









前言
本文是根据python官方教程中标准库模块的介绍,自己查询资料并整理,编写代码示例做出的学习笔记。
根据模块知识,一次讲解单个或者多个模块的内容。
数据压缩
很多时候我们可以利用的内存有限,时间有限,资源有限,但是又不得不进行一些大量数据的操作时,我们可以通过压缩的方式灵活高效地处理数据存储和传输问题,优化应用性能。
在Python中,通过特定的算法,将原始数据转换成一个更紧凑的形式,这个过程称为压缩;而将压缩后的数据恢复到原始形式的过程则称为解压缩。这里简单了解一些这些模块后,一个个进行学习使用。
- zlib:
介绍:zlib 模块提供了对 zlib 压缩库的接口,支持 gzip 文件格式的压缩和解压缩。
功能:可以用于数据的简单压缩和解压缩,常用于需要快速压缩速度和相对较高压缩率的场合。
常用函数:compress(), decompress(), crc32() 等。 - gzip:
介绍:gzip 模块允许你使用 gzip 文件格式进行压缩和解压缩操作。
功能:提供了文件对象(如 GzipFile)来处理 .gz 文件,可以透明地读写压缩文件,就像它们是普通文件一样。
常用类:GzipFile 类用于创建或读取 gzip 格式的文件。 - bz2:
介绍:此模块提供了对 bzip2 压缩算法的支持。
功能:相较于 zlib,bzip2 提供了更高的压缩比,但压缩速度较慢。适用于需要高压缩比而时间不是关键因素的场景。
常用类:BZ2File 类用于读写 bzip2 格式的文件。 - lzma:
介绍:lzma 模块提供了对 LZMA (Lempel-Ziv-Markov chain Algorithm) 压缩算法的支持,这是 xz 文件格式的基础。
功能:LZMA 提供了非常高的压缩比,特别适合于大文件的压缩。它在解压速度上也表现良好。
常用类:LZMAFile 类用于读写 xz 格式的文件,以及相关的压缩和解压缩函数。
这些模块使得Python能够方便地处理各种常见的压缩格式,满足不同的数据压缩需求。
