






目录
部署
下载解压
其他系统参数配置:
- 建议关闭交换区,消除交换内存到虚拟内存时对性能的扰动。
echo 0 | sudo tee /proc/sys/vm/swappiness
- 建议使用 Overcommit,将
cat /proc/sys/vm/overcommit_memory设置为1。
echo 1 | sudo tee /proc/sys/vm/overcommit_memory
下载StarRocks:镜舟数据库 - 构建极速统一的湖仓分析新范式
StarRocks 解压二进制安装包
tar -xzvf StarRocks-x.x.x.tar.gz
配置启动FE节点
进入 StarRocks-x.x.x/fe 路径。
cd StarRocks-x.x.x/fe
创建 FE 节点中的元数据路径 meta。
mkdir -p meta
运行以下命令启动 FE 节点。
bin/start_fe.sh --daemon
通过以下方式验证 FE 节点是否启动成功:
1.通过查看日志 log/fe.log 确认 FE 是否启动成功。
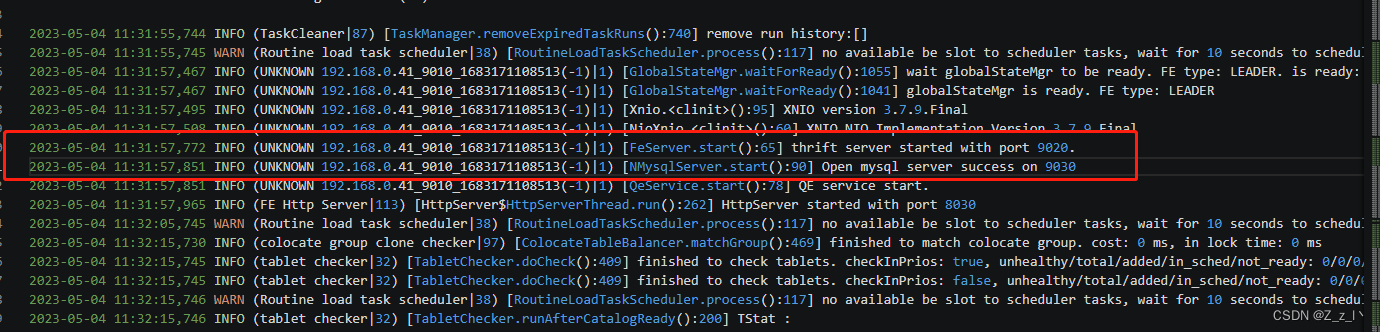
2023-05-04 11:31:57,772 INFO (UNKNOWN 192.168.0.41_9010_1683171108513(-1)|1) [FeServer.start():65] thrift server started with port 9020.
// FE 节点启动成功。
2023-05-04 11:31:57,851 INFO (UNKNOWN 192.168.0.41_9010_1683171108513(-1)|1) [NMysqlServer.start():90] Open mysql server success on 9030
// 可以使用 MySQL 客户端通过 `9030` 端口连接 FE。
2. 通过运行 jps 命令查看 Java 进程,确认 StarRocksFE 进程是否存在。

3.通过在浏览器访问 FE ip:port(默认 http_port 为 8030),进入 StarRocks 的 WebUI,用户名为 root,密码为空。
在 FE 进程启动后,使用 MySQL 客户端连接 FE 实例。
mysql -h 127.0.0.1 -P9030 -uroot
查看 FE 状态。
SHOW PROC '/frontends'\G
mysql> SHOW PROC '/frontends'\G
*************************** 1. row ***************************
Name: 192.168.0.41_9010_1683171108513
IP: 192.168.0.41
EditLogPort: 9010
HttpPort: 8030
QueryPort: 9030
RpcPort: 9020
Role: LEADER
ClusterId: 417845342
Join: true
Alive: true
ReplayedJournalId: 3047
LastHeartbeat: 2023-05-04 14:23:10
IsHelper: true
ErrMsg:
StartTime: 2023-05-04 11:31:57
Version: 3.0.0-RC02-84d70fd
1 row in set (0.02 sec)
运行以下命令停止 FE 节点。
./bin/stop_fe.sh --daemon
配置启动BE节点
进入 StarRocks-x.x.x/be 路径。
cd StarRocks-x.x.x/be
创建 BE 节点中的数据路径 storage。
mkdir -p storage
通过 MySQL 客户端将 BE 节点添加至 StarRocks 集群。
mysql> ALTER SYSTEM ADD BACKEND "host:port";
如添加过程出现错误,需要通过以下命令将该 BE 节点从集群移除。
mysql> ALTER SYSTEM decommission BACKEND "host:port";
运行以下命令启动 BE 节点。
bin/start_be.sh --daemon
通过 MySQL 客户端确认 BE 节点是否启动成功。
SHOW PROC '/backends'\G
mysql> SHOW PROC '/backends'\G
*************************** 1. row ***************************
BackendId: 11477
IP: 192.168.0.41
HeartbeatPort: 9050
BePort: 9060
HttpPort: 8040
BrpcPort: 8060
LastStartTime: 2023-05-04 13:06:21
LastHeartbeat: 2023-05-04 14:29:20
Alive: true
SystemDecommissioned: false
ClusterDecommissioned: false
