







目录
3)2)应用名称-(接口默认勾选,不需要额外操作)-应用描述--立即创建
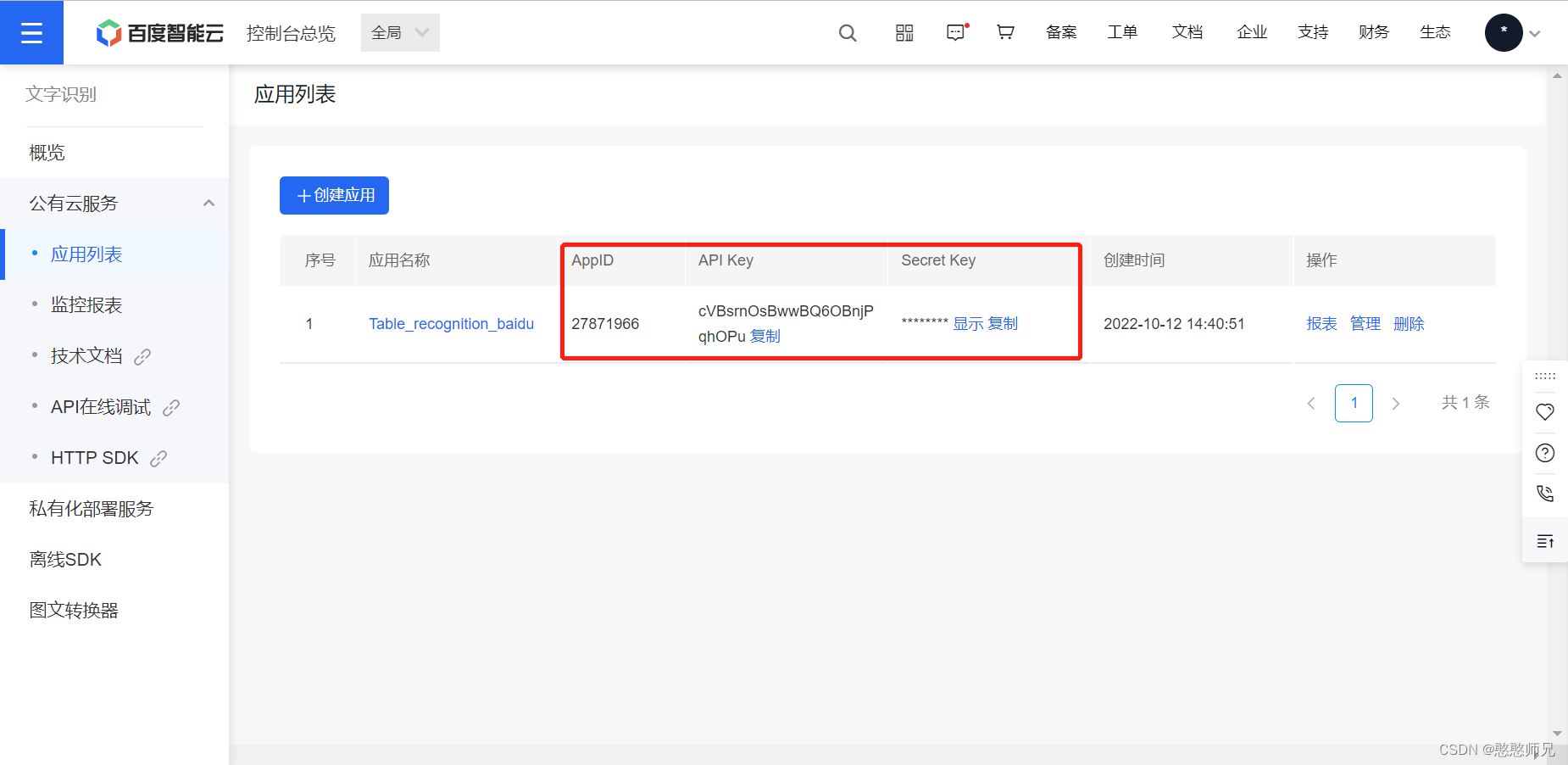
3)3)成功获得APP_ID、API_KEY、Secret_Key
4)运行代码(代码根据生成结果形式分为两类excel、json)
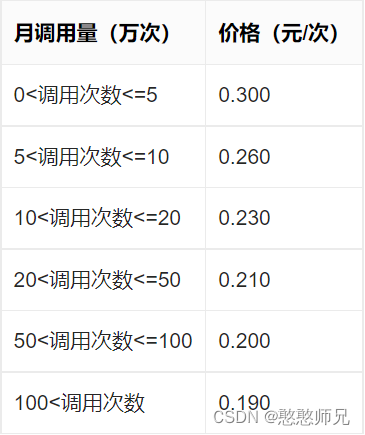
1.调用费用:
在控制台-免费资源页面,可领取所需接口的免费测试资源。个人认证 500 次/月,企业认证 1,000 次/月。
超出部分价格:0~5万次-->0.3元/次;5~10万次-->0.26元/次(其他详见表格所示价格)
2.调用流程
1)注册百度账号并进行个人/企业认证
百度云链接:百度智能云-智能时代基础设施 (baidu.com)
2)领取免费资源流程
2)1)百度智能云--控制台--产品服务--文字识别

