理为NULL字符串
设置为FALSE,载入时NULL字符串处理为字符串,载出时空值处理为空串
类类型装载
dmfldr 支持对 CLASS 类型数据的装载。
CLASS类型装载和LOB类型一样,载入时需要指定LOB_DIRECTORY,另外需要指定 ENABLE_CLASS_TYPE为TRUE;
导出时,默认导出目录和数据文件所在目录一致,导出类类型形成的大字段文件默认为 dmfldr.lob,导出目录和大字段文件可通过LOB_DIRECTORY和LOB_FILE_NAME参数设置。
条件过滤
通过在控制文件中指定 WHEN<field_conditions>子句,可以在装载过程中对数据进行过滤,符合 field_conditions 条件的数据才会被装载。
对于条件过滤的使用需注意以下几点:
判断条件中的操作符仅支持比较相等和不相等,即=、!=和<>这三个比较操作符;
目前仅支持使用AND连接多个过滤条件;
BLANKS 和 WHITESPACE 表示若干个空格;
判断条件若使用(p1:p2)作为比较表达式,其意义与在 POSTION 子句中的意义相同,表示从该行指定位置获取数据进行比较,起始位置和结束位置表示的都是字节位置,包含边界 p1,p2;
如果判断条件中使用colid作为比较表达式,该列必须在 INTO 表的 coldef_option 中进行说明;
如果判断条件中使用colid作为比较表达式,判断条件中使用的列仅用于过滤,并没有对应表中的某个实际列,应在 col_def中指明FILLER属性表示装载时跳过该列;
如果判断条件中比较数据是字符常量值,其长度小于比较表达式长度,则在其之后补充空格;如果判断条件中比较数据是二进制串常量,其长度小于比较表达式长度,则在之后补充0。
多表装载
通过在控制文件中指定多个 INTO TABLE 子句,可以将一批数据同时向多个表进行装载。每个 INTO TABLE 子句中都可以指定 WHEN 过滤条件、FIELDS 子句和列定义子句。
对于多表装载的使用需注意以下几点:
每个 INTO TABLE 子句的目标表必须是不同的表;
多表装载时不支持直接装载分区表子表;
对于第二个及其之后的INTO TABLE子句,在其coldef_option中,必须为第一列指定POSITION 选项;
个性化设置
用户通过设置 dmfldr 的 SKIP、LOAD、ROWS 参数,可以根据自己的需求调整装载的起始行、装载最大行数以及每次提交的行数。
SKIP 参数用来设置跳过数据文件起始的逻辑行数,整型数值。默认的跳过起始行数为 0 行。如果用户指定了多个文件,且起始文件中的行数不足 SKIP 所指定的行数,则 dmfldr 工具会扫描下一个文件直至累加的行数等于 SKIP 所设置的行数或者所有文件都已扫描结束。
LOAD 参数用来设置装载的最大行数,整型数值。默认的最大装载行数为数据文件中的所有行数。LOAD 指定的值不包括 SKIP 指定的跳过的行数。
ROWS 参数用来设置每次提交的行数,整型数值。默认的提交行数为 50000 行。提交行数的值表示提交到服务器的行数,并不一定代表按照数据文件中的数据顺序的行数。用户可以根据实际情况调整每次提交的行数,以达到性能的最佳点。ROWS 参数作用于 MODE 为 IN 的情况下,当 MODE 为 OUT 时无效。
主备切换时的数据继续载入
在DM数据守护主备环境下,如果 dmfldr 数据载入中发生主备切换,dmfldr支持主备切换完成后自动继续装载数据,并且能保持数据正确。
要使用此项功能,USERID参数需要使用主备服务名方式进行配置,例如:
dmfldr USERID=SYSDBA/SYSDBA@dw CONTROL='c:\fldr.ctl'
同时在dm_svc.conf配置文件中配置主备服务名,例如:dw=(192.168.0.101:5236, 192.168.0.102:5236)
目前主备切换时的数据继续载入功能还存在以下功能限制:
目前仅支持单机的主备,不支持MPP主备。但是,若在MPP主备环境中使用 MPP_CLIENT=FALSE,等同于单机,也是支持的。
目前不支持分区表装载。
MPP本地分发
MPP_CLIENT参数用来设置在DM MPP环境下使用dmfldr进行数据装载时的数据分发方式。
当DM数据库服务器环境为单站点时此参数无效。当服务器环境为MPP环境时,若 MPP_CLIENT为TRUE,dmfldr 采用客户端分发模式;若MPP_CLIENT为FALSE,则采用本地分发模式。