zlib
zlib模块是Python的标准库之一,它提供了对zlib压缩库的接口,支持DEFLATE压缩算法,这是一种广泛使用的数据压缩算法,也是gzip、zip等文件格式的基础。zlib模块主要用于需要快速压缩速度和相对较高压缩率的场合,比如网络数据传输、文件存储等。
压缩与解压
import zlib
data = b"This is an example of compressed data."
# 压缩
compressed_data = zlib.compress(data)
# 解压
decompressed_data = zlib.decompress(compressed_data)
print(decompressed_data.decode())
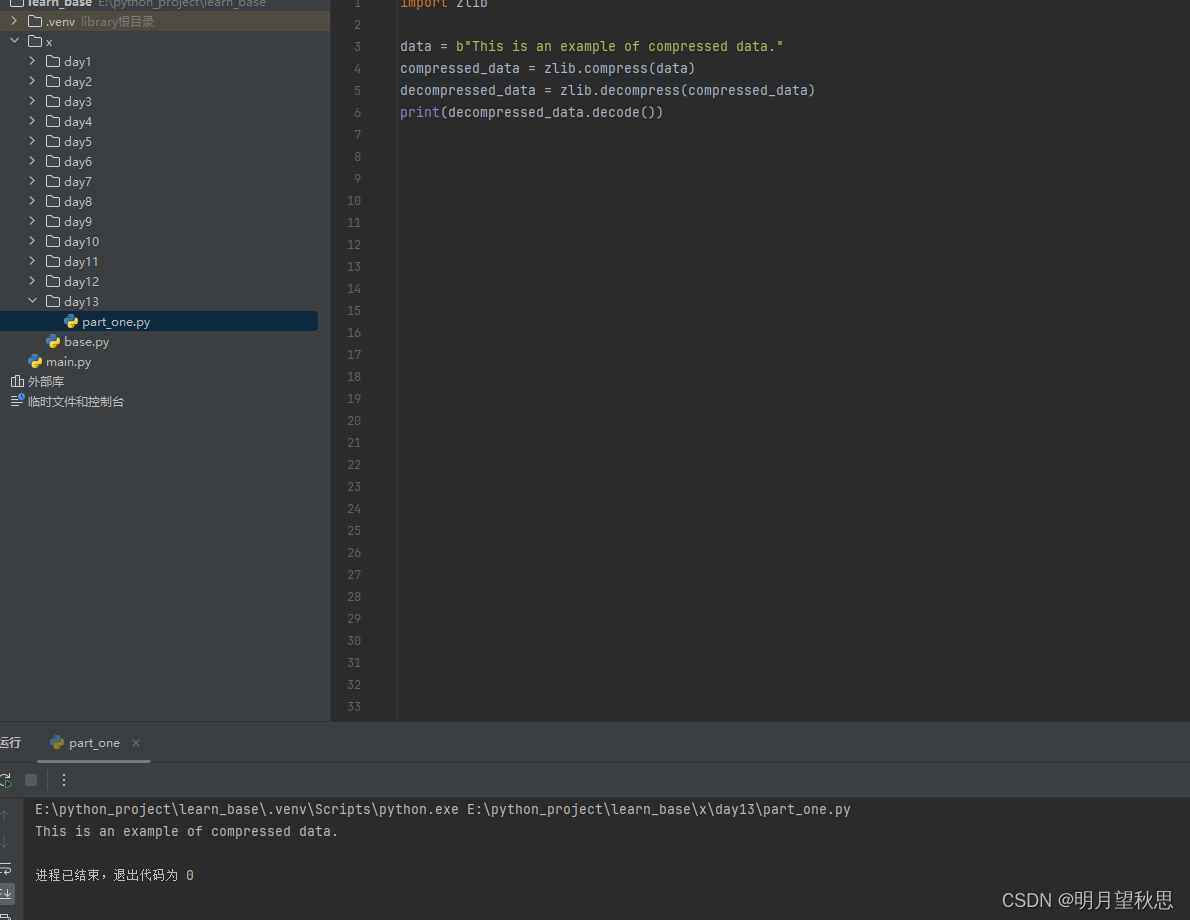
通过输出可以看出,字符串压缩再解压后打印,并没有什么影响。
这里单独要讲2个点。
-
字符串前面的b是什么?
这个b表示后面的字符串会被处理成一个字节串。因为compress函数的入参就是一个字节串,直接传入字符串是不行的。为什么字节串可以字符串不行呢?因为zlib这个模块处理的就是原始的二进制数据,而不是文本字符串。字符串在计算机内存中是以特定的字符编码(如UTF-8)表示的,而压缩算法直接作用于这些二进制表示上。
有没有类似的写法呢?这里随便讲几个,以后遇到这种类似的写法可以查查资料学习一下:字符串前的u前缀(Python 2中):在Python 2中,字符串前加u表示创建一个Unicode字符串。例如,u"Hello, World!"。Python 3中默认字符串就是Unicode,因此不再需要u前缀。
字符串前的r前缀:表示创建一个原始字符串(rawstring),其中的转义字符不会被处理。这在编写正则表达式或Windows文件路径时特别有用。例如,r"C:\path\to\file.txt"。
字符串前的f前缀:这个就不用多讲了,格式化字符串,用来替换字符串中某些特定的值
-
怎么压缩中文?