TabletNum: 30
DataUsedCapacity: 0.000
AvailCapacity: 26.540 GB
TotalCapacity: 39.246 GB
UsedPct: 32.38 %
MaxDiskUsedPct: 32.38 %
ErrMsg:
Version: 3.0.0-RC02-84d70fd
Status: {"lastSuccessReportTabletsTime":"2023-05-04 14:29:21"}
DataTotalCapacity: 26.540 GB
DataUsedPct: 0.00 %
CpuCores: 2
NumRunningQueries: 0
MemUsedPct: 0.49 %
CpuUsedPct: 0.9 %
1 row in set (0.01 sec)
运行以下命令停止 BE 节点。
./bin/stop_be.sh --daemon
查询数据源
Catalog
概述
本文介绍什么是 Catalog, 以及如何使用 Catalog 管理和查询内外部数据。
内部数据:指保存在 StarRocks 中的数据。
外部数据:指保存在外部数据源(如 Apache Hive™、Apache Iceberg、Apache Hudi、Delta Lake、JDBC)中的数据。
Catalog
StarRocks 2.3 及以上版本支持 Catalog(数据目录)功能,方便您轻松访问并查询存储在各类外部源的数据。当前 StarRocks 提供两种类型 Catalog:internal catalog 和 external catalog。

Internal catalog: 内部数据目录,用于管理 StarRocks 所有内部数据。例如,执行 CREATE DATABASE 和 CREATE TABLE 语句创建的数据库和数据表都由 internal catalog 管理。 每个 StarRocks 集群都有且只有一个 internal catalog 名为 default_catalog。
External catalog: 外部数据目录,用于连接外部 metastore。在 StarRocks 中,您可以通过 external catalog 直接查询外部数据,无需进行数据导入或迁移。当前支持创建以下类型的 external catalog:
Hive catalog:用于查询 Hive 数据。
Iceberg catalog:用于查询 Iceberg 数据。
Hudi catalog:用于查询 Hudi 数据。
Delta Lake catalog:用于查询 Delta Lake 数据。
JDBC catalog:用于查询 JDBC 数据源的数据。
使用 external catalog 查询数据时,StarRocks 会用到外部数据源的两个组件:
元数据服务:用于将元数据暴露出来供 StarRocks 的 FE 进行查询规划。
存储系统:用于存储数据。数据文件以不同的格式存储在分布式文件系统或对象存储系统中。当 FE 将生成的查询计划分发给各个 BE 后,各个 BE 会并行扫描 Hive 存储系统中的目标数据,并执行计算返回查询结果。
访问 Catalog
您可以使用SET CATALOG 切换当前会话里生效的 Catalog,然后通过该 Catalog 查询数据。
SET CATALOG:
语法
SET CATALOG <catalog_name>
参数
catalog_name:当前会话里生效的 Catalog,支持 Internal Catalog 和 External Catalog。 如果指定的目录不存在,则会引发异常。
示例
通过如下命令,切换当前会话里生效的 Catalog 为 Hive Catalog hive_metastore:
SET CATALOG hive_metastore;
通过如下命令,切换当前会话里生效的 Catalog 为 Internal Catalog default_catalog:
SET CATALOG default_catalog;
查询数据
查询内部数据
如要查询存储在 StarRocks 中的数据,请参见Default catalog
查询外部数据
如要查询存储在外部数据源中的数据,请参见查询外部数据
跨 catalog 查询数据
如想在一个 catalog 中查询其他 catalog 中数据,可通过 catalog_name.db_name 或 catalog_name.db_name.table_name 的格式来引用目标数据。举例:
在 default_catalog.olap_db 下查询 hive_catalog 中的 hive_table。
SELECT * FROM hive_catalog.hive_db.hive_table;
Default catalog
本节介绍什么是 Default Catalog,以及如何使用 Default Catalog 查询 StarRocks 内部数据。
