









一、Movingpandas
MovingPandas是一个基于Pandas、GeoPandas和HoloViz的Python库,用于处理运动数据。 MovingPandas为运动数据探索和分析提供了轨迹数据结构和功能。
MovingPandas是为处理运动数据而开发的,更具体地说是处理轨迹,该库基于一个轨迹类及相关方法。
MovingPandas可以用于:
- 绘制轨迹
- 停止检测
- 轨迹平滑化/概括化
- 汇总大量的轨迹
本文首先对原始数据进行简单处理并入库,然后举一些处理轨迹数据的基本功能的例子。
二、数据预处理
import os
import pandas as pd
import time
from sqlalchemy import create_engine
path = 'E:\AppDownload\BaiduCloud\上海市出租车数据\Taxi_070220'
# 获取path目录下所有文件名,添加后缀.txt
file_list = os.listdir(path)
for name in file_list:
oldname = path + '\\' + name
newname = path + '\\' + name + '.txt'
os.rename(oldname, newname) # 重命名
# print(oldname, '======>', newname)
# 读取每个txt文件并写入数据库
db_name = 'trajectory' # 数据库名
file_list1 = os.listdir(path) # 获取path目录下所有文件名
for name in file_list1: # 循环读取每个文件名
file_path = path + '\\' + name
df = pd.read_csv(file_path, header=None) # 读取txt文件
df.rename(columns={0:'id',1:'date',2:'lon',3:'lat',4:'speed(km/h)',5:'direction',6:'passenger'},inplace=True) # 重命名列名
# 判断lon和lat是否全部一样
if(df['lon'].nunique() == 1 and df['lat'].nunique() == 1):
# 将同位置数据写入数据库
try:
engine = create_engine("postgresql://postgres:123@localhost:5432/" + db_name) # 连接数据库
df.to_sql('shanghai20070220_sameloc', con=engine, index=False, if_exists='append') # 第一个参数为写入数据库时的表名,没有就自动创建,有的话就自动添加数据
except Exception as e:
print(e)
finally:
engine.dispose() # 关闭数据库连接
else:
# 将不同位置数据写入数据库
try:
engine = create_engine("postgresql://postgres:123@localhost:5432/" + db_name) # 连接数据库
df.to_sql('shanghai20070220', con=engine, index=False, if_exists='append') # 第一个参数为写入数据库时的表名,没有就自动创建,有的话就自动添加数据
print(f'{name}写入数据库成功!')
except Exception as e:
print(e)
finally:
engine.dispose() # 关闭数据库连接
三、轨迹分析
用到的库
import pandas as pd
import geopandas as gpd
import movingpandas as mpd
import matplotlib.pyplot as plt
from datetime import datetime, timedelta
from mpl_toolkits.axes_grid1 import make_axes_locatable
from sqlalchemy import create_engine, text
随机提取十条轨迹数据
# 从数据库中读取数据
db_name = 'trajectory'
engine = create_engine(f'postgresql://postgres:123@localhost:5432/' + db_name) # 连接数据库
# sql = 'select * from shanghai20070220' # 查询所有数据
sql = 'select * from shanghai20070220 where id ' \
'in (select id from shanghai20070220 group by id order by random() limit 10)' # 随机查询10条数据
try:
# df = pd.read_sql_query(text(sql), engine.connect())
df = pd.read_sql(text(sql), engine.connect())
except Exception as e:
print(e)
finally:
engine.dispose() # 关闭数据库连接
数据格式转换
df['trajectory_id'] = df['id']
df['id'] = df.index
df['date'] = pd.to_datetime(df['date']) # 将时间转换为时间格式
gdf = gpd.GeoDataFrame(df, geometry=gpd.points_from_xy(df['lon'], df['lat']), crs=4326) # 将经纬度转换为几何数据
gdf.to_crs('32651', inplace=True) # 设置投影坐标系(数据来源上海市,对数据使用UTM区)
mdf = mpd.TrajectoryCollection(gdf, 'trajectory_id', t='date') # 创建轨迹集合
