






链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。
链表结构的存储结构如下(带头结点的情况)
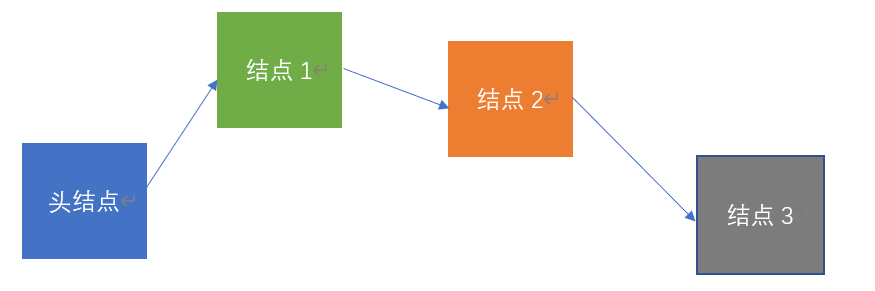
头结点:一般不存储数据。
其他结点:包括数据域和指针域。
数据域:存储数据元素。
指针域:存储存储下一个结点的地址。
链表的常见操作(初始化与增删查改)
ps:接下来都以“工人”结构体作为分析对象
typedef struct Worker
{
//数据域
char *name; //姓名
int id; //工号
unsigned int age; //年龄
float salary; //工资
//指针域
struct Worker *next; //用于指向下一个结点的指针
} Worker, *PWorker; 1.链表的初始化(生成头结点)
PWorker init()
{
PWorker head; //声明结点指针
head = (Worker *)malloc(sizeof(Worker)); //生成头结点并把地址赋值给head
if (!head)
return NULL;
head->next = NULL;
return head;
}2.增加结点(头插法)
void insert_worker(PWorker wrk, char *name, int id, unsigned int age, float salary)
{
PWorker p;
p = (Worker *)malloc(sizeof(Worker)); //生成结点
p->name = name, p->id = id, p->age = age, p->salary = salary; //数据域赋值
p->next = wrk->next; //新结点指针域指向头结点的下一个结点
wrk->next = p; //头结点指针域指向新结点
}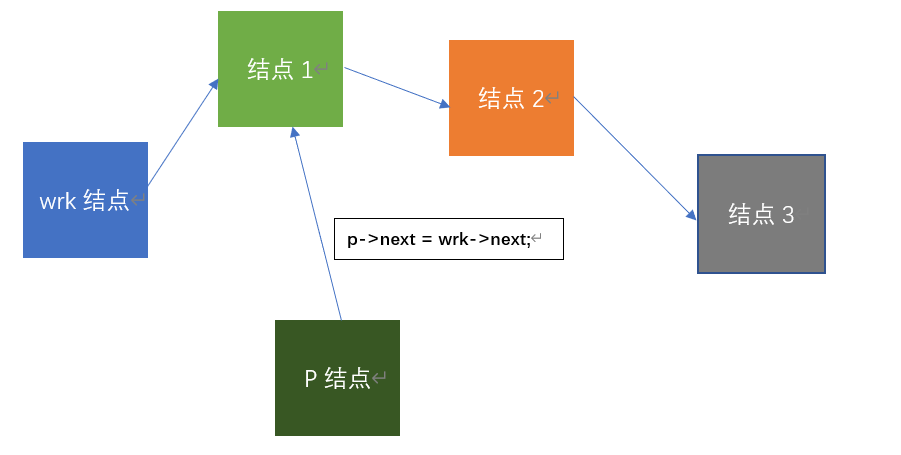
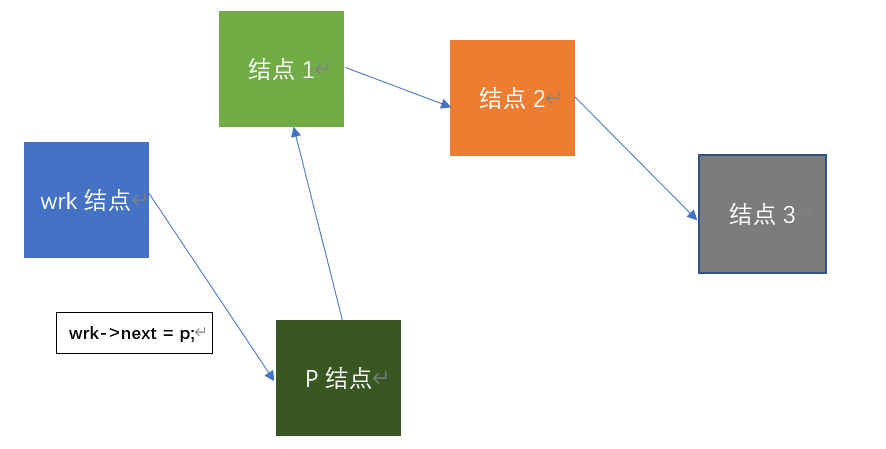
ps: wrk与p在这里是对应结点的指针变量,不是结点的变量名,为了画出来的图方便理解,我就直接叫wrk结点与p结点,敬请理解。
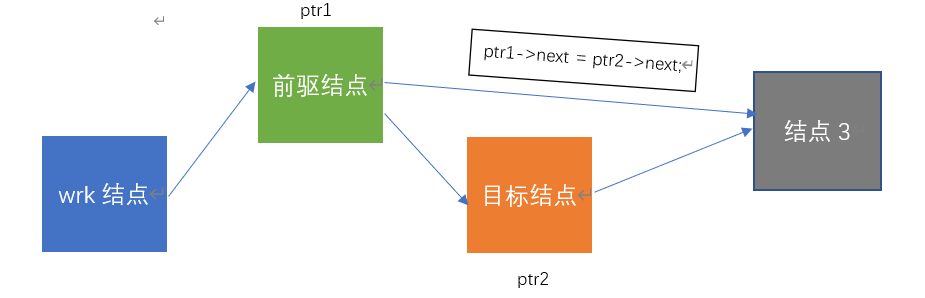
3.删除结点(这里以根据id删除结点为例)
void delete_worker(PWorker wrk ,int id)
{
PWorker ptr1,ptr2; //ptr2用于寻找id所在的目标结点,ptr1指向ptr2的前驱结点
ptr1 = wrk;
ptr2 = wrk->next;
while(ptr2)
{
if(ptr2->id == id)
{
//找到目标结点,退出循环
break;
}
ptr1 = ptr1->next;
ptr2 = ptr2->next;
}
if(ptr2)
{
ptr1->next = ptr2->next; //前驱结点指针域指向目标结点的下一个结点
free(ptr2); //释放目标结点
ptr2 = NULL;
}
else
{
printf("工号%d不存在!\n",id);
}
}
4.查询链表中的数据
void print_worker(const PWorker wrk)
{
PWorker prt = wrk->next; //从头结点的下个结点开始查询
printf("========= 工人基本信息 ===============\n");
printf("姓名\t工号\t年龄\t工资\n");
printf("--------------------------------------\n");
for (; prt; prt = prt->next)
{
printf("%s\t%d\t%d\t%.2f\n",
prt->name, prt->id, prt->age, prt->salary);
}
printf("======================================\n");
}5.修改某个结点的数据(这里以根据id修改工资为例)
void revise_worker(PWorker wrk,int id,float salary)
{
PWorker ptr = wrk->next;
while(ptr)
{
if(ptr->id==id)
{
ptr->salary = salary;
return;
}
ptr = ptr->next;
}
printf("工号%d不存在!\n",id);
}以上就是链表的“初始化”和“增删查改”的基本用法,希望可以给您带来帮助。
















 2741
2741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











