






三、解析内容
3.1 对爬取的HTML文件进行解析
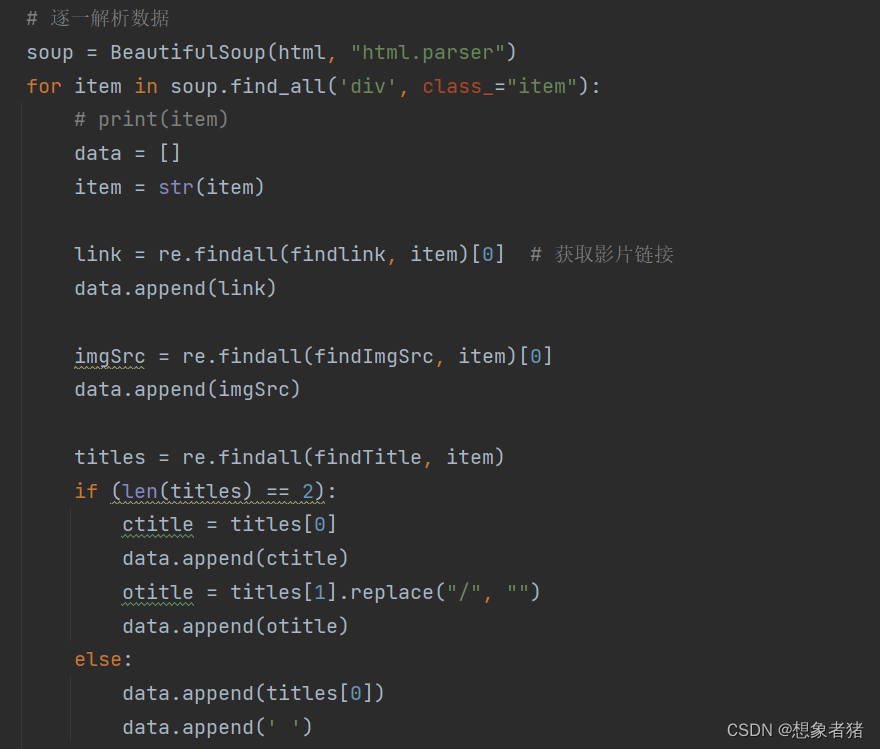
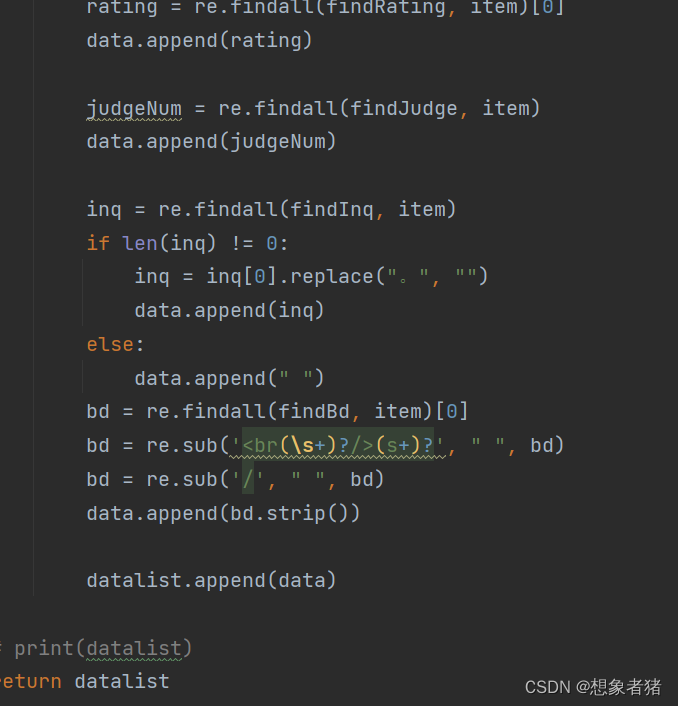
3.1.2 逐一解析,提取数据
利用beautifulSoup模块对文本进行解析:
3.1.3 BeautifulSoup的常见用法:
# t_list = bs.select("head>title") #通过子标签来查找
# print(t_list)
# t_list = bs.select(".mnav~.bri") #找到与manv同级的bri(通过兄弟标签来查找)
# print(t_list[0].get_text())
# t_list = bs.select(".mnav") #通过类名查找
