







某人为了期末作业(非计算机系的文科生)想获取数据做分析,奈何不会八爪鱼,于是乎她成了我的甲方。甲方妈妈的需求是这样的:爬取携程网和同程网的对于三亚蜈支洲岛的评论。
一、爬取携程网的评论
1.1 分析
爬取的地址:https://you.ctrip.com/sight/sanya61/3244.html#comment
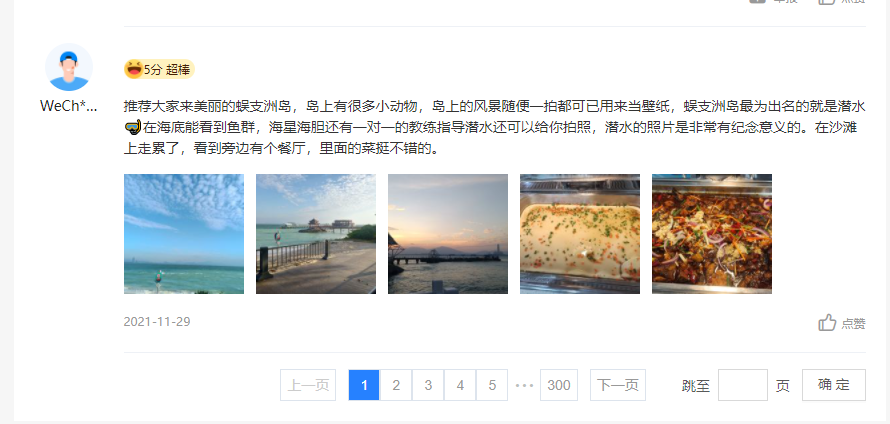
- 评论在这里,并且有分页
- 但是发现点击下一页的时候地址栏并没有变化

- 所以这种情况打开F12控制台看看吧
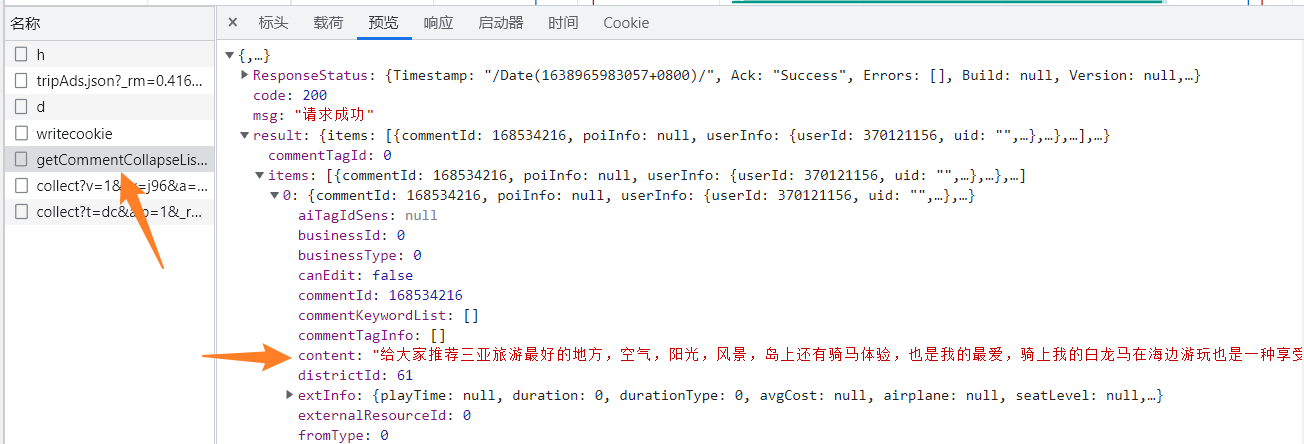
- 发现分页和这个响应有关,并且返回的是一个json数据的格式
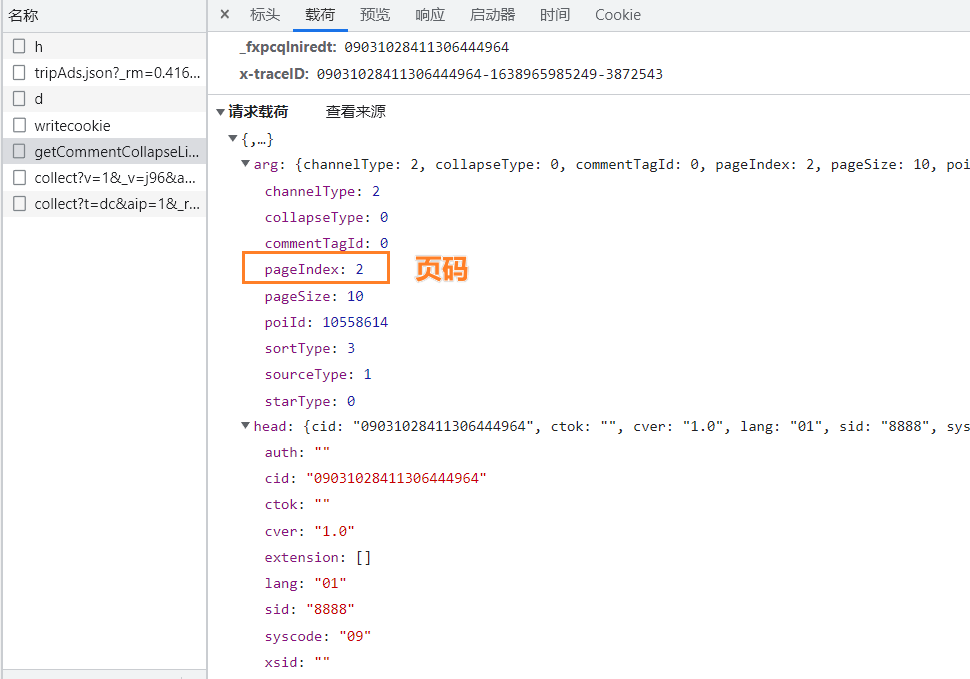
- pageIndex是页码,所以找到关键的点了
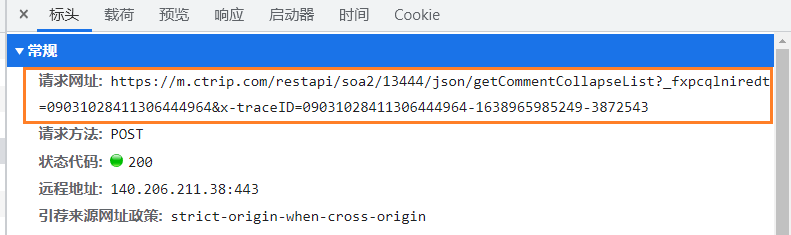
- 获取到评论的地址:https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList?_fxpcqlniredt=09031028411306444964
- 请求是POST请求
1.2 代码实现
- 这里我只爬取了前50页
import requests
import json
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36',
}
posturl = "https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList?_fxpcqlniredt=09031028411306444964"
def getdata():
j = 1
for i in range(1, 51):
request = {
'arg': {
'channelType': '2',
'collapseType': '0',
'commentTagId': '0',
'pageIndex': str(i),
'pageSize': '10',
'poiId': '10558614',
'sortType': '3',
'sourceType': '1',
'starType': '0'},
'head': {
'auth': "",
'cid': "09031028411306444964",
'ctok': "",
'cver': "1.0",
'extension': [],
'lang': "01",
'sid' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