StarRocks 2.3 及以上版本提供了 Internal Catalog(内部数据目录),用于管理 StarRocks 的内部数据。每个 StarRocks 集群都有且只有一个 Internal Catalog,名为 default_catalog。StarRocks 暂不支持修改 Internal Catalog 的名称,也不支持创建新的 Internal Catalog。
查询内部数据
1.连接 StarRocks。
如从 MySQL 客户端连接到 StarRocks。连接后,默认进入到 default_catalog。
如使用 JDBC 连接到 StarRocks,连接时即可通过 default_catalog.db_name 的方式指定要连接的数据库。
2.(可选)通过 SHOW DATABASES 查看数据库:
SHOW DATABASES;
或
SHOW DATABASES FROM default_catalog;
3.(可选)通过 SET CATALOG 切换当前会话生效的 Catalog:
SET CATALOG <catalog_name>;
再通过 USE 指定当前会话生效的数据库:
USE <db_name>;
或者,也可以通过 USE 直接将会话切换到目标 Catalog 下的指定数据库:
USE <catalog_name>.<db_name>;
4.通过 SELECT 查询内部数据:
SELECT * FROM <table_name>;
如在以上步骤中未指定数据库,则可以在查询语句中直接指定。
SELECT * FROM <db_name>.<table_name>;
或
SELECT * FROM default_catalog.<db_name>.<table_name>;
示例
如要查询 olap_db.olap_table 中的数据,操作如下:
USE olap_db;
SELECT * FROM olap_table limit 1;
或
SELECT * FROM olap_db.olap_table limit 1;
或
SELECT * FROM default_catalog.olap_db.olap_table limit 1;
JDBC catalog
JDBC Catalog 是一种 External Catalog。通过 JDBC Catalog,您不需要执行数据导入就可以直接查询 JDBC 数据源里的数据。
此外,您还可以基于 JDBC Catalog ,结合 INSERT INTO 能力对 JDBC 数据源的数据实现转换和导入。
StarRocks 从 3.0 版本开始支持 JDBC Catalog,目前正在公测中。
目前 JDBC Catalog 支持 MySQL 和 PostgreSQL。
创建 JDBC Catalog
语法
CREATE EXTERNAL CATALOG <catalog_name>
[COMMENT <comment>]
PROPERTIES ("key"="value", ...)
参数说明
catalog_name
JDBC Catalog 的名称。命名规则如下:
可以包含字母、数字 0 到 9 和下划线 (_),并且必须以字母开头。
长度不能超过 64 个字符。
comment
JDBC Catalog 的描述。此参数为可选。
PROPERTIES
JDBC Catalog 的属性,包含如下必填配置项:
| 参数 | 说明 |
| type | 资源类型,固定取值为 jdbc。 |
| user | 目标数据库登录用户名。 |
| password | 目标数据库用户登录密码。 |
| jdbc_uri | JDBC 驱动程序连接目标数据库的 URI。如果使用 MySQL,格式为:"jdbc:mysql://ip:port"。如果使用 PostgreSQL,格式为 "jdbc:postgresql://ip:port/db_name"。参见 MySQL 和 PostgreSQL 官网文档。 |
| driver_url | 用于下载 JDBC 驱动程序 JAR 包的 URL。支持使用 HTTP 协议或者 file 协议,例如https://repo1.maven.org/maven2/org/postgresql/postgresql/42.3.3/postgresql-42.3.3.jar 和 file:///home/disk1/postgresql-42.3.3.jar。说明 您也可以把 JDBC 驱动程序部署在 FE 或 BE 所在节点上任意相同路径下,然后把 driver_url 设置为该路径,格式为 file://<path>/to/the/dirver。 |
| driver_class | JDBC 驱动程序的类名称。以下是常见数据库引擎支持的 JDBC 驱动程序类名称:
|
创建示例
CREATE EXTERNAL CATALOG mysql
PROPERTIES
(
"type"="jdbc",
"user"="root",
"password"="123456",
"jdbc_uri"="jdbc:mysql://127.0.0.1:3306",
"driver_url"="https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.28/mysql-connector-java-8.0.28.jar",
