






以下文章来源于智能语音新青年 ,作者ttslr

论文地址:
https://arxiv.org/pdf/2309.07525.pdf
![]()
合成歌声的兴起给艺术家和行业利益相关者带来了未经授权使用歌声的严峻挑战。与合成语音不同,合成歌声通常是在含有强烈背景音乐的歌曲中发布的,而强烈的背景音乐可能会掩盖合成人工痕迹。此外,歌声还具有不同于语音的声学和语言特点。这些独特的特性使得歌声深度伪造检测成为一个相关但又与合成语音检测明显不同的问题。在这项工作中,我们提出了歌声深度伪造检测任务。我们首先介绍了 SingFake,它是第一个经过精心策划的野生数据集,由 28.93 小时的真实歌曲片段和 29.40 小时的深度伪造歌曲片段组成,这些片段来自 40 位歌手的五种语言。我们将数据集分为训练/评估/测试三部分,其中测试集包括各种场景。然后,我们使用 SingFake 评估了在语音语篇基础上训练的四种最先进的语音对抗系统。我们发现这些系统在语音测试数据上的表现明显落后。当在 SingFake 上使用分离的声轨或歌曲混音进行训练时,这些系统的性能有了大幅提高。然而,我们的评估也发现了与未见歌手、通信编解码器、语言和音乐背景相关的挑战,这就要求对歌唱声音深度伪造检测进行专门研究。
![]()
随着歌声合成技术的发展,人工智能生成的歌声听起来越来越自然,与乐谱非常吻合,只需少量训练数据就能克隆任何歌手的声音。VISinger [2] 和 DiffSinger [3] 等开源歌声合成和歌声转换项目使这些技术更容易获取。这些技术及其广泛的可获取性引起了艺术家、唱片公司和出版社的关注。例如,未经授权模仿歌手的合成作品可能会损害歌手的商业价值,从而导致潜在的版权和许可纠纷。越来越多的社会忧虑凸显了开发精确检测深度伪造歌声方法的紧迫性。
由于歌声是人类发声的一种类型,因此可以直观地从类似的研究领域探索解决方案,即语音深度伪造检测,通常称为语音欺骗对策(CM)。现有的研究一直在探索不同的方法来辨别语音欺骗攻击和真实的人类语音。近年来取得了重大进展。当代最先进的系统表现出了值得称道的性能,其中一些系统 [4, 5, 6] 在 ASVspoof2019 [7] 测试分区上实现了低于 1% 的等效错误率 (EER)。然而,CM 系统在未见攻击和不同声学环境下仍存在泛化问题,在野外数据[8, 9]上进行评估时表现出明显的退化。
另一方面,歌唱声音的深层伪造检测则提出了一系列与语音不同的挑战。首先,与语音不同,歌声通常遵循特定的旋律或节奏模式,这对不同音素的音高和持续时间有很大影响。其次,与说话相比,歌手在唱歌时往往会使用更多的艺术发声特征和更广泛的音色范围;由于音乐流派种类繁多,发声特征和音色的多样性也进一步增加。最后但并非最不重要的一点是,语音信号通常是直接录音,而歌唱声音通常经过大量数字信号处理,并与乐器伴奏混合在一起。认识到检测欺骗性歌声所面临的这些独特挑战,我们对针对语音开发的对策能否直接应用于欺骗性歌声检测提出了疑问。