# 使用to_traj_gdf()方法查看轨迹数据
mdf.to_traj_gdf()
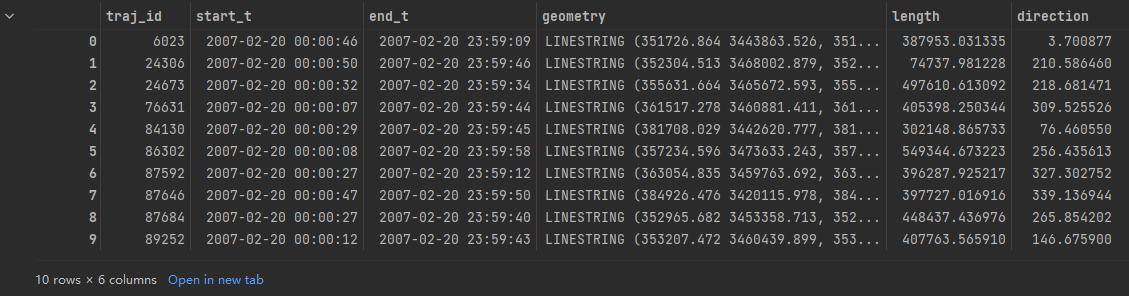
绘制gdf格式的轨迹数据:对GeoDataFrame进行绘图,我们只是有很多紧密地点放在一起的绘图
ax = gdf.plot(**plot_defaults)
ax.set_title('A trajectory consisting of points')
ax.set_xticks([])
ax.set_yticks([])
plt.show()
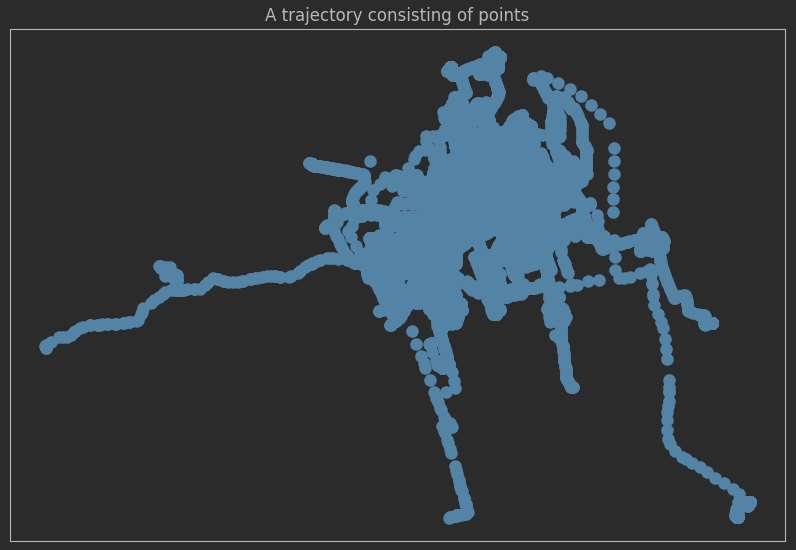
绘制mdf格式的轨迹数据:MovingPandas内置了对绘图的支持,绘制新构建的轨迹,许多点已经被转化为轨迹
# 绘制轨迹集合
ax = mdf.plot(**plot_defaults)
ax.set_title('Trajectory')
ax.set_xticks([])
ax.set_yticks([])
plt.show()
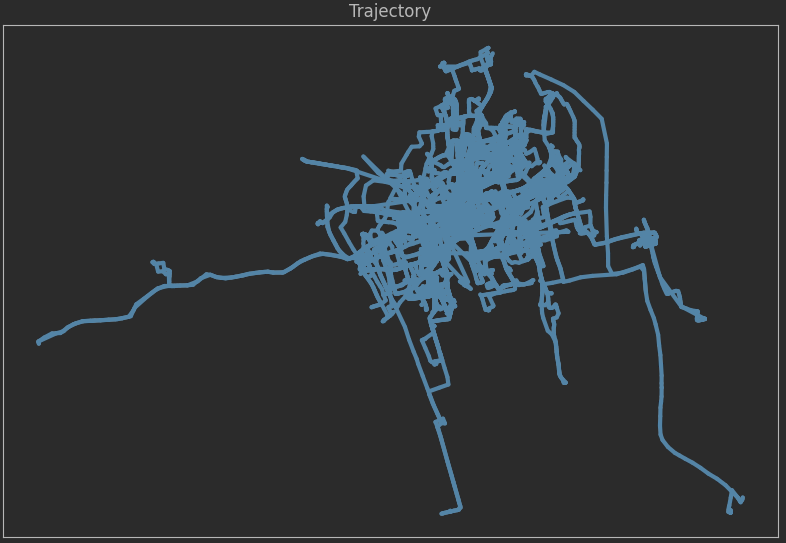
如果想访问一个特定的轨迹,可以通过使用轨迹的索引来实现
# 选择轨迹
one_traj = mdf.trajectories[4]
print(f'轨迹信息:\n{one_traj}\n')
# 获取轨迹长度
print(f'轨迹长度{one_traj.get_length()}')
# 绘制单个轨迹
ax = one_traj.plot(color='purple', **plot_defaults)
ax.set_title('A single trajectory')
ax.set_xticks([])
ax.set_yticks([])
plt.show()

可以根据column参数绘制轨迹
ax = one_traj.plot(column='speed', vmax=40, **plot_defaults) # 根据速度绘制轨迹
ax.set_title('Travel speed')
ax.set_xticks([]) # 设置坐标轴刻度
ax.set_yticks([]) # 设置坐标轴刻度
divider = make_axes_locatable(ax) # 创建坐标轴对象
cax = divider.append_axes('bottom', size='5%', pad=0.5) # 在底部添加新的坐标轴对象
cbar = plt.colorbar(ax.collections[0], cax=cax, orientation='horizontal') # 添加颜色条
cbar.set_label('Speed(km/h)') # 设置颜色条标签
plt.show()

根据给定的时间或时间范围内的位置,或根据与另一个几何体的交集,提取轨迹的一个元素
1、时间:
# 给定时间
time1 = datetime(2007,2,20,7,35,0)
time2 = datetime(2007,2,20,10,25,10)