2)2)领取免费资源

2)3)勾选“通用场景OCR”,0元领取

3)获取APP_ID、API_KEY、Secret_Key
同2)1)进入控制台界面
3)1)公有云服务--应用列表--创建应用

3)2)应用名称-(接口默认勾选,不需要额外操作)-应用描述--立即创建
3)3)成功获得APP_ID、API_KEY、Secret_Key
4)运行代码(代码根据生成结果形式分为两类excel、json)
代码修改初始信息:APP_ID、API_KEY、Secret_Key、img_path、save_path
4)1)生成结果以excel形式保存
# encoding: utf-8
import os
import sys
import requests
import time
import tkinter as tk
from tkinter import filedialog
from aip import AipOcr
import time
"""定义常量"""
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
"""初始化AipFace对象"""
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
image_path = 'D:\\table_generation-master\\demo\\table_recog_test'
save_path = 'D:\\table_generation-master\\demo\\table_recog_test_output'
"""读取图片"""
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
"""文件下载函数"""
def file_download(url, file_path):
r = requests.get(url)
with open(file_path, 'wb') as f:
f.write(r.content)
if __name__ == "__main__":
root = tk.Tk()
root.withdraw()
# data_dir = filedialog.askdirectory(title='请选择图片文件夹') + '/'
# result_dir = filedialog.askdirectory(title='请选择输出文件夹') + '/'
data_dir = image_path
result_dir = save_path
num = 0
for name in os.listdir(data_dir):
print ('{0} : {1} 正在处理:'.format(num+1, name.split('.')[0]))
image = get_file_content(os.path.join(data_dir, name))
res = client.tableRecognitionAsync(image, )
print ("res:", res)
if 'error_code' in res.keys():
print ('Error! error_code: ', res['error_code'])
sys.exit()
req_id = res['result'][0]['request_id'] #获取识别ID号
print("ID:", req_id)
for count in range(1, 20): #OCR识别也需要一定时间,设定10秒内每隔1秒查询一次
res = client.getTableRecognitionResult(req_id) #通过ID获取表格文件XLS地址
print("xls_path{}".format(res))
print(res['result']['ret_msg'])
if res['result']['ret_msg'] == '已完成':
break #云端处理完毕,成功获取表格文件下载地址,跳出循环
else:
time.sleep(1)
url = res['result']['result_data']
xls_name = name.split('.')[0] + '.xls'
file_download(url, os.path.join(result_dir, xls_name))
num += 1
print ('{0} : {1} 下载完成。'.format(num, xls_name))
time.sleep(1)
4)2)生成结果以json形式保存
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import copy
import json
from baidubce import bce_base_client
from baidubce.auth import bce_credentials
from baidubce.auth import bce_v1_signer
from baidubce.http import bce_http_client
from baidubce.http import handler
from baidubce.http import http_methods
from baidubce import bce_client_configuration
import requests
import base64
import time
# from try6 import webimage
from urllib.parse import urlencode
API_KEY = ''
SECRET_KEY = ''
img_path = "D:\\table_generation-master\\demo\\table_recog_test\\0M208145r02110zw_1.png"
save_path = "D:\\table_generation-master\\demo\\baidu_result\\jit_baidu.json"
def change_img_to_base64(image_path):
"""base64编码图片-->url"""
with open(image_path, 'rb') as f:
image_data = f.read()
base64_data: bytes = base64.b64encode(image_data) # base64编码
return base64_data
# def change_base64_to_url(base64_data):
def get_request_di():
