







几个知识点
- 微信使用的编码集是utf8
- mybatis可以直接设置字段编码为utf8mb4,就可以直接保存微信表情了
- oracle11g不支持utf8mb4,所以通过其他方法解决,我有两种方法。
- win10、苹果手机、安卓手机都支持emoji表情utf8显示,但是win7版本的utf8不一定支持显示,原因是缺少字体集,参考https://support.microsoft.com/en-us/topic/emojis-are-not-displayed-in-office-applications-in-windows-7-bf8bc219-8ddd-485e-3b08-9026c5bb9c50
解决方案:可以下载一个字体文件seguiemj.ttf到计算机c盘C:\Windows\Fonts目录下。一般这个文件在win10系统都能找到,直接复制粘贴。并重启电脑。
注意:这是win7显示表情的问题,不是关于oracle存储微信表情emoji问题 ,请继续往下看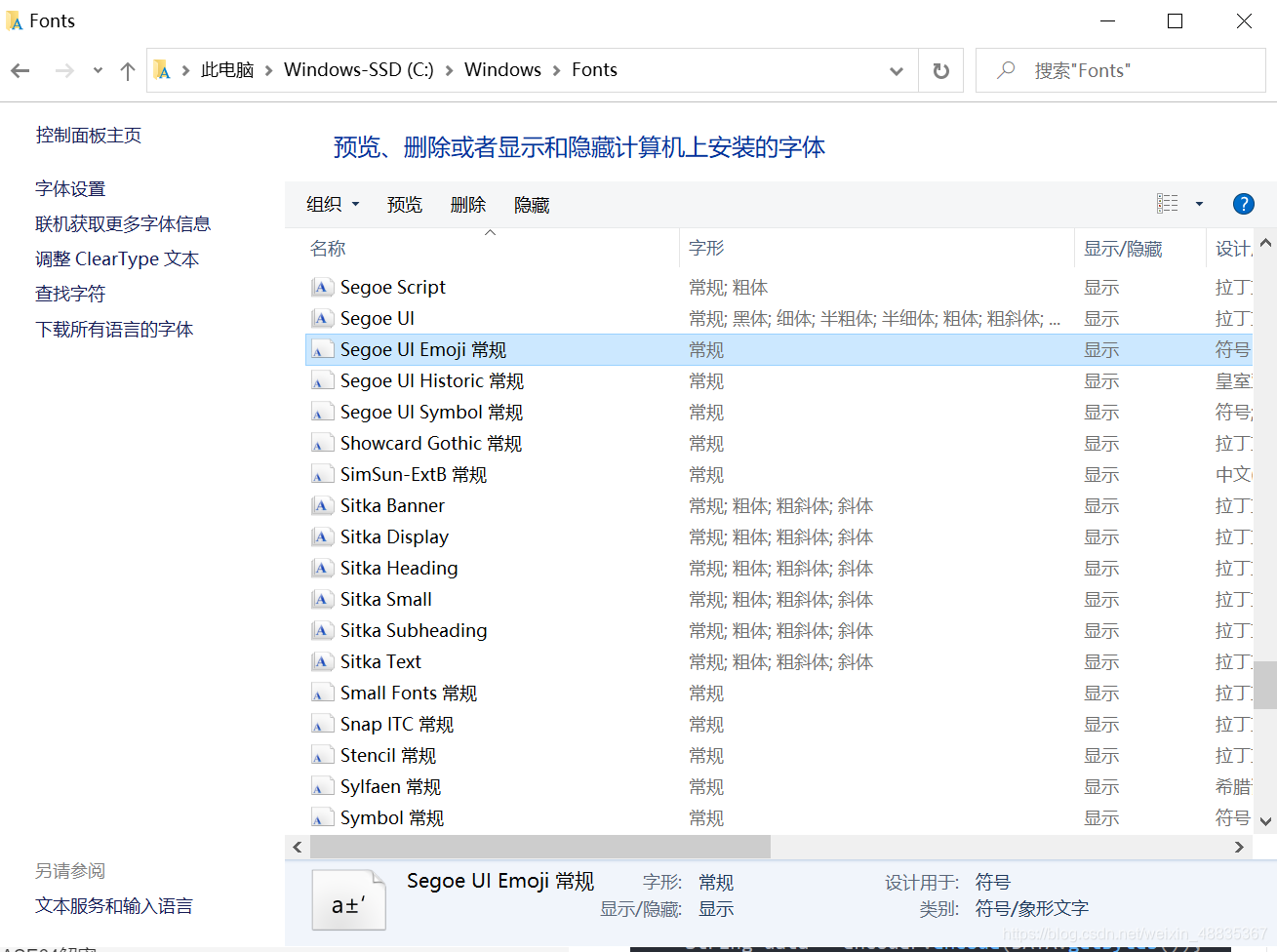
oracle存微信表情方法一
https://base64.us/
接口获取到微信表情后,使用
import java.util.Base64;
BASE64Encoder encoder = new BASE64Encoder();
String data = encoder.encode(DATA.getBytes());
System.out.println("BASE64加密:" + data);
// BASE64解密
BASE64Decoder decoder = new BASE64Decoder();
byte[] bytes = decoder.decodeBuffer(data);
System.out.println("BASE64解密:" + new String(bytes,"UTF-8"));
通过BASE64方法可以把任意字符串转换成由数字、大小写字母、等于号等组成的一套规则
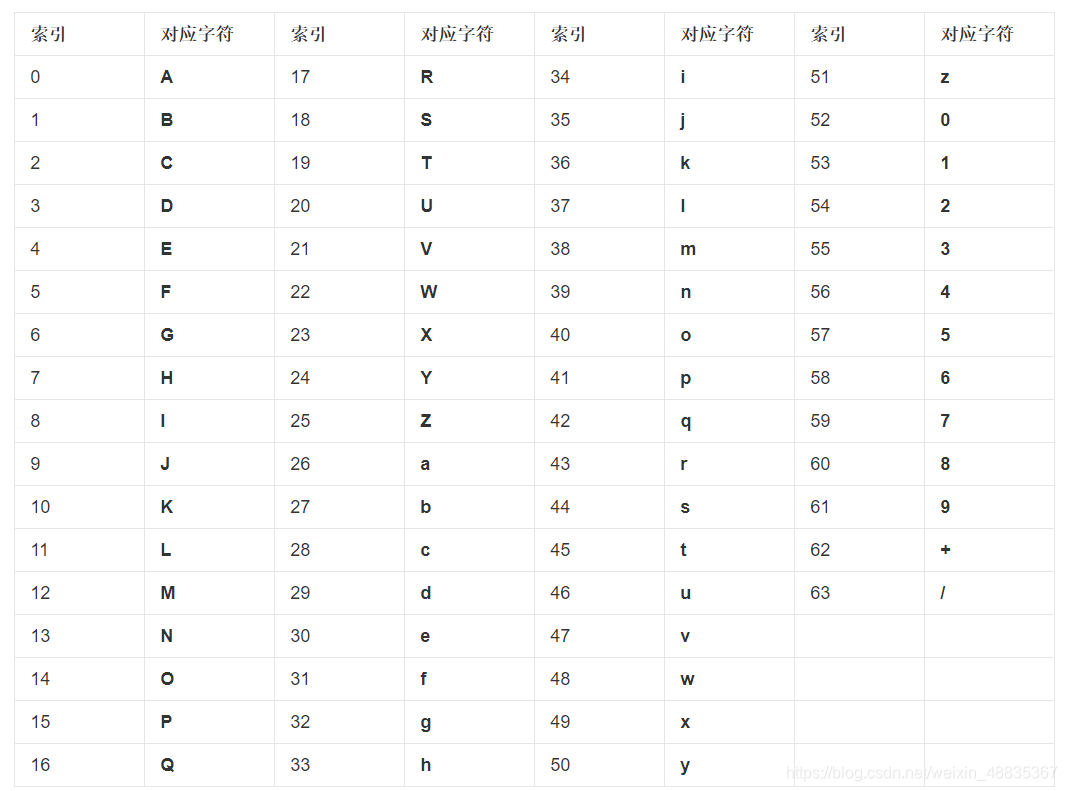
例子:编码
输入:😀
输出:7aC97biA
所以"7aC97biA"和"😀"之间是一对一映射关系