# 获取给定时间最近的位置
p1 = one_traj.get_position_at(time1, method="nearest")
p2 = one_traj.get_position_at(time2, method="nearest")
print(f'{time1}最近点位置:{p1}\n{time2}最近点位置:{p2}\n')
# 获取时间范围内的位置
segment = one_traj.get_segment_between(time1, time2)
print(f'给定时间段内的轨迹\n{segment}')
# 绘制轨迹
ax = one_traj.plot(color='orange', **plot_defaults, legend=True)
segment.plot(ax=ax, color='red', linewidth=5, legend=True)
ax.set_title('A trajectory segment——time')
ax.set_xticks([]) # 设置坐标轴刻度
ax.set_yticks([]) # 设置坐标轴刻度
ax.legend(['Trajectory', 'Segment'])
plt.show()

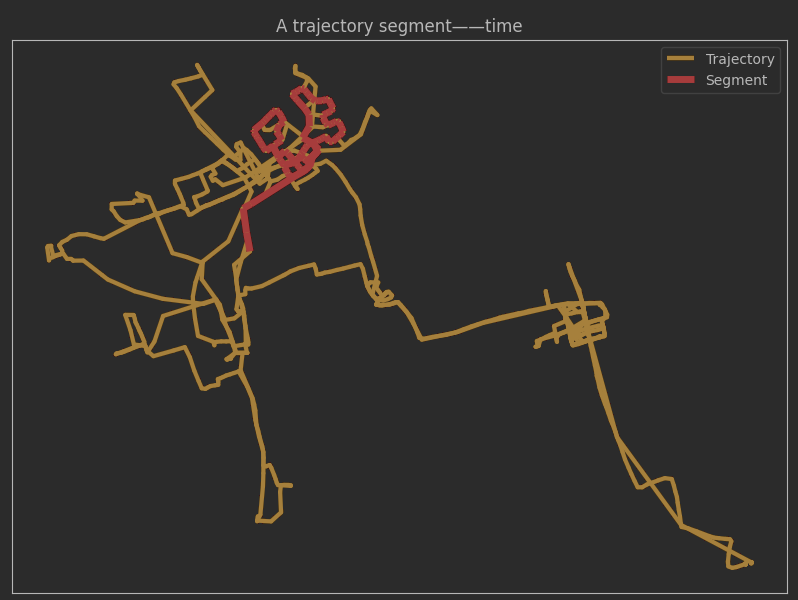
2、几何体相交的部分:
# 如果剪裁产生的轨迹不止一条,该方法将返回一个轨迹集合
xmin, xmax, ymin, ymax = one_traj.get_bbox() # 获取轨迹的边界
dist = 1000 # 设置距离
poly = Polygon([(xmin+dist, ymin+dist), (xmin+dist, ymax-dist), (xmax-dist, ymax-dist), (xmax-dist, ymin+dist), (xmin+dist, ymin+dist)]) # 创建多边形
intersections = one_traj.clip(poly) # 剪裁轨迹
# 绘制轨迹
ax = one_traj.plot(color='orange', **plot_defaults, legend=True)
intersections.plot(ax=ax, color='red', linewidth=5, legend=True)
ax.set_title('A trajectory segment——Plolygon')
ax.set_xticks([]) # 设置坐标轴刻度
ax.set_yticks([]) # 设置坐标轴刻度
ax.legend(['Trajectory', 'Segment'])
plt.show()
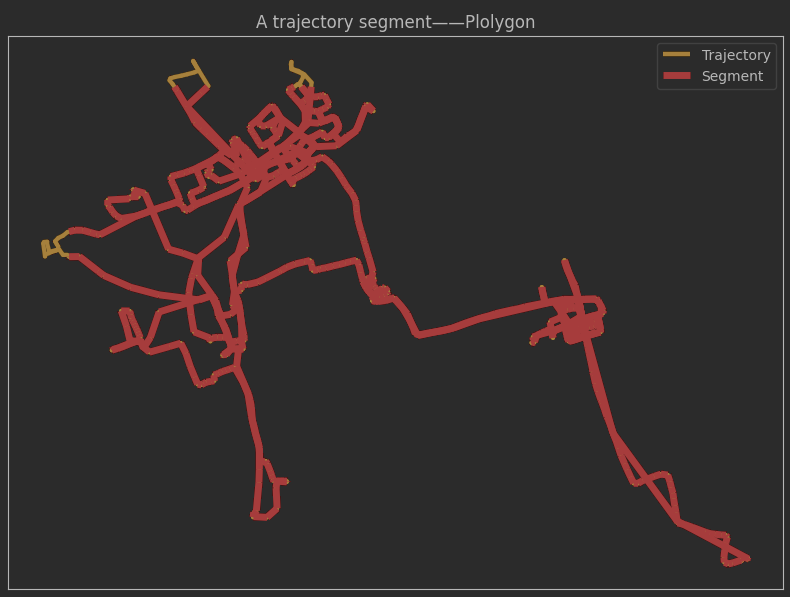
分割轨迹:如果观察有时间间隔,且物体以很低的速度运动,或者物体有一段时间没有离开同一地点,轨迹就会被分割
1、在观察有时间间隔的情况下,分割轨迹:
# 分割
'''ObservationGapSplitter是一个用于轨迹观测间隔分割的类。它可以将轨迹分割成多个子轨迹,其中每个
