







Embodied Intelligence作为一种将感知、决策与执行相结合的前沿技术,正在引领机器人技术迈向新的高度。具身智能不仅要求机器人具备理解和处理复杂环境的能力,还需赋予其自主决策和执行任务的能力。本文将深入探讨如何将LLM和多模态大模型与机器人技术相结合,构建一套完整的具身智能技术流程。本文参考了同济子豪兄的部分工作,TsingtaoAI团队对整体构建做了一部分拓展和延伸。文中相关流程和代码仅作示例,用于读者理解相关的内部实现逻辑,不具备工程复现意义。
本文目录
- 一套最小的具身智能应用实现流程
- 系统架构设计
- LLM与机器人集成
- 多模态大模型的应用
- 自主决策与执行模块
- 传感器与执行器接口
- 通信与数据处理
- 系统部署与优化
- 案例分析与代码示例
- 未来展望
1. 一套最小的具身智能应用实现流程
具身智能强调机器人不仅具备感知和认知能力,还能够通过与环境的交互实现自主行为。与传统的机器人相比,具身智能机器人更具适应性和灵活性,能够在复杂、多变的环境中执行任务。这一概念的核心在于将感知、认知和动作控制有机结合,使机器人具备类似人类的智能行为。
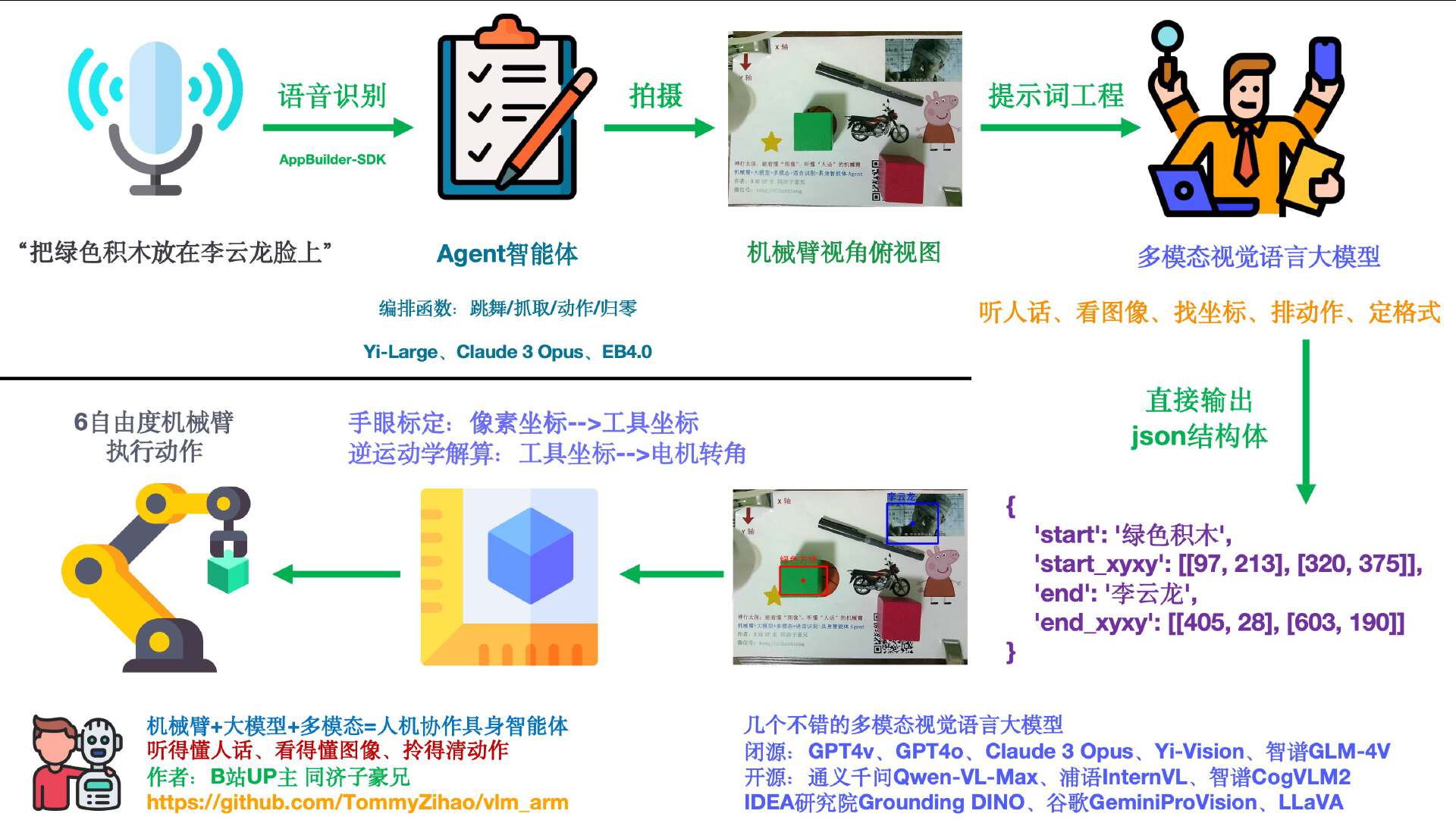
一套最小的具身智能应用实现流程-引自同济子豪兄
1.1 具身智能的关键要素
- 感知能力:通过多种传感器获取环境信息,包括视觉、听觉、触觉等。
- 认知能力:利用AI模型进行信息处理和理解,实现环境建模和任务规划。
- 动作控制:通过执行器实现对环境的物理操作,完成特定任务。
- 自主决策:基于感知和认知结果,自主制定行动策略。
2. 系统架构设计
构建具身智能系统需要一个高度集成的架构,涵盖感知、认知、决策与执行等多个模块。以下是一个典型的具身智能系统架构图:
diff
+-----------------------+
| 感知模块 |
| - 摄像头 |
| - 麦克风 |
| - 触觉传感器 |
+----------+------------+
|
v
+----------+------------+
| 数据处理 |
| - 数据预处理 |
| - 特征提取 |
+----------+------------+
|
v
+----------+------------+
| 认知模块 |
| - 大型语言模型(LLM) |
| - 多模态大模型 |
+----------+------------+
|
v
+----------+------------+
| 决策与规划模块 |
| - 行为规划 |
| - 决策树 |
+----------+------------+
|
v
+----------+------------+
| 执行模块 |
| - 机械臂控制 |
| - 动作执行 |
+-----------------------+
2.1 模块详细说明
- 感知模块:负责采集环境数据,包括视觉、听觉和触觉等多种传感器信息。
- 数据处理:对采集到的数据进行预处理和特征提取,为认知模块提供高质量的输入。
- 认知模块:利用LLM和多模态大模型对数据进行理解和分析,生成上下文相关的信息。
- 决策与规划模块:基于认知结果,制定具体的行动计划和策略。
