







引言
网上找了很久都没有QQ音乐评论获取的有效方法,其次就是现在QQ音乐都是动态加载评论内容,所以用了一个很笨的方法获取歌曲评论:
- selenium库滚动页面
- 保存某时刻的HTML文件
- BeautifulSoup库解析保存的HTML文件
这个方法有点耗时间,并且滚动到十万条评论之后,页面会出错。但对于几千和几万评论的歌曲还是可以胜任。


这是显示十万条评论后保存的HTML文件,很大,使用python读取也很花时间(30s左右)。
解析页面
BeautifulSoup解析之后的内容。
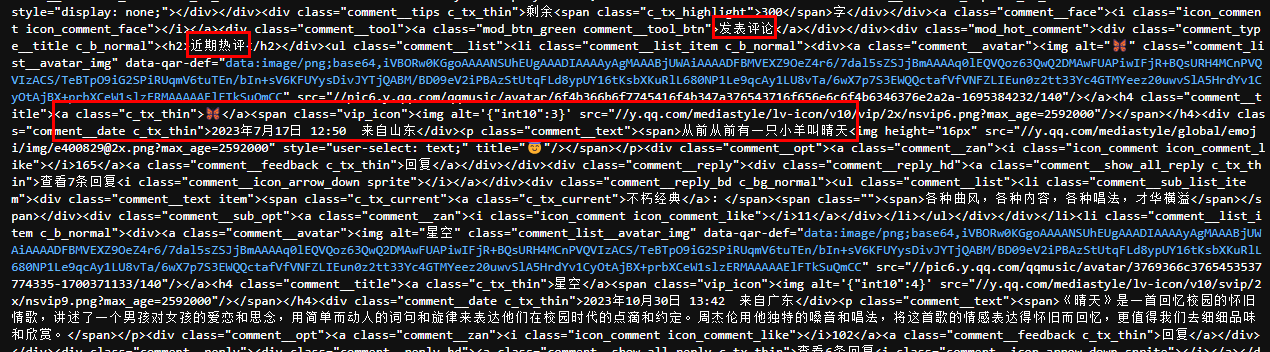
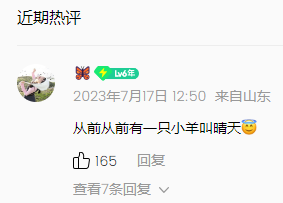
找到评论区位置后再往下找找,其实观察解析内容可以发现,蓝色的超链接是评论用户的头像,所以只需要数一下有多少条近期热评和精彩评论,就能找到全部评论的位置。
歌曲每首歌一般都是20条近期热评和精彩评论,往下数20条超链接就能找到。
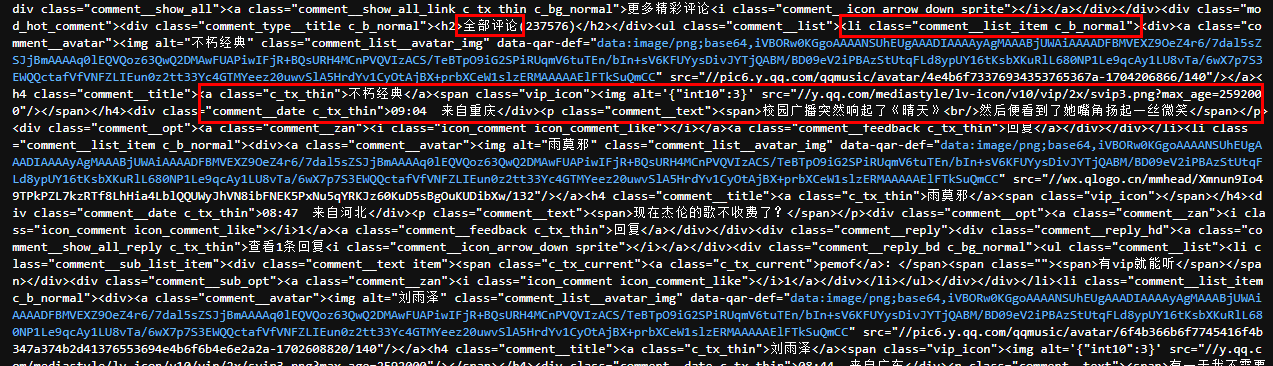
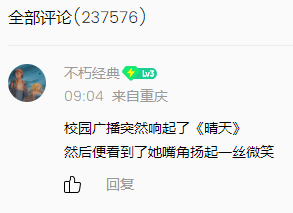
对比上下两个图片可以看到,评论是放在一个class="comment__list_item c_b_normal"的li中,使用contents=soup.find_all('li', class_='c_b_normal')找出相应内容即可。
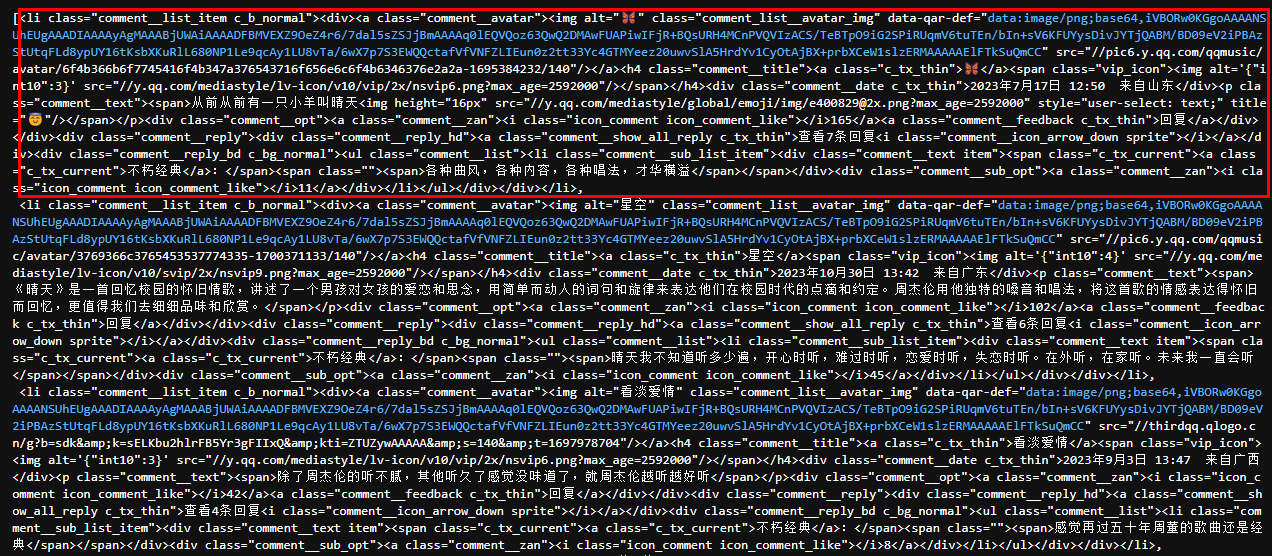
找出每隔用户评论的li之后,使用print(contents[-1].prettify())再看看具体内容在哪里。

现在可以获取相关内容。