在本文中,我们提出了歌唱语音深度伪造检测(SVDD)任务。第一步,我们策划了第一个名为 SingFake 的野生数据集来支持这项任务。SingFake 数据集包含 28.93 个小时的真实歌曲片段和 29.40 个小时的深度伪造歌曲片段,这些片段来自流行的用户生成内容平台。我们收集了来自 40 位不同歌手及其人工智能对应版本的片段,涵盖五种语言。此外,我们还使用源分离模型(Demucs [10])从歌曲混音中提取演唱人声,从而分别检验演唱人声和歌曲混音对 SVDD 系统的影响。我们还提供了训练/评估/测试拆分,其中测试集包含一系列不同的场景,包括未见过的歌手、语言、通信编解码器和音乐背景。通过 SingFake,我们对四种领先的语音对抗系统进行了评估。我们首先使用它们在语音语篇上预训练的模型,然后在 SingFake 的测试分集上对其进行测试。结果显示,与它们在 ASVspoof2019 基准上的性能相比,它们在歌曲混音和分离人声上的性能都有明显下降。然后,我们在两种条件下,即在分离的人声音轨和混合歌曲上,对这些系统在 SingFake 的训练分段上进行了重新训练,并在测试分段上进行了测试。结果表明,与在语音数据上训练的模型相比,它们有了明显的改进。对结果进行的更详细分析揭示了与未见过的歌手、通信编解码器、语言和音乐背景相关的挑战,突出表明有必要开展更有针对性的研究,以制作出强大的歌唱声音深度伪造检测系统。
在撰写本稿件的过程中,我们发现了另一项最新研究[11],该研究评估了语音 CMs 在中文歌曲的清唱声和混合声与器乐中的表现。该研究深入探讨了语音 CM 在受控理想条件下学习深度伪造线索的能力,而我们的工作则侧重于更具挑战性的野外场景。
![]()
![]()
我们从公开的流行用户生成内容网站上获取deepfake 歌曲样本,在这些网站上,用户上传了真实和deepfake 歌曲样本。对于每个 deepfake 歌曲样本,我们都会手动标注其元数据:人工智能歌手、语言、网站,并将其标记为 "deepfake "歌曲。如果披露了 deepfake 生成模型,我们也会对其进行标注。然后,我们从相应的真实歌手那里收集真实样本,并将其标注为 "真实"。在注释过程中,我们发现大多数人使用的 SoftVC-VITS2 版本各不相同。同一上传者通常使用同一模型生成人工智能歌手。由于手动标注是一个繁琐且容易出错的过程,为了确保元数据标签的准确性并纠正潜在的不准确性,我们采用 GPT4 [12] 来根据歌曲标题和描述验证注释。然后,我们对 GPT4 发现的任何差异进行人工审核。这一过程产生了我们的 SingFake 数据集,它捕捉到了网络社区中普遍存在的真实的深度伪造细微差别。SingFake 包含 40 位真正的歌手及其相应的人工智能歌手,其中有 634 首真实歌曲和 671 首多语言深度伪造歌曲。
![]()