客户端分发模式下,数据在dmfldr客户端分发好后直接往指定站点发送数据。
本地分发模式下,导入时,dmfldr直接将数据发送到连接的站点,数据最终在连接的站点;导出时,dmfldr只导出连接站点的数据。
MPP 环境下要配置dmmal.ini文件中的MAL_INST_HOST和MAL_INST_PORT参数。
提升dmfldr性能
用户在使用 dmfldr 时根据系统和数据的具体情况对一些参数进行调整,可以获得更好的性能,这些参数包括:
1.BUFFER_NODE_SIZE
BUFFER_NODE_SIZE设置读取文件缓冲区页大小,值越大,缓冲区的页越大,每次读取的数据就越多,每次发送到服务器的数据也就越多,效率越高。但其大小受dmfldr客户端内存大小限制。
2.READ_ROWS
在某些情况下,BUFFER_NODE_SIZE读入的数据行数很大,而后续操作处理不了这么大的行数,此时可以用READ_ROWS来限制处理的行数。dmfldr 取READ_ROWS和 BUFFER_NODE_SIZE中较小的值作为一次处理的行数。
3.SEND_NODE_NUMBER
指定 dmfldr 在数据载入时发送节点的个数,默认由系统计算一个初始值。若在数据载入时发现发送节点不够用,系统会动态增加分配。在系统内存足够的情况下,可以适当设大 SEND_NODE_NUMBER值,提升 dmfldr 载入性能。
4.TASK_THREAD_NUMBER
指定 dmfldr 在数据载入时处理用户数据的线程数目。默认情况下,dmfldr 将该参数值设为系统 CPU 的个数,但当 CPU 个数大于 8 时,默认值都被置为 8。在 dmfldr 客户端所在机器 CPU 大于 8 环境中,提高 TASK_THREAD_NUMBER 值可以提升 dmfldr 装载性能。
5.BLDR_NUM
水平分区表装载时,指定服务器 BLDR 的最大个数,缺省为 64。
服务器的 BLDR 保存水平分区子表相关信息,BLDR_NUM 的设置也就指定了服务器能同时载入的水平分区子表的个数。若 BLDR_NUM 设置太大,当水平分区子表数过多时,可能会导致服务器内存不足。当载入时实际需要的 BLDR 个数超出 BLDR_NUM 设置时,会淘汰指定子表的 BLDR,并替换为新的子表 BLDR。
6.BDTA_SIZE
BDTA(Batch Data)的大小,缺省为 5000。
BDTA 代表 DM 数据库批量数据处理机制中一个批量,在内存、CPU 允许的条件下,增大 BDTA_SIZE 能加快装载速度;在网络是装载性能瓶颈时,增大 BDTA_SIZE 影响不大。
7.INDEX_OPTION
索引的设置选项,缺省为1。INDEX_OPTION 的可选项有1、2和3。
1代表服务器装载数据时先不刷新二级索引,而是将新数据按照索引预先排序,在装载完成后,再将排好序的数据插入索引。如果在数据载入前,目标表中已有较多数据,建议 INDEX_OPTION 置为1。
2代表服务器在快速装载过程中不刷新二级索引数据,只在装载完成时重建所有二级索引。如果在数据载入前,目标表中没有数据或数据量较小,建议 INDEX_OPTION 置为2。
3代表服务器使用追加模式来进行二级索引的插入,在数据装载的过程中,同时进行二级索引的插入,若未禁用全局索引,则在非 DPC 环境下,全局索引可通过设置 INDEX_OPTION为3进行插入。当原有数据量远大于插入数据量时,建议 INDEX_OPTION 置为3。
dmfldr 使用限制
dmfldr 的使用存在以下一些限制:
- 不支持向临时表、外部表装载数据
- 不支持向系统表装载数据
- 不支持向带有位图索引的表装载数据
- 不支持向带有函数索引的表装载数据
- 不支持向带有全文索引的表装载数据
- 不支持向 DCP 代理装载数据
- 不支持在 DPC 环境下,向带有全局索引的表装载数据
- dmfldr 装载时会对约束进行检查,对各种约束的处理机制如下表所示;由于 dmfldr 不处理约束的有效性,都视为有效,故需要用户自行处理约束有效性等相关内容
| 约束 | 数据不满足时 | 数据插入与否 | 约束是否有效 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|















 3688
3688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