子轨迹表示连续观测之间的时间间隔。'''
split = mpd.ObservationGapSplitter(one_traj).split(gap=timedelta(minutes=4)) # 设置时间间隔
# 绘制轨迹
fig, axes = plt.subplots(nrows=1, ncols=len(split), figsize=(20,5))
for i, traj in enumerate(split):
traj.plot(ax=axes[i], linewidth=5.0, capstyle='round', column='speed', vmax=20)
fig.suptitle("Trajectory split by stops(4 minutes)")
plt.show()
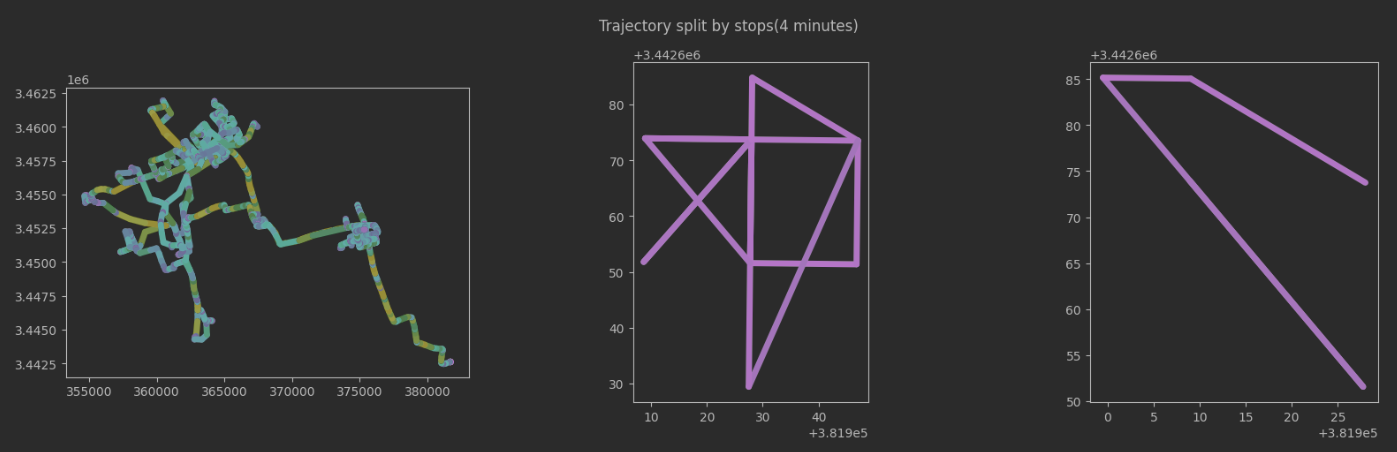
2、分割一条轨迹,观察结果至少在50米内停留4分钟,丢弃产生的短于500米的轨迹:
# 按要求分割
'''StopSplitter是一个用于轨迹停留点分割的类。它可以将轨迹分割成多个子轨迹,其中每个子轨迹表示连续停留的时间段。'''
split = mpd.StopSplitter(one_traj).split(max_diameter=30, min_duration=timedelta(minutes=4), min_length=500)
# 绘图
fig, axes = plt.subplots(nrows=2, ncols=3, figsize=(14,10))
for i, traj in enumerate(split):
row = i//3
col = i%3
traj.plot(ax=axes[row][col], linewidth=5.0, capstyle='round', column='speed', vmax=20)
fig.suptitle("Trajectory split by 4 minutes stay within 50 metres and drop 500 metres long")
plt.show()
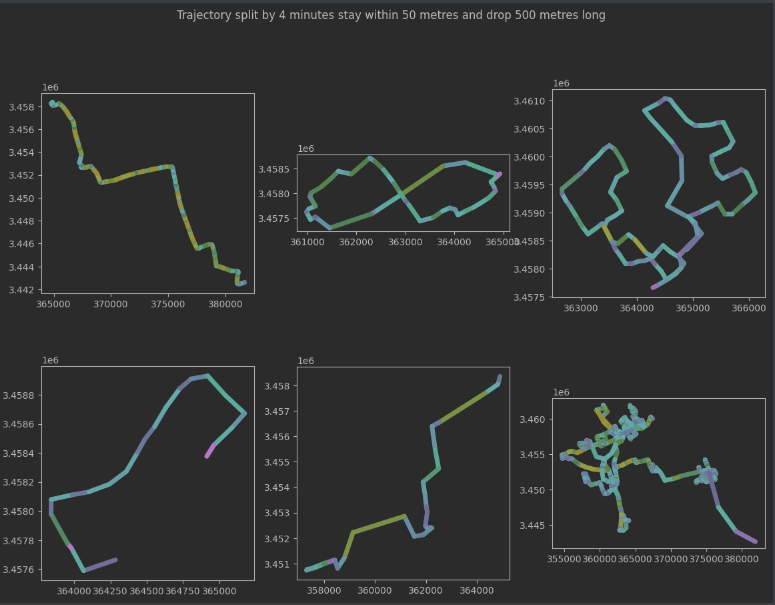
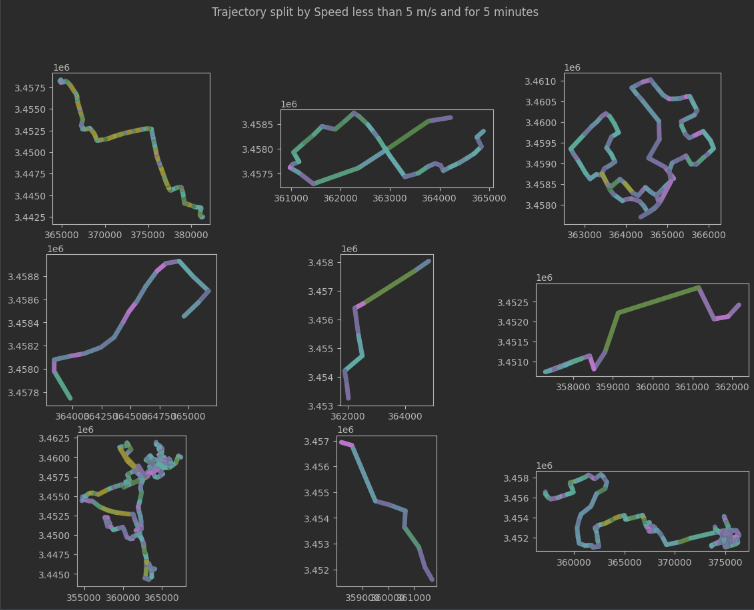
3、分割速度低于5米/秒的轨迹,至少5分钟:
# 按要求分割
'''SpeedSplitter是一个用于轨迹速度分割的类。它可以将轨迹分割成多个子轨迹,其中每个子轨迹表示在速
度变化较大的位置发生的事件或活动。'''
split = mpd.SpeedSplitter(one_traj).split(speed=5, duration=timedelta(minutes=5))
# 绘图
fig, axes = plt.subplots(nrows=3, ncols=3, figsize=(14,10))
for i, traj in enumerate(split):
row = i//3
col = i%3