"driver_class"="com.mysql.cj.jdbc.Driver"
);
查看 JDBC Catalog
您可以通过 SHOW CATALOGS 查询当前所在 StarRocks 集群里所有 Catalog:
SHOW CATALOGS;
您也可以通过 SHOW CREATE CATALOG 查询某个 External Catalog 的创建语句。例如,通过如下命令查询 JDBC Catalog jdbc0 的创建语句:
SHOW CREATE CATALOG jdbc0;
删除 JDBC Catalog
您可以通过 DROP CATALOG 删除一个 JDBC Catalog。
例如,通过如下命令删除 JDBC Catalog jdbc0:
DROP Catalog jdbc0;
查询 JDBC Catalog 中的表数据
通过 SHOW DATABASES 查看指定 Catalog 所属的集群中的数据库:
SHOW DATABASES from <catalog_name>;
通过 SET CATALOG 切换当前会话生效的 Catalog:
SET CATALOG <catalog_name>;
再通过 USE 指定当前会话生效的数据库:
USE <db_name>;
或者,也可以通过 USE 直接将会话切换到目标 Catalog 下的指定数据库:
USE <catalog_name>.<db_name>;
通过 SELECT 查询目标数据库中的目标表:
SELECT * FROM <table_name>;
查询外部数据
本文介绍如何通过 External Catalog 查询外部数据。External Catalog 方便您轻松访问并查询存储在各类外部源的数据,无需创建外部表。
操作步骤
1.连接 StarRocks。
如从 MySQL 客户端连接到 StarRocks。连接后,默认进入到 default_catalog。
如使用 JDBC 连接到 StarRocks,连接时即可通过 default_catalog.db_name 的方式指定要连接的数据库。
2.(可选)执行以下语句查看当前 StarRocks 集群中的所有 Catalog 并找到指定的 External Catalog。有关返回值说明,请参见 SHOW CATALOGS。
SHOW CATALOGS;
3.(可选)执行以下语句查看指定 external catalog 中的数据库。有关参数和返回值说明,请参见 SHOW DATABASES。
SHOW DATABASES FROM catalog_name;
4.(可选)执行以下语句将当前会话切换到指定 external catalog 的指定数据库。有关参数说明和示例,请参见 USE。
USE catalog_name.db_name;
5.查询外部数据。更多 SELECT 的使用方法,请参见 SELECT。
SELECT * FROM table_name;
如在以上步骤中未指定 external catalog 和数据库,则可以在查询语句中直接指定。示例:
SELECT * FROM catalog_name.db_name.table_name;
外部表
tarRocks 支持以外部表 (External Table) 的形式,接入其他数据源。外部表指的是保存在其他数据源中的数据表,而 StartRocks 只保存表对应的元数据,并直接向外部表所在数据源发起查询。目前 StarRocks 已支持的第三方数据源包括 MySQL、StarRocks、Elasticsearch、Apache Hive™、Apache Iceberg 和 Apache Hudi。对于 StarRocks 数据源,现阶段只支持 Insert 写入,不支持读取,对于其他数据源,现阶段只支持读取,还不支持写入。
NOTICE
从 3.0 版本起,对于查询 Hive、Iceberg、Hudi 和 JDBC 数据源的场景,推荐使用 Catalog。参见 Hive catalog、Iceberg catalog、Hudi catalog 和 JDBC catalog。
从 2.5 版本开始,查询外部数据源时支持 Data Cache,提升对热数据的查询性能。参见Data Cache。
MySQL 外部表
星型模型中,数据一般划分为维度表 (dimension table) 和事实表 (fact table)。维度表数据量少,但会涉及 UPDATE 操作。目前 StarRocks 中还不直接支持 UPDATE 操作(可以通过 Unique/Primary 数据模型实现),在一些场景下,可以把维度表存储在 MySQL 中,查询时直接读取维度表。
在使用 MySQL 的数据之前,需在 StarRocks 创建外部表 (CREATE EXTERNAL TABLE),与之相映射。StarRocks 中创建 MySQL 外部表时需要指定 MySQL 的相关连接信息,如下所示。
CREATE EXTERNAL TABLE dingtalk_process_log
(
id bigint(20),
process_code varchar(64),
remark varchar(255),
