







Spark概述

SparkSQL概述

1.什么是SparkSQL
- Spark SQL是用于结构化数据处理的Spark模块。
- Spark SQL允许开发人员使用SQL查询和DataFrame API来操作结构化数据,包括从各种数据源中读取数据、执行复杂的数据转换和分析操作,以及将处理结果写回到不同的数据源中。
- 与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了有关数据结构和正在执行的计算的更多信息。
- 在内部,Spark SQL使用这些额外的信息来执行额外的优化。
- 与Spark SQL交互的方式有多种,包括SQL和Dataset API。
- 计算结果时,使用相同的执行引擎,与用于表达计算的API/语言无关。
2.为什么会存在SparkSQL
Spark SQL 的出现主要是为了解决以下几个问题,并为 Spark 生态系统提供更完整的数据处理解决方案。
(1)统一编程模型
- Spark 本身提供了基于 RDD 的编程模型,但对于熟悉 SQL 的用户来说,使用 RDD 进行数据处理可能比较复杂。
- 引入 Spark SQL 后,用户可以使用标准的 SQL 查询语言或 DataFrame/Dataset API 来处理数据,这使得数据处理更加简单和直观。
(2)性能优化
- Spark SQL 引入了优化器和执行引擎,能够对 SQL 查询进行优化,包括逻辑优化、物理优化和执行计划生成,以提高查询性能和执行效率。
- 这种优化使得用户无需手动调整代码,就能获得更高的性能。
(3)数据集成
- Spark SQL 支持多种数据源,包括 Hive、JSON、Parquet、ORC、JDBC、CSV 等,可以方便地从不同的数据源中读取数据,并将处理结果写回到这些数据源中。
(4)更丰富的数据处理功能
- Spark SQL 提供了丰富的数据处理功能,包括窗口函数、聚合函数、连接操作等,能够满足用户对数据的各种分析和处理需求。
- 同时,用户还可以通过自定义函数(UDF)扩展 SQL 查询的功能,以实现更复杂的数据处理逻辑。
(5)与 Hive 的集成
- Spark SQL 可以与 Apache Hive 集成,允许直接查询 Hive 中的数据,并使用 Hive 元数据进行元数据管理和优化查询执行。
- 这种集成使得 Spark 用户可以无缝地在 Spark 上运行现有的 Hive 查询,并与现有的 Hive 生态系统集成。



3.SparkSQL的发展
-
1.RDD(Resilient Distributed Dataset):在 Spark 1.0 中引入了 RDD,它是 Spark 最初的数据抽象和编程模型。RDD 是一个分布式的、不可变的数据集合,可以容错地并行操作。虽然 RDD 提供了强大的抽象和灵活性,但使用起来比较复杂,而且没有提供结构化数据处理的高级接口。
-
2.DataFrame:在 Spark 1.3 中引入了 DataFrame API,它是对 RDD 的一个抽象,提供了更高级别的接口来操作结构化数据。DataFrame 可以理解为具有命名列的分布式表格,支持类似于 SQL 的查询操作。DataFrame 的引入使得用户可以使用 SQL 查询语言或 DataFrame API 来处理结构化数据,从而简化了数据处理的过程。
-
3.Dataset:在 Spark 1.6 中引入了 Dataset API,它是对 DataFrame API 的扩展,提供了类型安全的 API,并支持更丰富的数据结构和操作。Dataset 可以看作是强类型的 DataFrame,能够在编译时捕获数据处理中的错误,并提供更好的性能优化。Dataset API 的引入使得 Spark SQL 在类型安全性和表达能力上有了更大的提升,同时也为 Spark SQL 的未来发展奠定了基础。
RDD(Spark1.0)=》Dataframe(Spark1.3)=》Dataset(Spark1.6)
- 如果同样的数据都给到这三个数据结构,他们分别计算之后,都会给出相同的结果。
- 不同的是他们的执行效率和执行方式。
- 在现在的版本中,dataSet性能最好,已经成为了唯一使用的接口。
- 其中Dataframe已经在底层被看做是特殊泛型的DataSet。
三者的共性:
(1)RDD、DataFrame、DataSet全都是Spark平台下的分布式弹性数据集,为处理超大型数据提供便利。
(2)三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action行动算子如foreach时,三者才会开始遍历运算。
(3)三者有许多共同的函数,如filter,排序等。
(4)三者都会根据Spark的内存情况自动缓存运算。
(5)三者都有分区的概念。
4.SparkSQL的特点
1)易整合
无缝的整合了SQL查询和Spark编程。

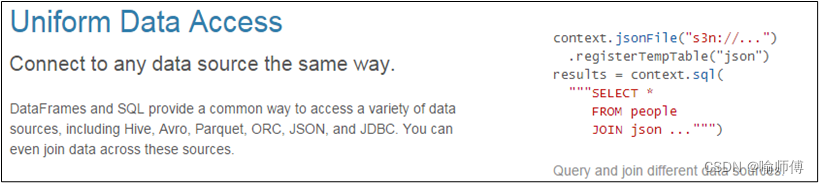
2)统一的数据访问方式
使用相同的方式连接不同的数据源。
3)兼容Hive
在已有的仓库上直接运行SQL或者HQL。

4)标准的数据连接
通过JDBC或者ODBC来连接。


















 1071
1071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