这个问题其实和1有关,还是那句话。这个模块处理的是二进制数据,所以要压缩中文,先把中文转成二进制数据就好了。# 待压缩的字符串 text = '大家好,我是明月望秋思' # 将字符串转换为字节串(这里使用UTF-8编码) data = text.encode('utf-8') # 使用zlib进行压缩 compressed_data = zlib.compress(data) # 解压缩,先确保数据被正确压缩,然后解压 decompressed_data = zlib.decompress(compressed_data) # 将解压缩后的字节串转换回字符串 decompressed_text = decompressed_data.decode('utf-8') # 打印原字符串和解压缩后的字符串进行对比 print("Original Text:", text) print("Decompressed Text:", decompressed_text) # 可选:打印压缩前后数据的长度比较 print("Original Size:", len(data), "bytes") print("Compressed Size:", len(compressed_data), "bytes")
很简单转成字节串就行了。大家看压缩前后对比,内容不变,但是数据长度变了。这是正常现象,因为原本的字符串本身长度就不长,转个压缩对象反而增加了对象信息之类的开销。当你压缩的内容越长,受益越大。
gzip
gzip模块提供了对gzip格式压缩文件的支持,gzip是一种流行的文件压缩格式,广泛应用于文件传输和存储,特别是在Unix/Linux系统中。gzip格式基于DEFLATE压缩算法,该算法结合了LZ77压缩方法和霍夫曼编码。
import gzip
with open('original_file.txt', 'rb') as f_in:
with gzip.open('compressed_file.gz', 'wb') as f_out:
f_out.writelines(f_in)
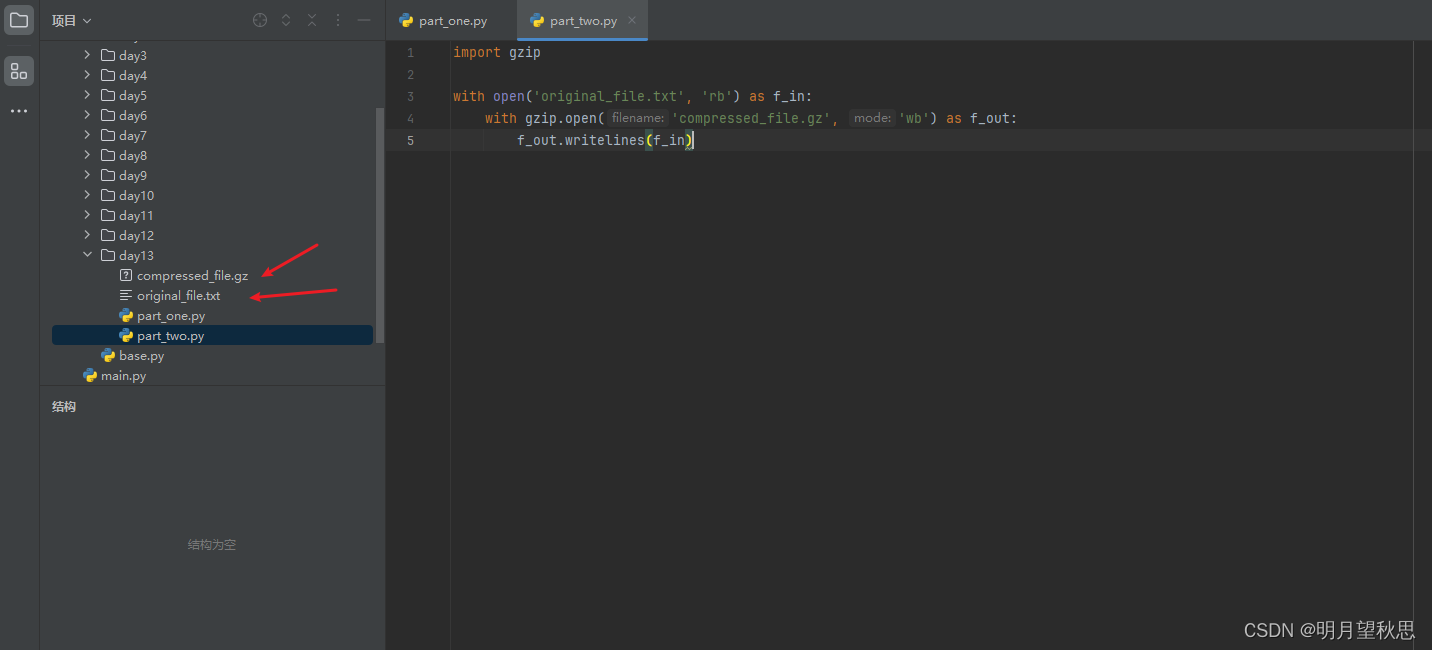
代码很简单。
第一行:打开一个文件,读取二进制流模式。之前讲的rbopen文件打开模式的参数不会忘了吧。