# print(t_list)
#
# t_list = bs.select("#u1") #通过id查找
# print(t_list)
四、保存数据
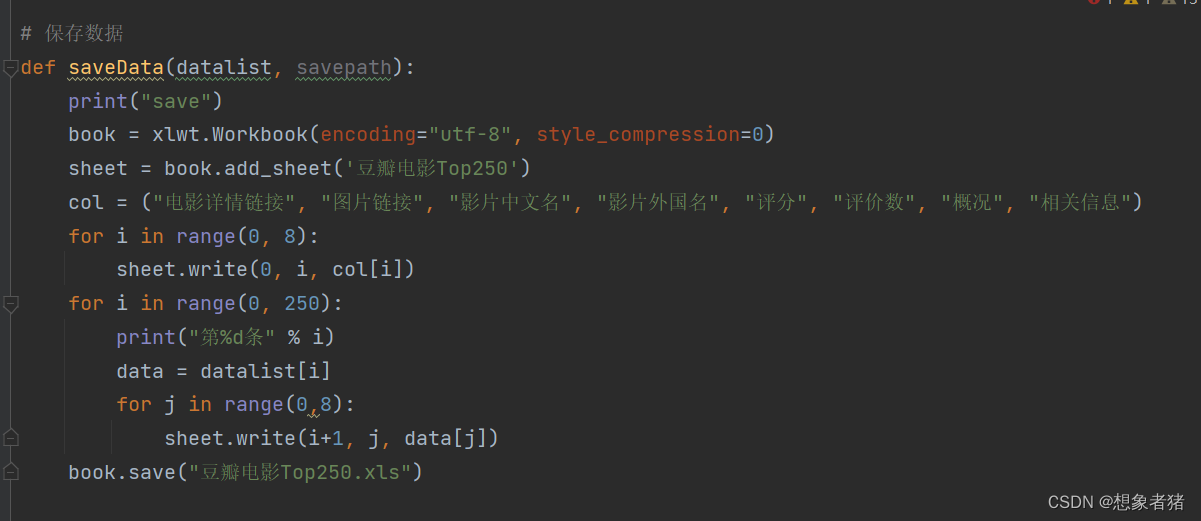
4.1 Excel保存数据
利用python库xlwt将抽取的数据datalist写入Excel表格:
先定义保存路径:
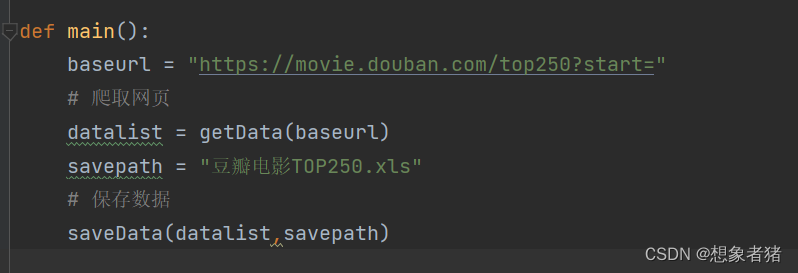
调用:
五、结束主函数
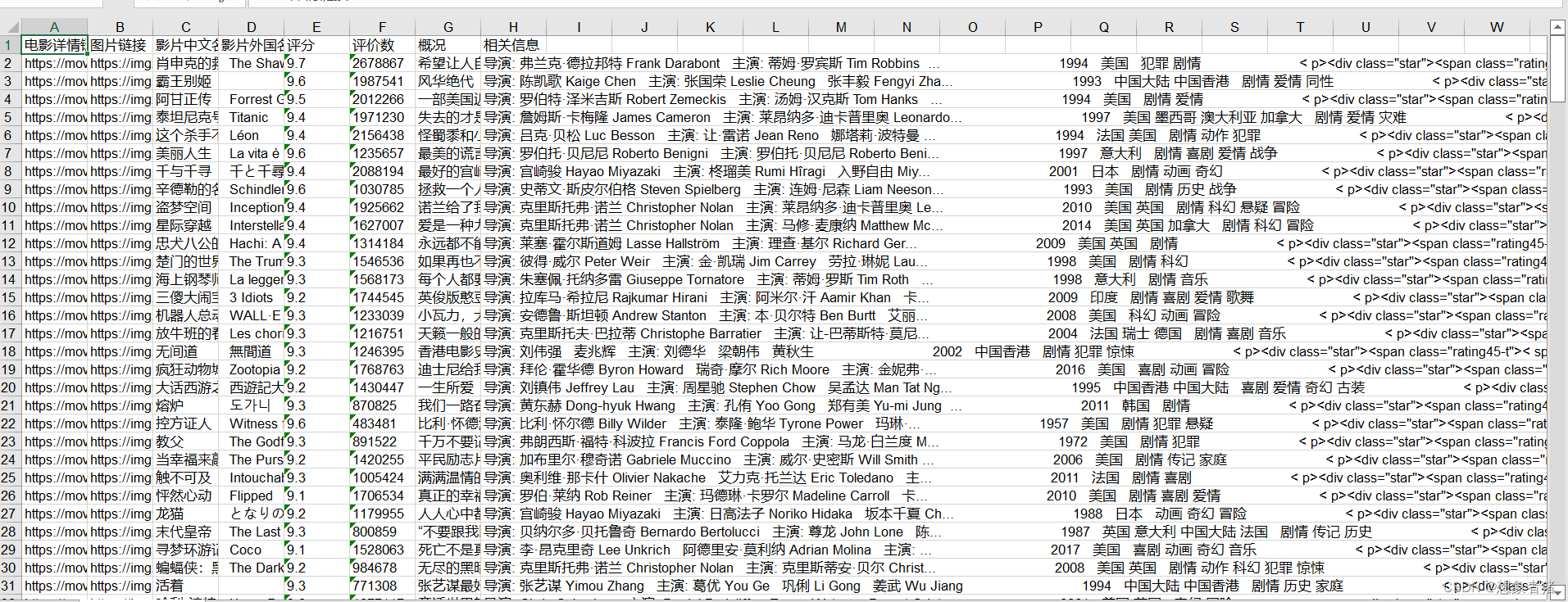
六、查看保存的数据















 119
119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