所以,可以在接口处先编码,变成"7aC97biA",把这个字符串存入到oracle。取出来用的时候解码。
oracle存微信表情方法二
一般emoji表情的utf8编码是这样编写的:
https://www.unicode-search.net/unicode-namesearch.pl?term=FACE
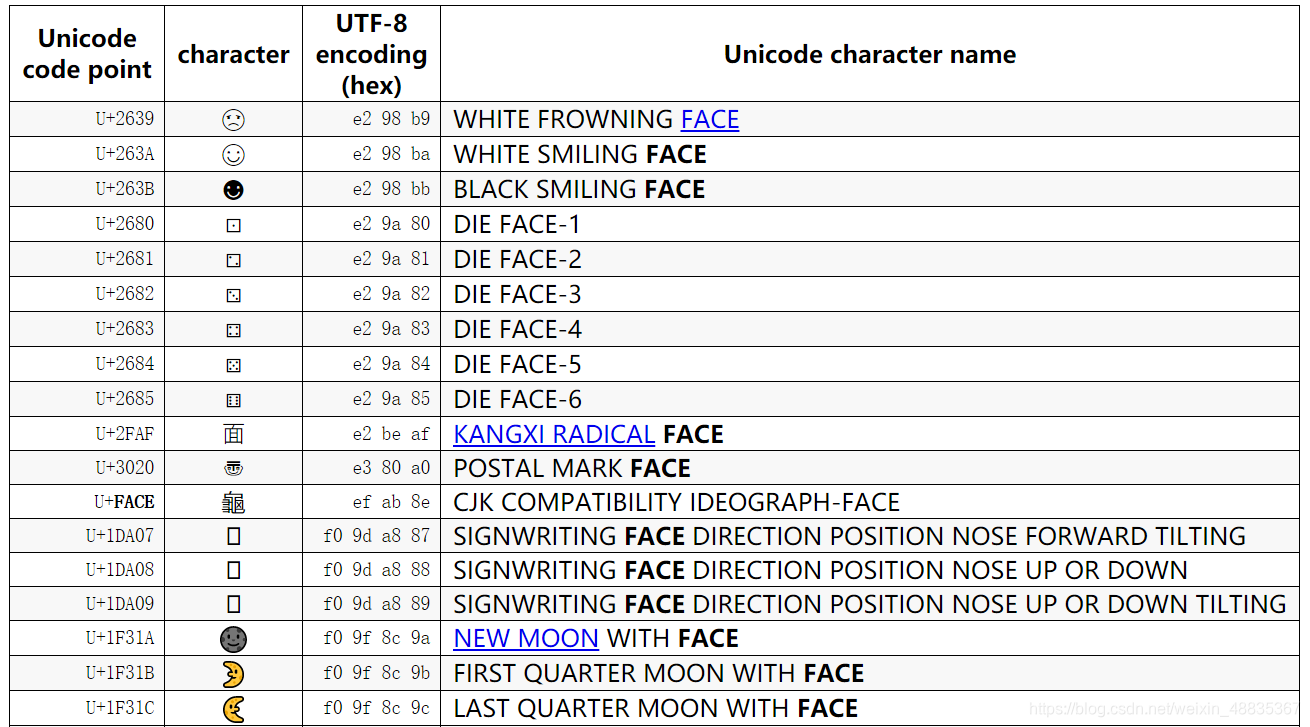
如上图所示:
表情🤪
对应的utf8底层存储是
十六进制:F0 9F A4 AA
//把十六进制转换到十进制
byte b1 = (byte) Integer.parseUnsignedInt("F0", 16);
byte b2 = (byte) Integer.parseUnsignedInt("9F", 16);
byte b3 = (byte) Integer.parseUnsignedInt("A4", 16);
byte b4 = (byte) Integer.parseUnsignedInt("AA", 16);
byte[] bytes = new byte[]{b1,b2,b3,b4};
System.out.println(new String(bytes,"UTF-8"));
上面是数组转成表情字符,下面是表情转成数组
byte[] bytes = "😀".getBytes();
for (int i = 0; i < bytes.length; i++) {
System.out.println(bytes[i]);
}
因为utf8的表情是数据是四个一组。所以可以这样存
字符串: [[%F0%9F%A4%AA]]
把这个字符串存oracle表,取用的时候按照一定规则还原成表情字符。
以下是我的把"[[%F0%9F%A4%AA]]"转成"😀"的转换规则(仅供参考)
class Test{
public static void main(String[] args) {
String sourceStr="小绵羊[[%F0%9F%A4%AA]][[%F0%9F%92%95]]";
// String sourceStr = "[[%F0%9F%92%95]]";
// String sourceStr="奥斯基";