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={}&client_secret={}'.format(API_KEY,SECRET_KEY)
response = requests.get(host)
if response:
access_token_get = response.json()["access_token"]
request_url = "https://aip.baidubce.com/rest/2.0/solution/v1/form_ocr/request"
# 二进制方式打开图片文件
f = open(img_path, 'rb')
img_base64 = base64.b64encode(f.read())
# img = webimage(img_base64, access_token_get)
params = {"image":img_base64}
request_url = request_url + "?access_token=" + access_token_get
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers, json=True)
if response:
request_id = response.json()["result"][0]["request_id"]
print(response.json())
print(request_id)
return request_id, access_token_get
class ApiCenterClient(bce_base_client.BceBaseClient):
def __init__(self, config=None):
self.service_id = 'apiexplorer'
self.region_supported = True
self.config = copy.deepcopy(bce_client_configuration.DEFAULT_CONFIG)
if config is not None:
self.config.merge_non_none_values(config)
def _merge_config(self, config=None):
if config is None:
return self.config
else:
new_config = copy.copy(self.config)
new_config.merge_non_none_values(config)
return new_config
def _send_request(self, http_method, path,
body=None, headers=None, params=None,
config=None, body_parser=None):
config = self._merge_config(config)
if body_parser is None:
body_parser = handler.parse_json
return bce_http_client.send_request(
config, bce_v1_signer.sign, [handler.parse_error, body_parser],
http_method, path, body, headers, params)
def demo(self,request_id, access_tok):
path = b'/rest/2.0/solution/v1/form_ocr/get_request_result'
headers = {}
headers[b'Content-Type'] = 'application/x-www-form-urlencoded;charset=UTF-8'
params = {}
params['access_token'] = access_tok
body = 'request_id={}&result_type=json'.format(request_id)
return self._send_request(http_methods.POST, path, body, headers, params)
if __name__ == '__main__':
endpoint = 'https://aip.baidubce.com'
ak = API_KEY
sk = SECRET_KEY
config = bce_client_configuration.BceClientConfiguration(credentials=bce_credentials.BceCredentials(ak, sk),
endpoint=endpoint)
client = ApiCenterClient(config)
request_id, access_tok = get_request_di()
print("access_token", access_tok)
print("request_id", request_id)
for count in range(1, 20):
res_ = client.demo(request_id, access_tok)
print(res_.__dict__['raw_data'])
print(type(res_))
res = json.loads(res_.__dict__["raw_data"])
if res['result']['ret_msg'] == '已完成':
break # 云端处理完毕,成功获取表格文件下载地址,跳出循环
else:
time.sleep(1)
dict_json = json.dumps(res_, ensure_ascii=False)
with open(save_path, 'w', encoding='utf-8') as fp:
fp.write(dict_json+'\r\n')
3.json文件主要信息(举例信息以字典形式给出)
其他信息详见文字识别OCR (baidu.com)
form_num:表格数量
forms:表格内容信息
footer:表尾信息
header:表头数据信息
body:表格主体部分数据
rect:(top,left)-->左上角坐标;(width,height)-->单元格宽/高
column:(初值为1)<只显示合并单元格的首位和末尾>
row:(初值为1)
word:















 861
861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