op_id varchar(56),
op_name varchar(255),
created varchar(255),
updated varchar(255)
)
ENGINE=mysql
PROPERTIES
(
"host" = "127.0.0.1",
"port" = "3306",
"user" = "root",
"password" = "123456",
"database" = "oa",
"table" = "dingtalk_process_log"
);
参数说明:
host:MySQL 连接地址
port:MySQL 连接端口号
user:MySQL 登录用户名
password:MySQL 登录密码
database:MySQL 数据库名
table:MySQL 数据库表名
Data Cache
本文介绍 Data Cache 的原理,以及如何开启 Data Cache 加速外部数据查询。
在数据湖分析场景中,StarRocks 作为 OLAP 查询引擎需要扫描 HDFS 或对象存储(下文简称为“外部存储系统”)上的数据文件。查询实际读取的文件数量越多,I/O 开销也就越大。此外,在即席查询 (ad-hoc) 场景中,如果频繁访问相同数据,还会带来重复的 I/O 开销。
为了进一步提升该场景下的查询性能,StarRocks 2.5 版本开始提供 Data Cache 功能。通过将外部存储系统的原始数据按照一定策略切分成多个 block 后,缓存至 StarRocks 的本地 BE 节点,从而避免重复的远端数据拉取开销,实现热点数据查询分析性能的进一步提升。Data Cache 仅在使用外部表(不含 JDBC 外部表)和使用 External Catalog 查询外部存储系统中的数据时生效,在查询 StarRocks 原生表时不生效。
缓存介质
StarRocks 默认以 BE 节点的机器内存作为缓存的存储介质,也支持同时使用内存和磁盘作为两级的混合存储介质。如果您的磁盘类型是 NVMe 或 SSD 等,可同时使用内存和磁盘进行缓存;如果磁盘类型为云磁盘,例如 AWS EBS,建议使用纯内存来缓存。
缓存淘汰机制
在 Data Cache 中,StarRocks 采用 LRU (least recently used) 策略来缓存和淘汰数据,大致如下:
优先从内存读取数据,如果在内存中没有找到再从磁盘上读取。从磁盘上读取的数据,会被加载到内存中。
从内存中淘汰的数据,会写入磁盘;从磁盘上淘汰的数据,会被废弃。
开启 Data Cache
Data Cache 默认关闭。如要启用,则需要在 FE 和 BE 中同时进行如下配置。
FE 配置
支持使用以下方式在 FE 中开启 Data Cache:
-
按需在单个会话中开启 Data Cache。
SET enable_scan_block_cache = true; -
为当前所有会话开启全局 Data Cache。
SET GLOBAL enable_scan_block_cache = true;
BE 配置
在每个 BE 的 conf/be.conf 文件中增加如下参数。添加后,需重启每个 BE 让配置生效。
| 参数 | 说明 |
|---|---|
| block_cache_enable | 是否启用 Data Cache。
true。 |
| block_cache_disk_path | 磁盘路径。支持添加多个路径,多个路径之间使用分号(;) 隔开。建议 BE 机器有几个磁盘即添加几个路径。配置路径后,StarRocks 会自动创建名为 cachelib_data 的文件用于缓存 block。 |
| block_cache_meta_path | Block 的元数据存储目录,可自定义。推荐创建在 $STARROCKS_HOME 路径下。 |
| block_cache_mem_size | 内存缓存数据量的上限,单位:字节。默认值为 2147483648,即 2 GB。推荐将该参数值最低设置成 20 GB。如在开启 Data Cache 期间,存在大量从磁盘读取数据的情况,可考虑调大该参数。 |
| block_cache_disk_size | 单个磁盘缓存数据量的上限,单位:字节。举例:在 block_cache_disk_path 中配置了 2 个磁盘,并设置 block_cache_disk_size 参数值为 21474836480,即 20 GB,那么最多可缓存 40 GB 的磁盘数据。默认值为 0,即仅使用内存作为缓存介质,不使用磁盘。 |
示例如下:
# 开启 Data Cache。
block_cache_enable = true
# 设置磁盘路径,假设 BE 机器有两块磁盘。
block_cache_disk_path = /home/disk1/sr/dla_cache_data/;/home/disk2/sr/dla_cache_data/
# 设置元数据存储目录。
block_cache_meta_path = /home/disk1/sr/dla_cache_meta/
# 设置内存缓存数据量的上限为 2 GB。
block_cache_mem_size = 2147483648