我们的首要准则是确保每个部分的歌手都是不同的;因此,我们将数据分为训练/评估/测试三个部分。此外,为了全面评估 SVDD 系统的鲁棒性,我们采用了难度不断增加的测试子集 T01-T04。值得注意的是,有许多样本来自歌手 "Stefanie Sun",因此我们将其中的一部分留了出来,创建了 T01 测试场景,以评估系统在训练中见过的歌手身上的表现。T02 测试集包含 6 位未见过的训练歌手,而 T03 测试条件通过 4 种压缩编解码器传输 T02,模拟有损通信信道的影响:MP3 128 Kbps、AAC 64 Kbps、OPUS 64 Kbps 和 Vorbis 64 Kbps。波斯语歌手的音乐风格不同,但主要包含波斯语,因此脱颖而出。为了研究语言和音乐风格的潜在差异的影响,我们将波斯语歌手分配到一个单独的 T04 测试集中。由于 T04 是在与其他测试条件不同的平台上收集的,我们认为 T04 也包含了未见过的编解码器。
数据集的其余部分分为训练集和验证集,训练集、验证集、T01 和 T02 子集之间的歌曲比例大致为 6:1:1:2。这些子集共同提供了对歌声深度伪造检测系统的全面评估。图 1 中用不同颜色说明了最终的分区。
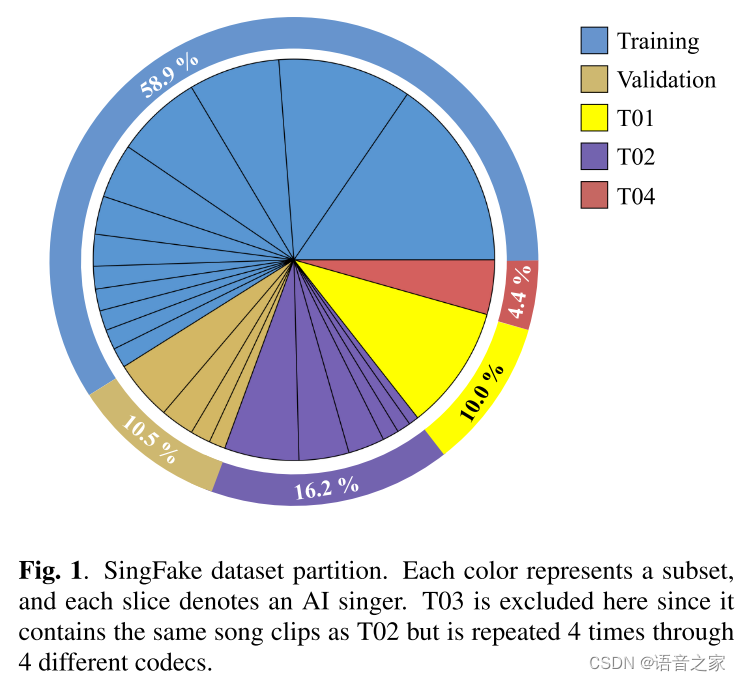
![]()
我们收集的大部分数据都是流行歌曲,这些歌曲通常既有器乐部分,如前奏、尾声和间奏;也有包含人声的部分,如歌词和副歌。就歌声深度伪造检测而言,我们的主要兴趣在于包含歌声的部分,因为只有歌声是合成的,因此纯乐器部分与 SVDD 任务无关。因此,我们将重点缩小到有主动演唱的区域,将每个区域视为一个不同的歌曲片段。
为了提取活跃区域,我们首先采用了最先进的音乐源分离模型 Demucs [10],该模型基于 U-Net 卷积架构。该模型擅长将鼓、贝斯和人声从其他伴奏中分离出来。我们使用了它的开源实现3,并特别使用了在 MusDB [13] 数据集上训练的检查点和额外的训练数据。值得注意的是,该检查点在 MDX 挑战赛[14]的 B 赛道中获得了第二名的好成绩。我们使用 Demucs 分离出的人声作为分离歌曲片段的来源。
接下来,分离出的人声将通过 PyAnnote [15] 中的语音活动检测(VAD)管道进行处理,为我们提供用于分割的时间码。这些时间码随后被用于将混音和人声分割成单独的歌曲片段。在训练和推理过程中,所有片段都被重新采样至 16 kHz。对于那些原本为立体声的歌曲,我们保持了立体声的质量,但在训练过程中为每个片段随机选择了一个声道。数据集中片段的平均长度为 13.75 秒。
表 1 显示了所有子集的最终统计数据,包括片段级的分割数据。我们开源了数据表,包括用户上传的原始媒体链接和我们的元数据注释、数据集分割生成和数据处理代码4。

![]()
在本节中,我们首先使用 SingFake 评估现有的语音欺骗反制系统。随后,我们使用 SingFake 训练集对这些系统进行从头开始的重新训练,并使用我们的数据集分集评估它们在各种测试场景中的性能。
![]()
我们构建了四个最先进的系统,这些系统在语音数据集上表现出色,代表了不同层次的输入特征抽象。这样,我们就能评估这些特征在语音和歌曲伪造检测任务中的表现力。