username = contents[-1].find('a', class_='c_tx_thin').text.strip() # 提取网名
comment_content = contents[-1].find('p', class_='comment__text').text.strip() # 提取评论内容
timestamp = contents[-1].find('div', class_='comment__date').text.strip() # 提取时间、地点
split_timestamp = timestamp.split('来自', 1)
times = split_timestamp[0] # 时间
location = split_timestamp[1]
print('用户:',username)
print('评论:',comment_content)
print('时间:',times)
print('地点:',location)

完整代码
import time
import selenium
import json
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
driver = webdriver.Edge() # 创建Edge浏览器实例
driver.get(r'https://y.qq.com/n/ryqq/songDetail/0039MnYb0qxYhV') # 打开网页
try:
scroll_count = 0 #计数:没滚动60次保存一次结果
while True:
# 向下滚动2000像素
driver.execute_script("window.scrollBy(0, 2000);")
# 等待2秒
time.sleep(2)
# 增加滚动计数
scroll_count += 1
if (scroll_count%60 == 0):
# 获取当前页面的 HTML 内容并保存
name = time.strftime('%Y-%m-%d_%H:%M:%S')
path = f'QQ音乐/HTML/page.html'
page_source = driver.page_source
with open(path, 'w', encoding='utf-8') as file:
file.write(page_source)
# 打开保存的 HTML
with open(path, 'r', encoding='utf-8') as file:
html_content = file.read()
# 使用Beautiful Soup解析HTML
soup = BeautifulSoup(html_content, 'lxml')
try:
# 查找包含评论的<ul>元素
contents = soup.find_all('li', class_='c_b_normal')
# 初始化列表,用于存储四个指标的数据
data = []
# 遍历每条评论
for content in contents:
try:
username = content.find('a', class_='c_tx_thin').text.strip() # 提取网名
except:
username = '暂无数据'
try:
comment_content = content.find('p', class_='comment__text').text.strip() # 提取评论内容
except:
comment_content = '暂无数据'
try:
timestamp = content.find('div', class_='comment__date').text.strip() # 提取时间、地点