System.out.println(getFace(sourceStr));
}
/**
* 此方法功能是:把字符串转换为表情,此表情采用utf8编码集。
* 输入小绵羊[[%F0%9F%A4%AA]],输出小绵羊🤪
* @param sourceStr 输入值,表中字段:微信昵称nickname
* @return
*/
public static String getFace(String sourceStr) {
try {
StringBuilder returnStr = new StringBuilder();
if (zhengzeFun(sourceStr)) {
boolean flag = false;
for (int i = 0; i < sourceStr.length(); i++) {
char c = sourceStr.charAt(i);
if (c=='[' && i <= sourceStr.length()-16 && sourceStr.charAt(i+1)=='['){
String substring = sourceStr.substring(i + 2, i + 2 + 12);
if (zhengzeFun(substring)){
flag = true;
returnStr.append(addFace(substring));
// System.out.println(substring);
// System.out.println(returnStr);
}
}else {
if (!flag || (c==']' && sourceStr.charAt(i-1)==']')){
if(flag){
flag = false;
continue;
}
returnStr.append(c);
}
}
}
return returnStr.toString();
}else {
return sourceStr;
}
}catch (Exception e){
return sourceStr;
}
}
//正则匹配判断是否含有[[%F0%9F%A4%AA]]
private static boolean zhengzeFun(String s) throws Exception{
String pattern = ".*" +
"%[a-z0-9A-Z][a-z0-9A-Z]" +
"%[a-z0-9A-Z][a-z0-9A-Z]" +
"%[a-z0-9A-Z][a-z0-9A-Z]" +
"%[a-z0-9A-Z][a-z0-9A-Z].*";
// System.out.println(pattern);
return java.util.regex.Pattern.matches(pattern, s);
}
//把单个[[%F0%9F%A4%AA]]转换成表情
private static String addFace(String s) throws Exception{
String[] split = s.split("%");
// System.out.println("addFace===="+s);
byte[] bytes = new byte[4];
for (int i = 1; i < split.length; i++) {
byte parseUnsignedInt = (byte) Integer.parseUnsignedInt(split[i], 16);
bytes[i-1] = parseUnsignedInt;
// System.out.println("i:"+i+", 0x:"+split[i]+", 10:"+Integer.parseUnsignedInt(split[i],16)+", 2:"+(byte) Integer.parseUnsignedInt(split[i],16));
}
String returnString = "";
try {
returnString = new String(bytes, "UTF-8");
// System.out.println("转换到表情:"+new String(bytes,"utf8"));
} catch (Exception e) {
System.out.println("转换表情失败,addFace方法失败");
}
return returnString;
}
}














 1085
1085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