模型架构:AASIST [4] 使用原始波形作为特征,利用图神经网络,并结合了谱时注意力。Spectrogram+ResNet 使用 512 点 FFT 提取的线性频谱图,跳频大小为 10 毫秒。我们将提取的频谱图输入 ResNet18 [16] 架构。LFCC+ResNet [17] 使用线性频率倒频谱系数(LFCC)作为语音特征,然后将 LFCC 输入 ResNet18 模型。从语篇的每一帧中提取 60 分贝的 LFCC,帧长设置为 20 毫秒,跳跃大小为 10 毫秒。Wav2vec2+AASIST [18] 是一个利用 Wav2Vec2 [19] 的模型,Wav2Vec2 是在大规模外部语音数据集上训练的自监督前端。请注意,为了公平比较各种方法,我们删除了原始论文 [18] 中的 RawBoost 数据增强模块,因为没有其他方法具有这种增强功能。
评估指标: 每个系统都会为每句语音打分,以表示对给定语音真实性的信心。平等错误率(EER)是通过对产生的分数设置一个阈值来确定的,以确保错误接受率与错误拒绝率相匹配。EER 是生物识别验证系统广泛使用的一个指标,我们认为它也是 SVDD 的一个很好的指标。
![]()
我们在语音数据集 ASVspoof 2019 logical access (LA) [7] 上对所有语音 CM 系统进行了 100 个历时的训练和验证。我们选择验证性能最佳的模型检查点进行评估。我们使用与 ASVspoof 2019 LA 相同的 train/dev/eval 分割。为了形成批次,我们使用了 4 秒钟的音频。对于较短的试验,我们使用重复填充;对于较长的试验,我们随机选择连续的 4 秒。如表 2 所示,所有 CM 系统在 ASVspoof 2019 LA 评估数据上都取得了良好的性能。
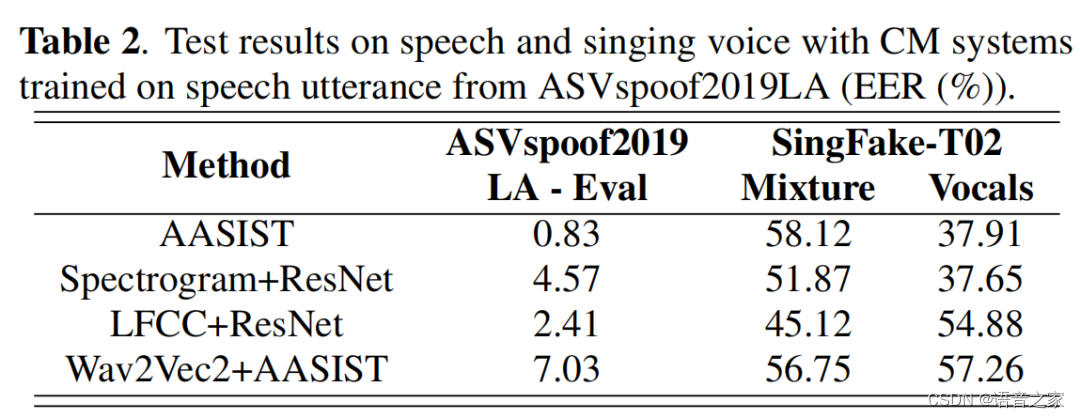
然后,我们在 SingFake 的 T02 条件下对它们进行测试,以评估它们在唱歌数据上的性能。如表 3 所示,所有系统都出现了严重的性能下降。在歌曲混音中,EER 接近 50%,这表明语音深度仿真检测系统无法在有伴奏音乐的情况下区分真实歌手和相应的人工智能歌手。有趣的是,基于频谱图和原始波形的系统在分离的歌唱人声上都达到了约 38% 的 EER,比在歌曲混合物上的结果要好得多。这可能是由于与歌曲混合物相比,歌唱人声更类似于语音,因为分离后几乎没有音乐伴奏。不过,基于 LFCC 和 Wav2Vec2 的系统的 EER 值仍接近 50%,这表明这些语音特征更倾向于过度拟合语音数据,而不能通用于歌声。
![]()
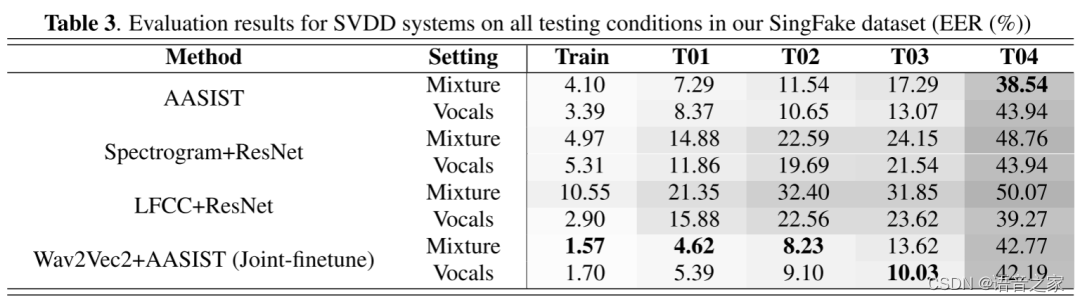
为了研究在我们制作的 SingFake 数据集上进行训练是否能提高歌声深度伪造检测(SVDD)的性能,我们在两种条件下对模型进行了训练:使用完整的歌曲混合物和分离的歌声。使用混音进行训练可提供原始信息,而使用分离人声进行训练可减少乐器干扰,但可能会引入分离假象,从而掩盖深度伪造线索。
