






阿里云前几天的故障详细报告出来了,跟很多网友猜的差不多,但也有很多细节不一样,我们一起来分析一下。
之前很多网友分析是阿里云的鉴权系统出了问题(阿里的故障报告中叫做AK系统)。这份故障报告很详细地介绍了,保护AK系统免受“无效AK ID攻击”的白名单过滤机制出了问题,系统收到了一份不完整的错误白名单,直接把一些正常访问请求给拒绝了。
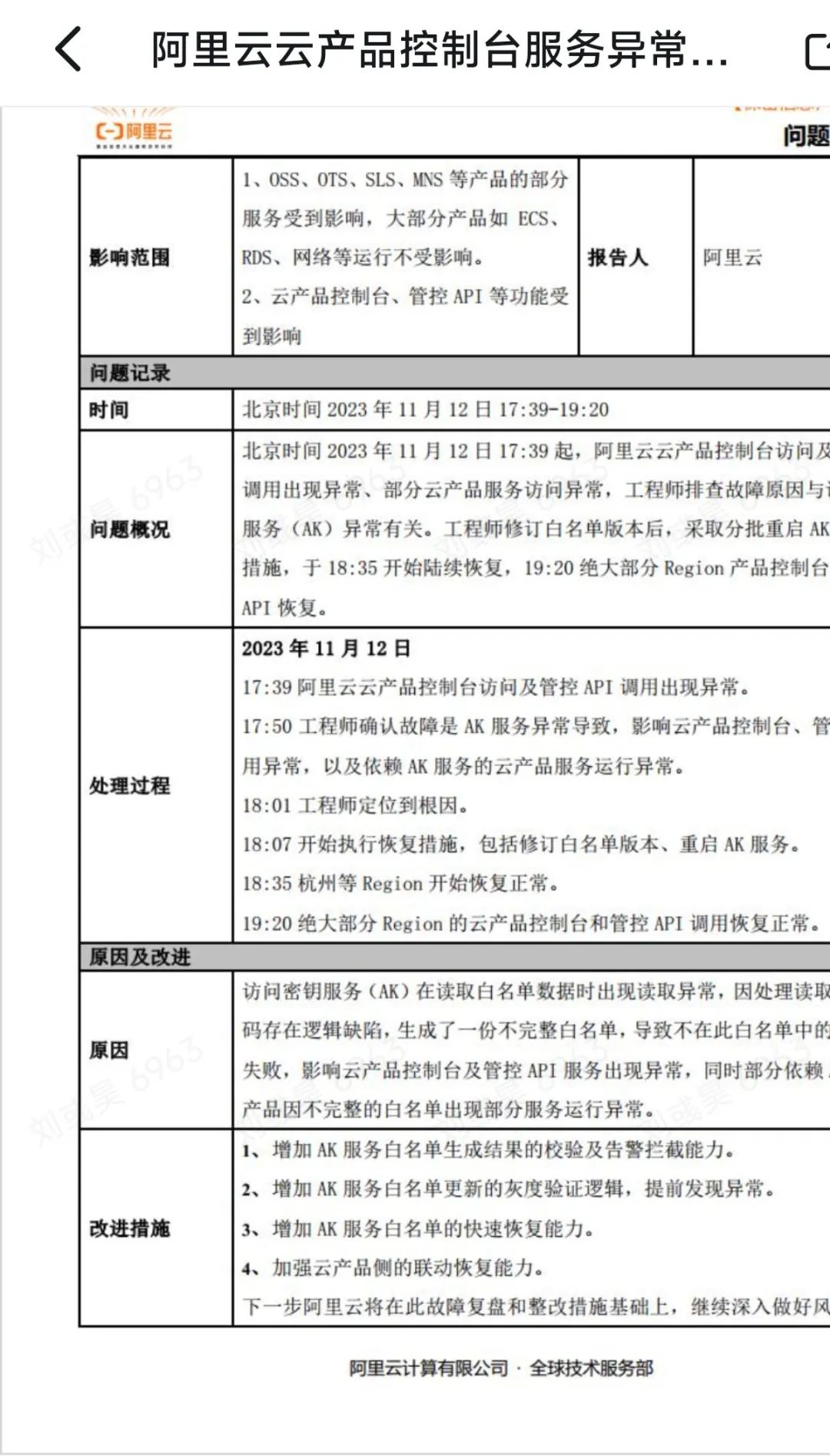
参考阿里云官方给出的故障时间,
在 整个修复过程中,阿里云工程师花了22分钟定位了问题,6分钟后制定方案并开始执行,28分钟后杭州等Region恢复正常,之后又花了45分钟全球Region恢复完毕,一共1小时41分钟。整个故障的影响时间并不是传闻的3个半小时,实际是1个多小时,从17:39分发现故障到18:35就开始陆续恢复了。也并非所有产品都受到影响了,大部分客户都在使用的ECS、RDS、ACK都没受影响。
网上流传的一些“全球性、大面积宕机”的说法太夸张了,那么多用阿里云服务的游戏企业,可曾在11月12日出现了大范围游戏断线吗?我有朋友在大型电商交易平台和IT服务平台,这些业务都哪能正常运行,很多客户也反映没有受到影响,网上所谓的“1个多小时都不能用,全网不能用”的传言并不可信。
阿里云这次故障的故障报告写的很老实:
OSS(对象存储)、OTS(表格存储)、SLS、MNS等产品受到严重功能影响;
但云主机、容器等产品的运行和使用并未受到影响。
用户的控制台确实无法登录,即无法对云主机进行开关机、释放等操作,但并不影响正在使用中的云产品。
淘系APP喜提热搜是真事,明天我会再发一篇文章,好好分析分析这个问题,但是故障现象真是这么回事。这么说吧,读不懂阿里云这份故障报告的云计算爱好者,是你们自己的IT水平不够,吃瓜也是需要动脑子、懂业务的,光有热情有个屁用。
故障基本分析完了,这确实是阿里云内部原因给客户造成的故障,需要向受灾客户私下道歉和正式赔偿。我咨询了几个SRE高手,从这次故障中,我们可以提出一些符合IT常识的建议,希望阿里云能够重视,毕竟客户从这种故障中,学不到什么有价值的东西。
首先,对于AK这种重要的认证服务,要降低爆炸半径,核心工作必须闭环,要做到隔离和收敛,才能做到故障可控。
其次,系统要关注对异常情况的处理,当发现白名单不完整后,应果断丢弃。
最后,从工具和系统机制上改进,要按照“数据、配置、发布”的流程,重点关注一致性和全链路校验,并按Region进行灰度。
备注:阿里云所谓的故障源头AK是什么?
阿里云的用户要访问云上资源,需要通过AK ID(用户名)和AK Secret(密码)来认证身份。
AK服务通过数据库对AK ID(用户名)和AK Secret进行认证之前,需要这个白名单机制的保护,这是预防海量攻击最简单的方法。如果没有这个白名单的保护,AK服务面对的攻击压力是指数级上升的。但这次故障就出在白名单上,由于AK服务没有校验白名单的完整性,导致白名单不完整,让大量不符合命名规则的ID直接被拒绝访问,没能进入认证环节,就是认证失败了。















 126
126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









