







1.MapReduce工作原理
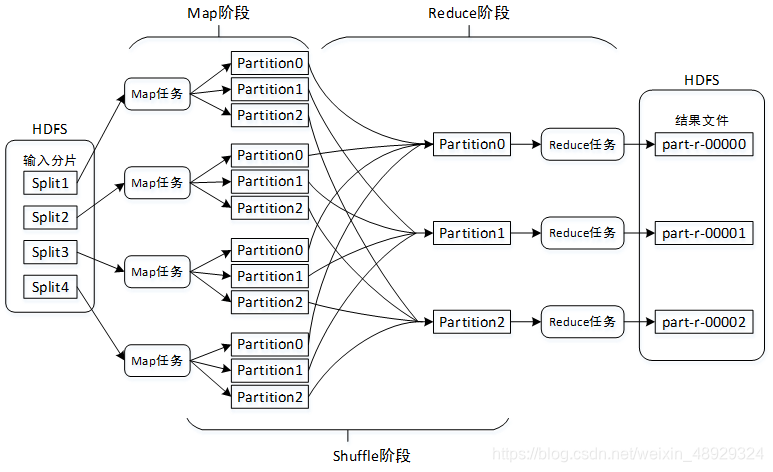
MapReduce计算模型主要由三个阶段组成:Map阶段、Shuffle阶段、Reduce阶段。
2.Spark工作原理
Spark作业的工作原理时,通常会引入Hadoop MapReduce的工作原理作为入门比较,因为MapReduce与Spark的工作原理有很多相似之处。
1.Map阶段
将输入的多个分片(Split)由Map任务以完全并行的方式处理。每个分片由一个Map任务来处理。默认情况下,输入分片的大小与HDFS中数据块(Block)的大小是相同的,即文件有多少个数据块就有多少个输入分片,也就会有多少个Map任务。从而可以调整HDFS数据块的大小来间接改变Map任务的数量。
每个Map任务对输入分片中的记录按照一定的规则解析成多个<key,value>对。默认将文件中的每一行文本内容解析成一个<key,value>对,key为每一行的起始位置,value为本行的文本内容。然后将解析出的所有<key,value>对分别输入到map()方法中进行处理(map()方法一次只处理一个<key,value>对)。map()方法将处理结果仍然是以<key,value>对的形式进行输出。
在数据溢写到磁盘之前,会对数据进行分区(Partition)。分区的数量与设置的Reduce任务的数量相同(默认Reduce任务的数量为1,可以在编写MapReduce程序时对其修改)。这样每个Reduce任务会处理一个分区的数据,可以防止有的Reduce任务分配的数据量太大,而有的Reduce任务分配的数据量太小,从而可以负载均衡,避免数据倾斜。数据分区的划分规则为:取<key,value>对中key的hashCode值,然后除以Reduce任务数量后取余数,余数则是分区编号,分区编号一致的<key,value>对则属于同一个分区。因此,key值相同的<key,value>对一定属于同一个分区,但是同一个分区中可能有多个key值不同的<key,value>对。由于默认Reduce任务的数量为1,而任何数字除以1的余数总是0,因此分区编号从0开始。
2.Reduce阶段
Reduce阶段首先会对Map阶段的输出结果按照分区进行再一次合并,将同一分区的<key,value>对合并到一起,然后按照key对分区中的<key,value>对进行排序。
每个分区会将排序后的<key,value>对按照key进行分组,key相同的<key,value>对将合并为<key,value-list>对,最终每个分区形成多个<key,value-list>对。例如,key中存储的是用户ID,则同一个用户的<key,value>对会合并到一起。
排序并分组后的分区数据会输入到reduce()方法中进行处理,reduce()方法一次只能处理一个<key,value-list>对。
最后,reduce()方法将处理结果仍然以<key,value>对的形式通过context.write(key,value)进行输出。
3.Shuffle阶段
‘Shuffle阶段所处的位置是Map任务输出后,Reduce任务接收前。主要是将Map任务的无规则输出形成一定的有规则数据,以便Reduce任务进行处理。
总结来说,MapReduce的工作原理主要是:通过Map任务读取HDFS中的数据块,这些数据块由Map任务以完全并行的方式处理;然后将Map任务的输出进行排序后输入到Reduce任务中;最后Reduce任务将计算的结果输出到HDFS文件系统中。
3.Spark工作流程
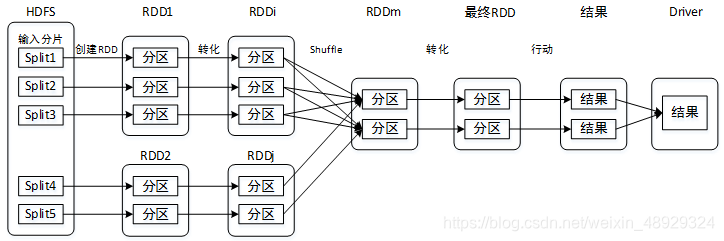
1.从数据源(本地文件、HDFS、HBase等)读取数据并创建RDD。
2.对RDD进行一系列的转化操作。
3.对最终RDD执行行动操作,开始一系列的计算,产生计算结果。
4.将计算结果发送到Driver端,进行查看和输出。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