第二行:用gzip模块的open函数打开创建一个.gz文件,写入二进制流模式。
第三行:压缩文件读取原文件的二进制流。
这样就可以看到,文件已经被压缩好了,那么接下来我们解压一下。
with gzip.open('compressed_file.gz', 'rb') as f_in:
with open('decompressed_file.txt', 'wb') as f_out:
f_out.writelines(f_in)
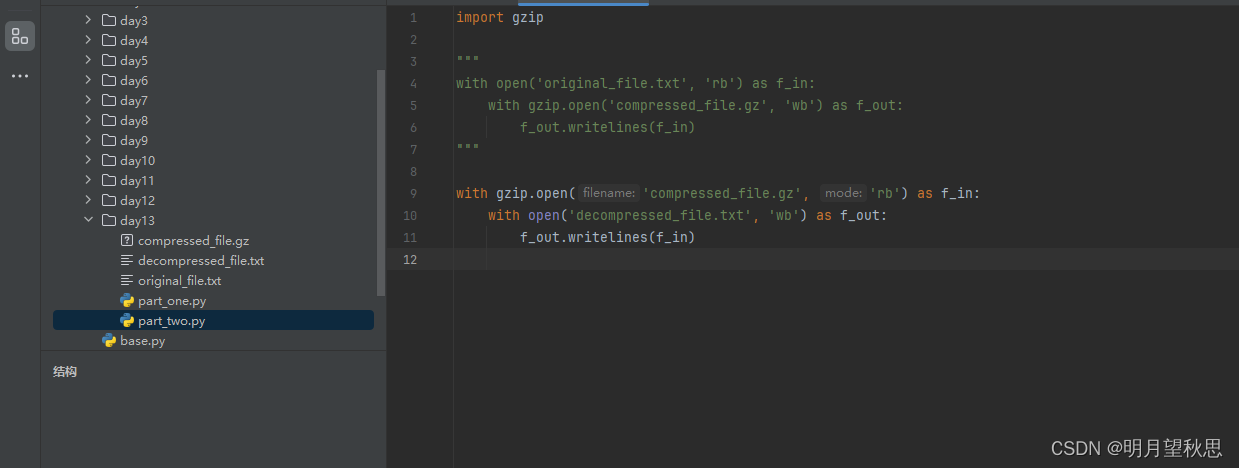
代码一样的简单。
第一行:打开压缩文件,读取二进制流模式。
第二行:打开创建一个txt文件,写入二进制流模式。
第三行:二进制流的写入
最后我们看一下文件内容是不是一样
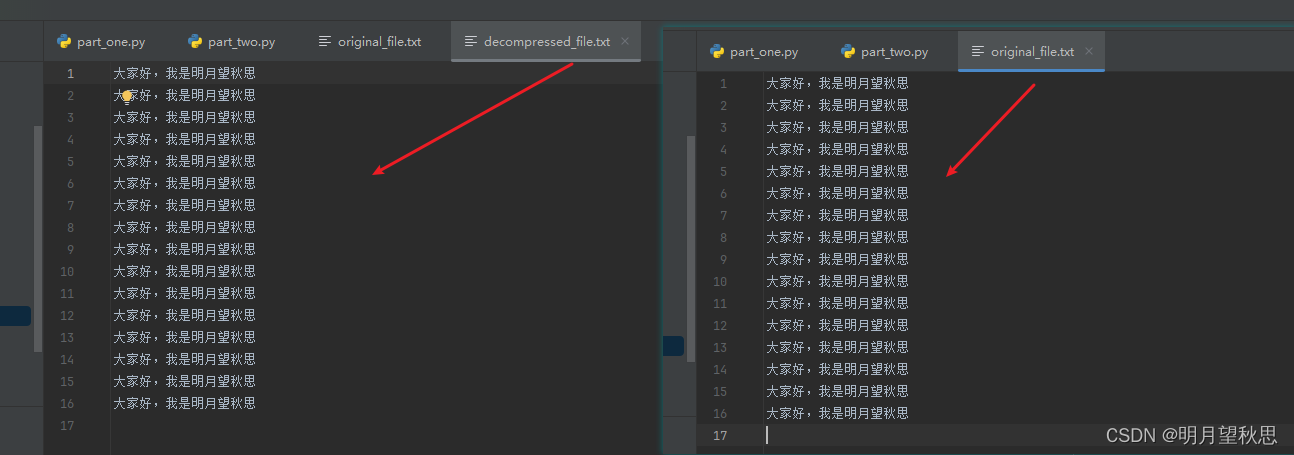
事实也证明了,我们使用gzip模块对文件进行压缩和解压,不会改变文件内容。
bz2
bz2模块提供了对BZ2文件格式的支持,这是一种使用Burrows-Wheeler变换和Huffman编码的高压缩比数据压缩算法。BZ2格式通常比传统的gzip格式提供更高的压缩比,尽管它的压缩和解压缩速度可能较慢。bz2模块主要用于需要高压缩率的场合,如存储大量数据或在网络上传输数据时减少带宽消耗。