# 设置单个磁盘缓存数据量的上限为 1.2 TB。
block_cache_disk_size = 1288490188800
查看 Data Cache 命中情况
您可以在 query profile 里观测当前 query 的 cache 命中情况。观测下述三个指标查看 Data Cache 的命中情况:
BlockCacheReadBytes:从内存和磁盘中读取的数据量。BlockCacheWriteBytes:从外部存储系统加载到内存和磁盘的数据量。BytesRead:总共读取的数据量,包括从内存、磁盘以及外部存储读取的数据量。
示例一:StarRocks 从外部存储系统中读取了大量的数据 (7.65 GB),从内存和磁盘中读取的数据量 (518.73 MB) 较少,即代表 Data Cache 命中较少。
- Table: lineorder
- BlockCacheReadBytes: 518.73 MB
- __MAX_OF_BlockCacheReadBytes: 4.73 MB
- __MIN_OF_BlockCacheReadBytes: 16.00 KB
- BlockCacheReadCounter: 684
- __MAX_OF_BlockCacheReadCounter: 4
- __MIN_OF_BlockCacheReadCounter: 0
- BlockCacheReadTimer: 737.357us
- BlockCacheWriteBytes: 7.65 GB
- __MAX_OF_BlockCacheWriteBytes: 64.39 MB
- __MIN_OF_BlockCacheWriteBytes: 0.00
- BlockCacheWriteCounter: 7.887K (7887)
- __MAX_OF_BlockCacheWriteCounter: 65
- __MIN_OF_BlockCacheWriteCounter: 0
- BlockCacheWriteTimer: 23.467ms
- __MAX_OF_BlockCacheWriteTimer: 62.280ms
- __MIN_OF_BlockCacheWriteTimer: 0ns
- BufferUnplugCount: 15
- __MAX_OF_BufferUnplugCount: 2
- __MIN_OF_BufferUnplugCount: 0
- BytesRead: 7.65 GB
- __MAX_OF_BytesRead: 64.39 MB
- __MIN_OF_BytesRead: 0.00
示例二:StarRocks 从 data cache 读取了 46.08 GB 数据,从外部存储系统直接读取的数据量为 0,即代表 data cache 完全命中。
Table: lineitem
- BlockCacheReadBytes: 46.08 GB
- __MAX_OF_BlockCacheReadBytes: 194.99 MB
- __MIN_OF_BlockCacheReadBytes: 81.25 MB
- BlockCacheReadCounter: 72.237K (72237)
- __MAX_OF_BlockCacheReadCounter: 299
- __MIN_OF_BlockCacheReadCounter: 118
- BlockCacheReadTimer: 856.481ms
- __MAX_OF_BlockCacheReadTimer: 1s547ms
- __MIN_OF_BlockCacheReadTimer: 261.824ms
- BlockCacheWriteBytes: 0.00
- BlockCacheWriteCounter: 0
- BlockCacheWriteTimer: 0ns
- BufferUnplugCount: 1.231K (1231)
- __MAX_OF_BufferUnplugCount: 81
- __MIN_OF_BufferUnplugCount: 35
- BytesRead: 46.08 GB
- __MAX_OF_BytesRead: 194.99 MB
- __MIN_OF_BytesRead: 81.25 MB
通过have_profiling参数,能够看到当前MySQL是否支持profile操作;
SELECT @@have_profiling ;
查看是否开启profile功能(profiling=on代表开启):
mysql> show variables like '%profil%';
开启profile:
mysql> set profile=1;
开启profile之后,执行要分析的sql语句:
mysql> select * from user;
查看生成的profile信息:
mysql> show profiles;
关闭profile:
mysql> set profiling=0;















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