split_timestamp = timestamp.split('来自', 1)
try:
times = split_timestamp[0] # 时间
except:
times = '暂无数据'
try:
location = split_timestamp[1]
except:
location = '暂无数据'
except:
continue
# 将四个指标的数据存入字典
comment_data = {
'Username': username,
'CommentContent': comment_content,
'Time': times,
'Location': location
}
# 将字典添加到数据列表
data.append(comment_data)
# 创建DataFrame并保存
df = pd.DataFrame(data)
df.to_csv(f'QQ音乐/CSV/{name}.csv', index=False, encoding='utf8')
except:
print(f'错误{name}')
except KeyboardInterrupt:
# 捕获键盘中断(Ctrl+C),例如用户手动停止脚本
pass
finally:
# 关闭浏览器
driver.quit()
结果
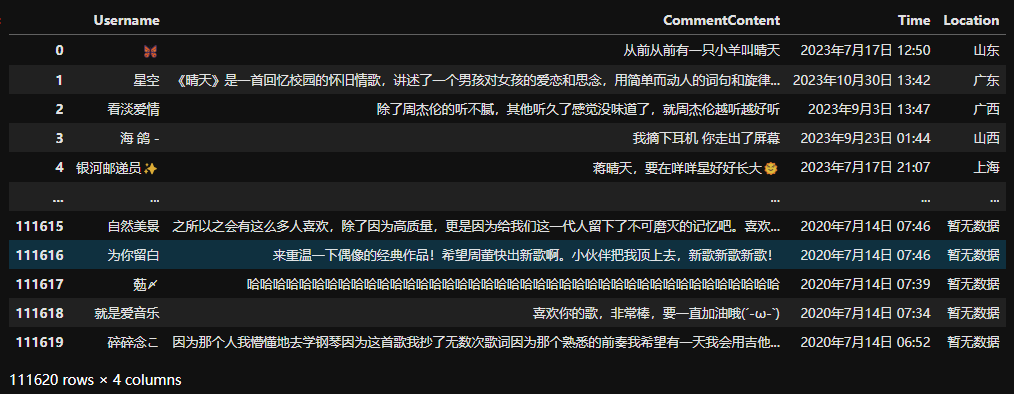
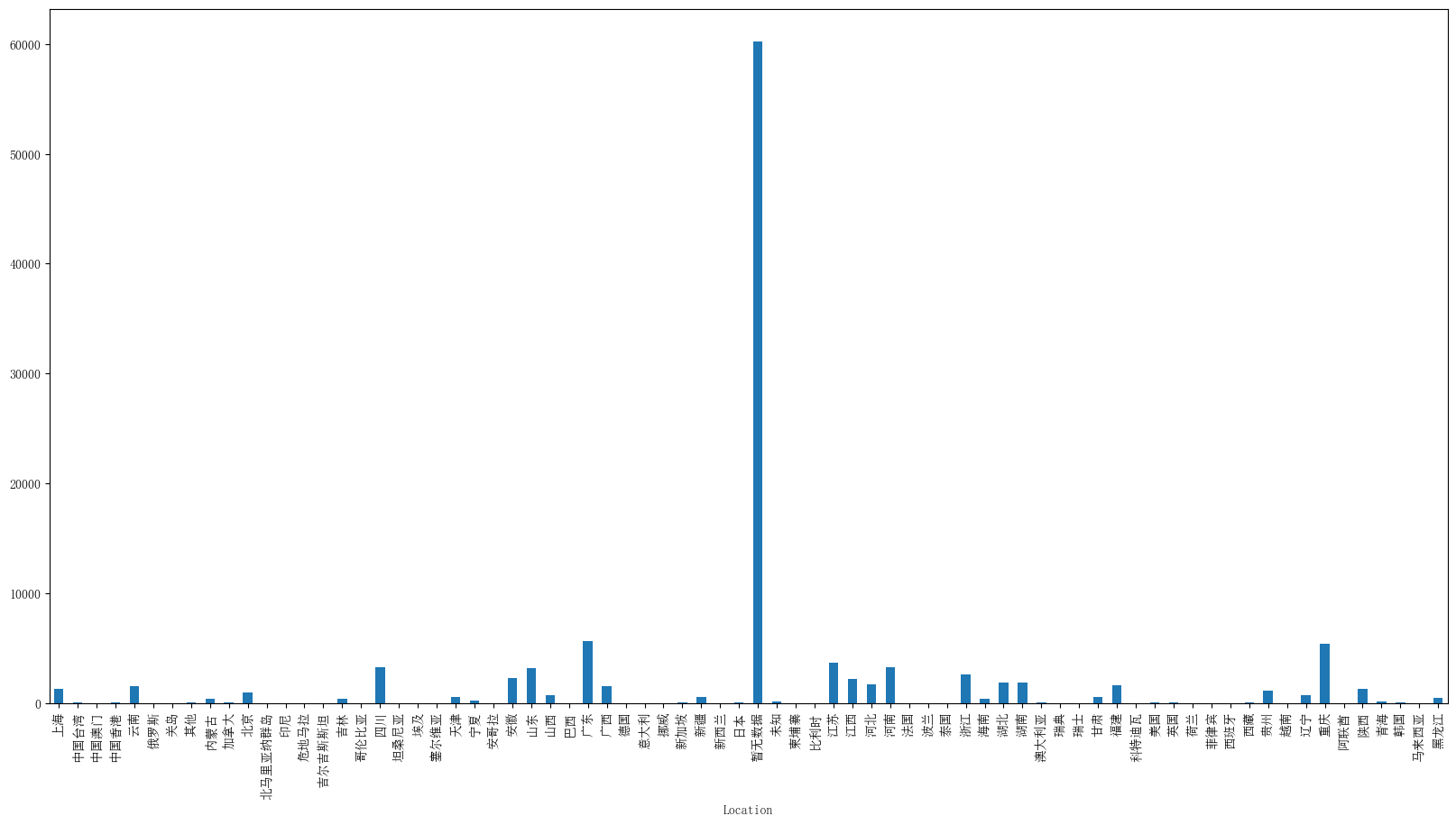
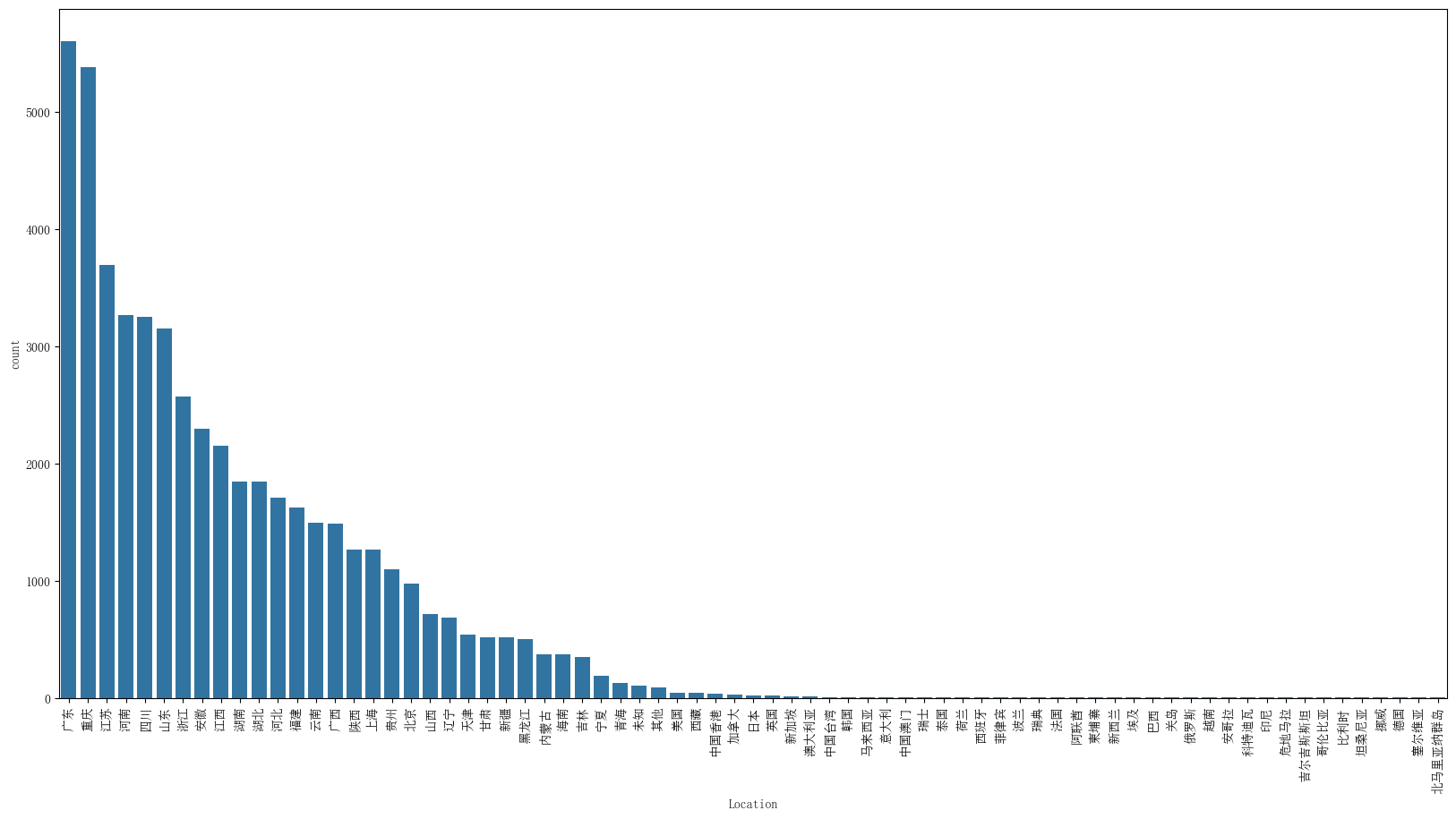


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