import bz2
# 待压缩的字符串
text = '这是一个用于演示bz2模块的长文本字符串...'
# 转换为字节串
data = text.encode('utf-8')
# 压缩数据
compressed_data = bz2.compress(data)
# 解压缩数据
decompressed_data = bz2.decompress(compressed_data)
# 将解压缩后的字节串转换回字符串
decompressed_text = decompressed_data.decode('utf-8')
print('压缩前:', text)
print('压缩后:', compressed_data)
print('解压缩后:', decompressed_text)
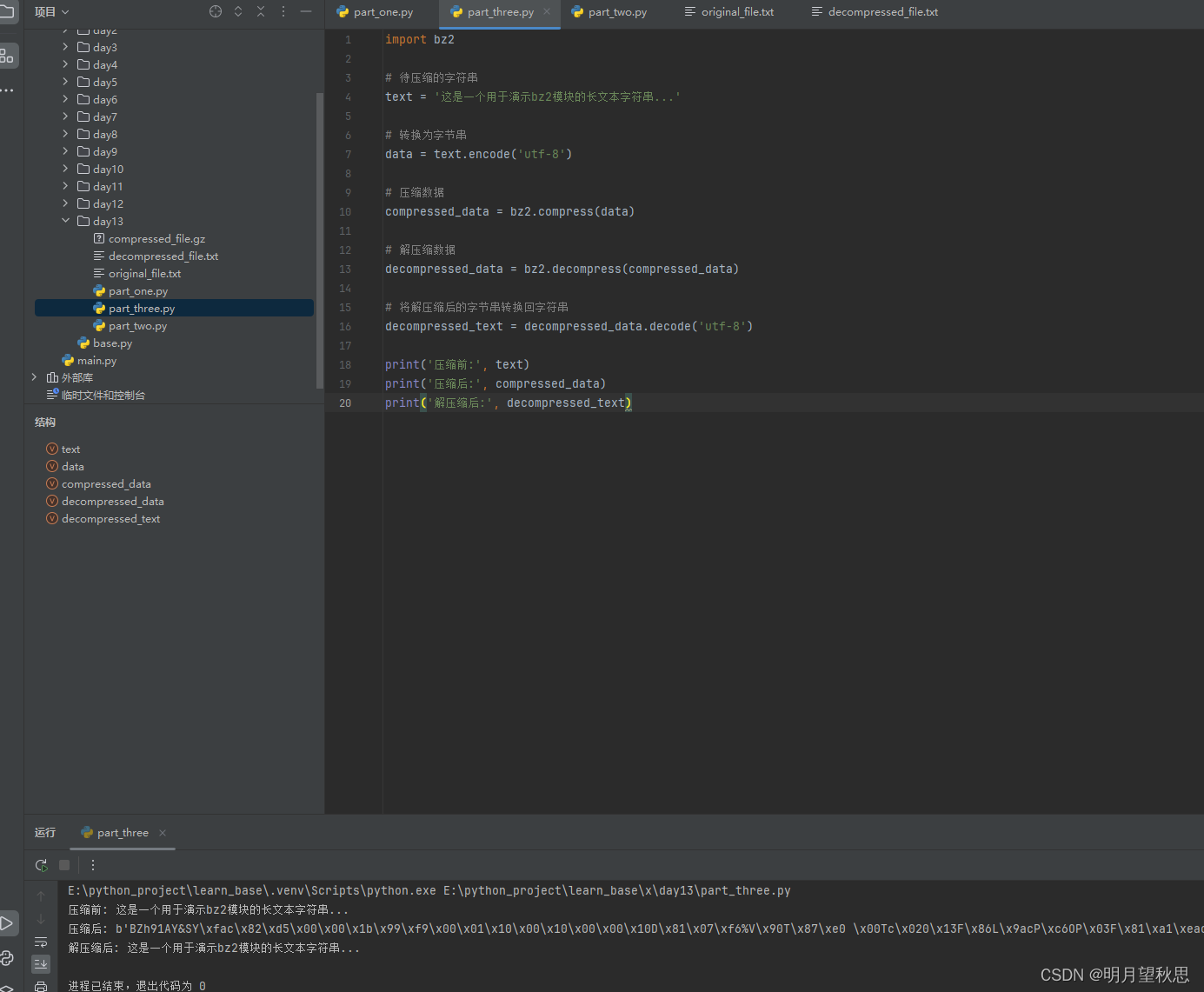
看代码就知道,compresse函数仍然接受字节串类型的参数。
最后,我们操作一下文件试试。