traj.plot(ax=axes[row][col], linewidth=5.0, capstyle='round', column='speed', vmax=20)
fig.suptitle("Trajectory split by Speed less than 5 m/s and for 5 minutes")
plt.show()
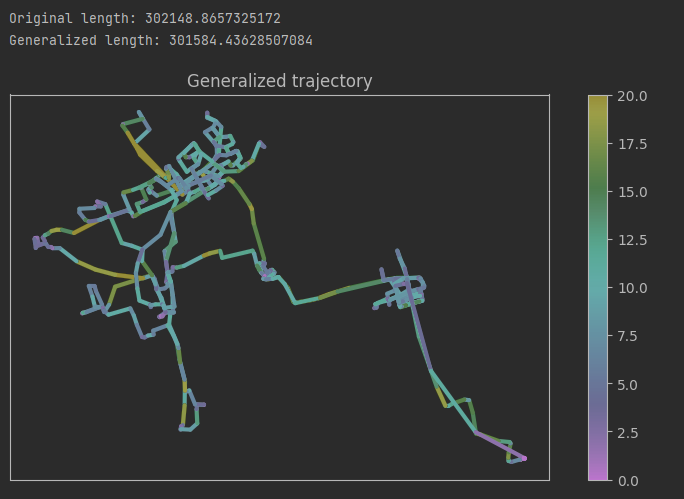
减少用于描述轨迹的点的数量
DouglasPeuckerGeneralizer是一个用于轨迹简化的算法,它可以通过减少轨迹中的点数来近似表示原始轨迹。它的原理是保留轨迹中具有重要形状变化的关键点,而删除介于这些关键点之间的冗余点。
DouglasPeuckerGeneralizer算法需要以下参数:
- 轨迹数据:这是要进行简化的原始轨迹数据。通常,轨迹数据由一系列坐标点组成,每个点表示在地理空间中的位置。
- 容差(tolerance):容差是算法的关键参数,它控制着简化程度。较小的容差值会导致更多的点被保留,从而更准确地表示原始轨迹。较大的容差值会导致更多的点被删除,从而产生更简化的轨迹近似。
fig, ax = plt.subplots(figsize=(10,5))
# tolerance参数指定了简化的容差值,较小的容差值会导致更多的点被保留,而较大的容差值会导致更多的点被删除
dp_generalized = mpd.DouglasPeuckerGeneralizer(one_traj).generalize(tolerance=20)
dp_generalized.plot(ax=ax, column='speed', vmax=20, **plot_defaults, legend=True)
ax.set_xticks([]) # 设置坐标轴刻度
ax.set_yticks([]) # 设置坐标轴刻度
ax.set_title('Generalized trajectory')
print('Original length: %s'%(one_traj.get_length()))
print('Generalized length: %s'%(dp_generalized.get_length()))
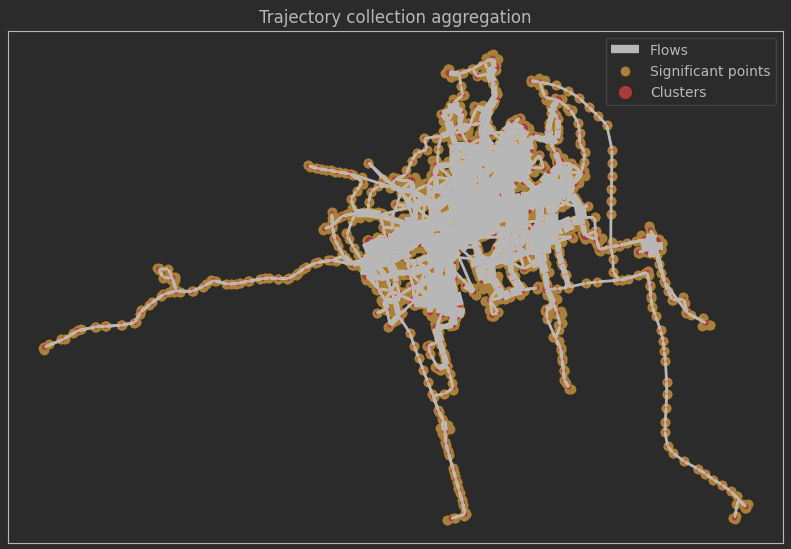
轨迹聚合
TrajectoryCollectionAggregator是一个用于轨迹集合聚合的类,它可以将轨迹集合中的相邻轨迹段聚合在一起形成更长的轨迹段。
TrajectoryCollectionAggregator需要以下参数:
- 轨迹集合(collection):这是要进行聚合的原始轨迹集合。轨迹集合通常由多个轨迹组成,每个轨迹由一系列坐标点表示。
- 最大距离(max_distance):指定相邻轨迹段之间的最大距离。如果两个轨迹段之间的距离超过此阈值,则它们不会被聚合在一起。
- 最小距离(min_distance):指定相邻轨迹段之间的最小距离。如果两个轨迹段之间的距离小于此阈值,则它们将被视为连续的一部分,并被聚合在一起。
- 最小停留时间(min_stop_duration):指定停止点的最小持续时间。如果在两个连续的轨迹段之间存在停止点,并且停止点的持续时间大于此阈值,则它们将被聚合在一起。