- 执行模块:将决策转化为具体的物理动作,通过机械臂等执行器完成任务。
3. LLM与机器人集成
大型语言模型,如OpenAI的GPT-4o,具备强大的自然语言理解和生成能力。将LLM集成到机器人系统中,可以显著提升机器人的交互能力和决策水平。
3.1 LLM的选择与部署
在选择LLM时,需要考虑模型的性能、响应速度和资源消耗。当前,主流的LLM包括:
- Yi-Large:具有强大的中文理解和生成能力,适合中文环境下的应用。
- Claude 3:以其稳健性和高效性著称,适用于多种任务场景。
- ERNIE 4.0:百度推出的多任务学习模型,在中文NLP任务中表现优异。
3.1.1 部署环境
为了实现高效的模型运行,建议使用亚马逊云科技的生成式AI平台Amazon Bedrock。Bedrock提供了高性能的计算资源和便捷的模型管理接口,适合大规模部署LLM。
python
import boto3
# 初始化Bedrock客户端
bedrock_client = boto3.client('bedrock', region_name='us-west-2')
# 调用LLM进行文本生成
response = bedrock_client.invoke_model(
ModelId='ernie-4.0',
Prompt='你好,机器人!今天的任务是什么?',
MaxTokens=150
)
print(response['GeneratedText'])
3.2 LLM与感知模块的融合
LLM不仅可以处理文本指令,还能结合视觉和听觉信息,实现更复杂的交互。通过多模态输入,机器人可以更准确地理解用户意图。
python
from transformers import CLIPProcessor, CLIPModel
import torch
# 初始化多模态模型
clip_model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def process_multimodal(image, text):
inputs = clip_processor(text=[text], images=image, return_tensors="pt", padding=True)
outputs = clip_model(**inputs)
logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)
return probs
# 示例调用
image = Image.open("example.jpg")
text = "这是一个红色的苹果。"
prob = process_multimodal(image, text)
print(prob)
3.3 自然语言指令解析与执行
通过LLM,机器人可以解析自然语言指令,并将其转化为具体的动作指令。例如,用户可以通过语音指令“请将红色的物体拿起来”,机器人通过LLM解析后,结合视觉信息,执行相应的动作。
python def parse_instruction(instruction):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