# 写入BZ2文件
with bz2.BZ2File('example.bz2', 'wb') as f:
f.write(text.encode('utf-8'))
# 读取BZ2文件
with bz2.BZ2File('example.bz2', 'rb') as f:
content = f.read().decode('utf-8')
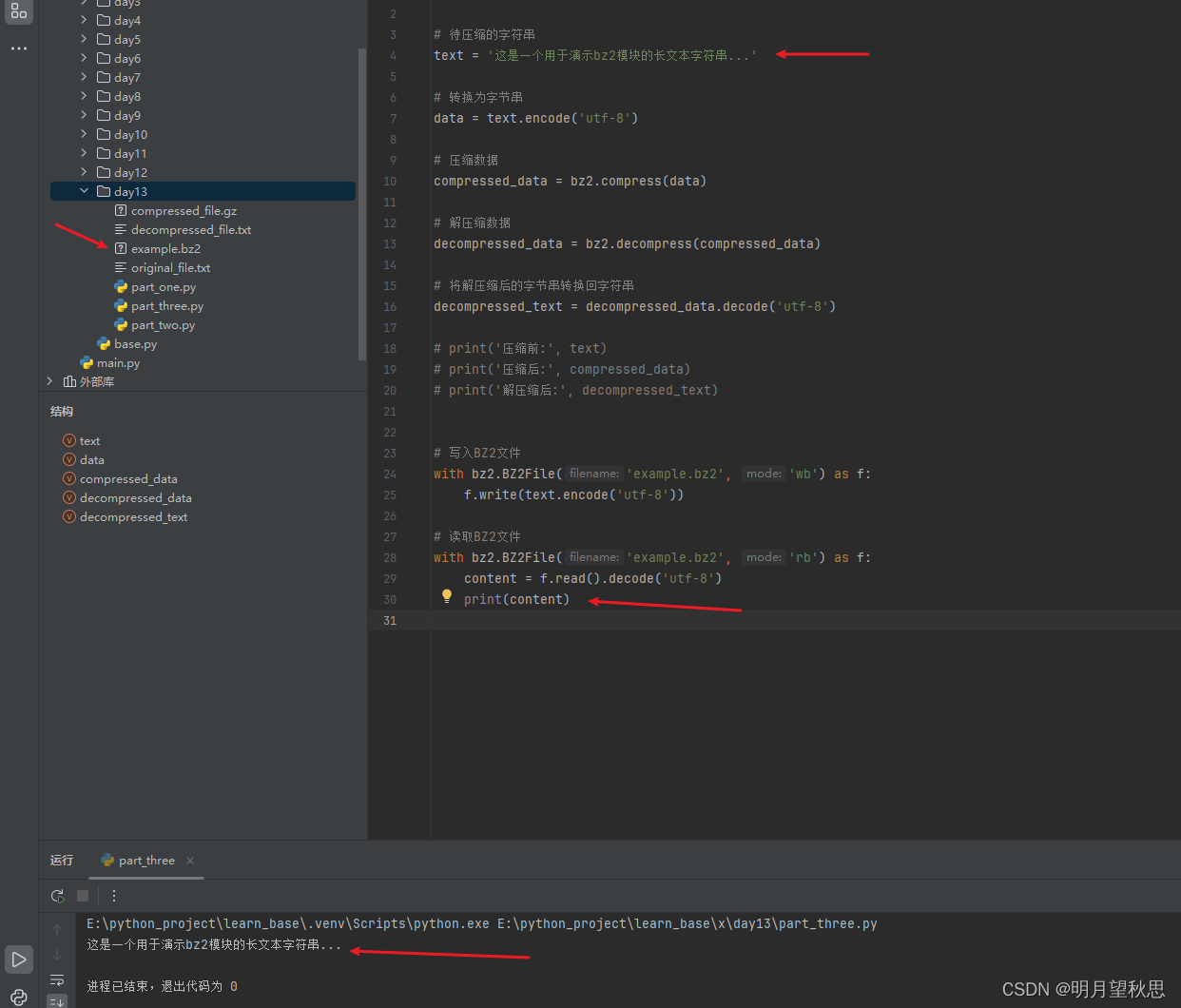
也能看到,我们将text的内容存到bz2文件后,读取出的内容与text的内容仍然是一致的。
lzma
lzma模块提供了对LZMA(Lempel-Ziv-Markov Chain Algorithm)压缩算法的支持,这是一种高效的压缩算法,以其高压缩比和相对较快的解压速度而著称。LZMA算法是7-Zip归档工具的核心部分,常用于创建.xz格式的压缩文件。
import lzma
# 写入.xz文件
with lzma.open('example.xz', 'w') as f:
f.write(b'This is some example text to compress.')