# 首先对轨迹进行简化,以汇总的更多跟快的速度
generalized = mpd.MinDistanceGeneralizer(mdf).generalize(tolerance=100)
# 聚合轨迹
aggregator = mpd.TrajectoryCollectionAggregator(generalized, max_distance=1000, min_distance=100, min_stop_duration=timedelta(minutes=5))
# 获取重要点对象,可能是停留点、速度变化较大的位置或其他被定义为重要的位置
# 群集,聚类可能是根据一定的空间或时间特征对轨迹进行聚合而形成的群集
# 流量信息,可能是在聚类结果中识别出的轨迹流动的指标,如流动的起点、终点、频率等
pts = aggregator.get_significant_points_gdf()
clusters = aggregator.get_clusters_gdf()
flows = aggregator.get_flows_gdf()
# 最大标记尺寸
max_size = 150
# 用每个群组的标记尺寸创建列
clusters['n_norm'] = (clusters.n - clusters.n.min()) / (clusters.n.max() - clusters.n.min())
clusters['m_size'] = clusters.n_norm * max_size
# 绘图
fig, ax = plt.subplots(figsize=(10,10))
flows.plot(ax=ax, linewidth=flows.weight*2, color='black', legend=True)
pts.plot(ax=ax, color='orange', legend=True)
clusters.plot(ax=ax, color='red', markersize=clusters['m_size'], legend=True)
ax.set_xticks([]) # 设置坐标轴刻度
ax.set_yticks([]) # 设置坐标轴刻度
ax.set_title('Trajectory collection aggregation')
ax.legend(['Flows', 'Significant points', 'Clusters'])
plt.show()
四、参考
参考哥本哈根信息技术大学,2022年春季MovingPandas课程,作者: Anastassia Vybornova & Ane Rahbek Vierø。
更多MovingPandas示例请查看[MovingPandas Examples]。
需要了解更多关于MovingPandas的功能请查看MovingPandas学习文档。
















 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