如表 3 所示,从训练集(歌手和歌曲全部能看到)到 T01(看到的歌手,未看到的歌曲)再到 T02(未看到的歌手,未看到的歌曲),SVDD 的表现都在下降,表明任务难度在增加。所有系统都取得了良好的训练集成绩,这表明 SingFake 对学习 SVDD 任务很有帮助。我们还观察到,LFCC+ResNet 系统在混音方面的训练集性能最低,在分离人声方面的性能次之,这表明乐器干扰可能会严重损害频谱包络。然而,T02 性能的明显下降凸显了将 SVDD 推广到新歌手身上所面临的挑战。T01 性能在训练和 T02 之间下降,这表明在新歌曲中,见过的歌手的深度假唱比未见过的歌手的假唱更容易检测。
与基于语音训练的 CM 系统相比,基于 SingFake 训练的系统在 T02 的 EER 方面表现更好,这表明基于 SingFake 训练的系统在检测深层假唱方面更胜一筹。除 Wav2Vec2+AASIST 外,以分离人声训练的系统总体上比以混杂人声训练的系统性能更好。这表明,分离的歌声可以突出检测假唱的人工痕迹。
我们的结果表明,Wav2Vec2+AASIST 模型在直接从歌曲混合物中学习方面表现出色,在所有测试系统中性能和鲁棒性最出色,这与其他任务的结果类似 [18, 20] 。
![]()
训练集 T01 和 T02 代表了越来越多的歌手/歌曲片段级的分布集,而 T03 和 T04 集则旨在评估在两种具有挑战性的实际情况下的性能:未见的通信编解码器和未见的语言/音乐背景。在不同的传输和电信编解码条件下,语音 CM 系统的性能会明显下降,这一点已得到充分研究[21, 9]。然而,在 T03 条件下测试我们的系统时,性能下降的幅度并没有预期的那么大。由于社交媒体平台通常会采用多种音频压缩编解码器来更有效地串流和传输用户上传的内容,我们相信我们收集的 SingFake 数据已经使用了编解码器。因此,在训练 SVDD 系统时,模型本身就能学习形成更强大的表示方法,从而在有损音频压缩算法中实现良好的泛化。
与此同时,我们观察到所有 SVDD 系统在 T04 上的性能都有明显下降,这一点明显比 T02 和 T03 更明显。T04 和 T03 因未见语言和音乐背景而异,这表明这些属性对 SVDD 系统构成的挑战依然突出。
![]()
人工智能能够合成高度逼真的歌声,表明了技术的重大进步。然而,这种逼真性也造成了公众的不信任,有时甚至引发完全禁止此类技术的呼声,这是可以理解的。但是,停止进步很少能解决问题。我们认为,内容来源的透明度是建立公众信任的关键,对 SVDD 系统的更多研究将使用户能够对合成内容做出明智的决定。在本节中,我们将总结 SVDD 系统的优缺点。