# 读取.xz文件
with lzma.open('example.xz', 'r') as f:
content = f.read()
print(content.decode('utf-8'))
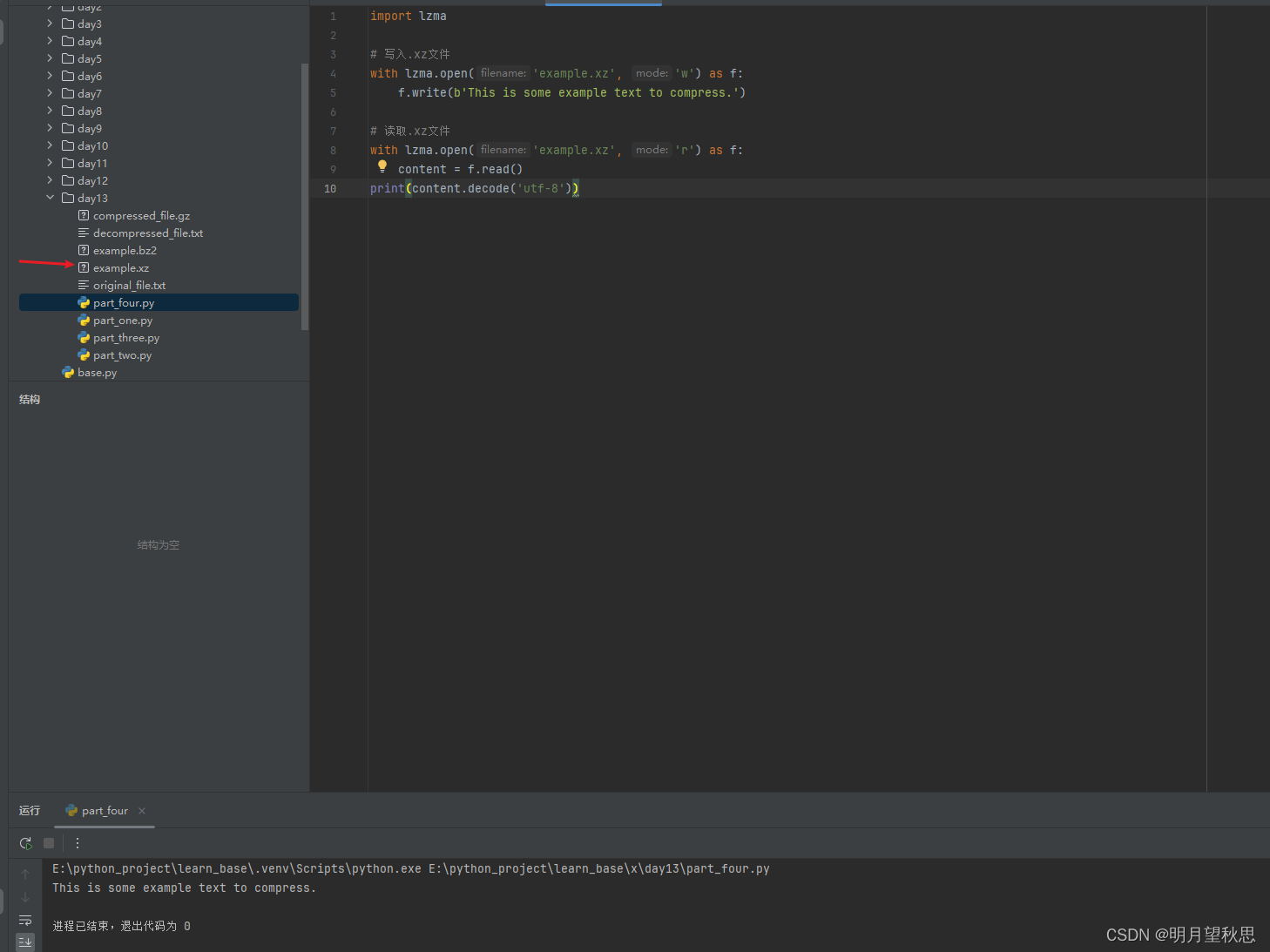
这就是压缩和解压缩的例子。可以看到在文件流操作的时候,仍然使用了带b前缀的字符串(其实就是字节串)。这是不是说明和之前三个模块的是一样的,就没多写了。
结尾
以上就是关于数据压缩的四个模块的压缩和解压的功能。不难并且几个模块基础使用方式其实很相似。
当然这几个模块会有更高级特性和用法,这个依旧是用到的时候再仔细学习。基础的压缩和解压缩已经够用了。
作业
- 四个模块分别进行压缩和解压缩练习。
ps:今天工作的时候复制swagger链接,中文全部被转成了符号+数字的组合。复制出来以后用urllib.parse又转回去了。然后复制的链接瞬间好看多了!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