看不见的通信编解码器。伪造语音通常是为了欺骗某人的身份或传播错误信息。相比之下,深层伪造歌声的目的可能更多是为了娱乐或新奇,而不是明确的欺骗。创作目的的不同会导致语音 CM 系统和 SVDD 系统表现出不同的行为,正如 T03 的情况所证明的那样,可能是由于在训练过程中接触到了压缩编解码器,SVDD 系统在面对未见过的压缩编解码器时表现得非常稳健。SVDD 系统的这一优势将在采用各种音频压缩算法的各种实际场景中大放异彩。
伴奏音轨的干扰。SVDD 系统需要在包含人声和器乐音轨的混音中工作,在这种情况下,器乐音轨的显著性会给检测伪人声带来挑战,因为它们可能会掩盖伪人声假象,并引入新的假象,导致系统失效。正如第 3.3 节所讨论的那样,虽然使用音源分离可以缓解这一问题,但任何不够完美的分离结果都可能无意中引入新的伪音或掩盖深伪音线索,从而使深伪音检测算法陷入困境。例如,在使用 Demucs 模型进行人声分离时,我们发现它经常将弦乐器误解为歌声。PyAnnotate 的 VAD 管道似乎也倾向于将弦乐区域归类为活跃的声音区域。这种错误分类可能会导致 T04 的性能下降,因为波斯音乐中的弦乐乐器非常丰富。要解决这种易受干扰的问题,可以开发抗干扰的 SVDD 系统,并为这一任务确定更强大的表示方法。
多样化的音乐流派。不同流派的歌声所遵循的音乐背景大相径庭,在音高、音色和节奏方面表现出的模式也大相径庭。因此,SVDD 系统可能无法适用于未见过的音乐流派。通过人工检查,我们发现 T04 子集中有许多深受嘻哈音乐影响的歌曲,而其他子集中的大多数歌曲都是摇滚和民谣。我们认为这也是导致 T04 性能下降的原因之一。由于音乐反映了不同的文化背景,不同的音乐流派很可能会出现在真实世界的 SVDD 情境中。为了解决这一问题,我们需要进一步研究如何将音乐流派效应与深层伪造线索区分开来,从而使 SVDD 系统具有更强的流派识别能力。
总之,歌唱深度伪造面临着与语音深度伪造相同的挑战:多样化的现实世界场景和来自快速生成人工智能进步的新型攻击,同时还要应对额外的音乐复杂性。我们呼吁开展更多研究工作,以提高 SVDD 系统的鲁棒性。随着 SVDD 系统的发展,我们预计它们将有助于增强人们对人工智能技术的信心,尤其是在音乐行业,从而恢复因深度伪造泛滥而受到侵蚀的信任。
![]()
在本文中,我们提出了 "歌声深度伪造检测"(SVDD)任务,并展示了 "歌声伪造 "数据集,其中包含大量不同语言和歌手的真实和深度伪造歌曲片段。我们证明,以语音为基础进行训练的先进语音 CM 系统在以歌声为基础进行评估时会出现严重的性能下降,而以歌声为基础进行再训练则会带来实质性的改进,这凸显了专业 SVDD 系统的必要性。此外,我们还评估了与未见歌手、通信编解码器、不同语言和音乐背景相关的优缺点,强调了对稳健的 SVDD 系统的需求。通过发布 SingFake 数据集和 SVDD 任务的基准系统,我们旨在推动更多研究,重点开发用于检测歌声中深度假唱的专业技术。
文翻译:内蒙古大学计算机学院2023级硕士研究生 鲜鹄鸿 (导师:刘瑞研究员)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









