







Spark概述

SparkStreaming架构原理
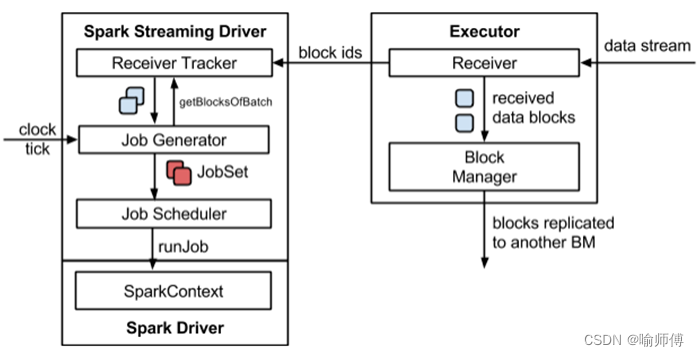
Spark Streaming的架构主要由以下几个关键部分组成。
1.数据源接收器(Receiver)
-
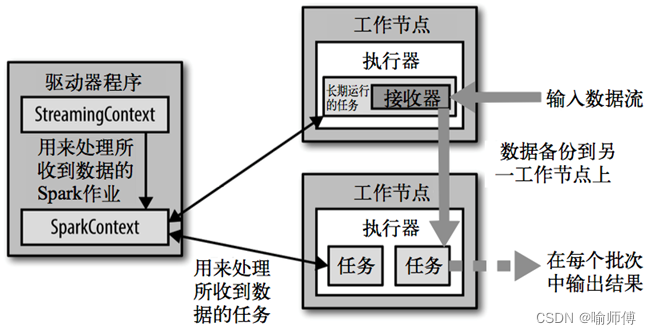
执行流程开始于数据源接收阶段,其中接收器(
Receiver)负责从外部数据源获取数据流。
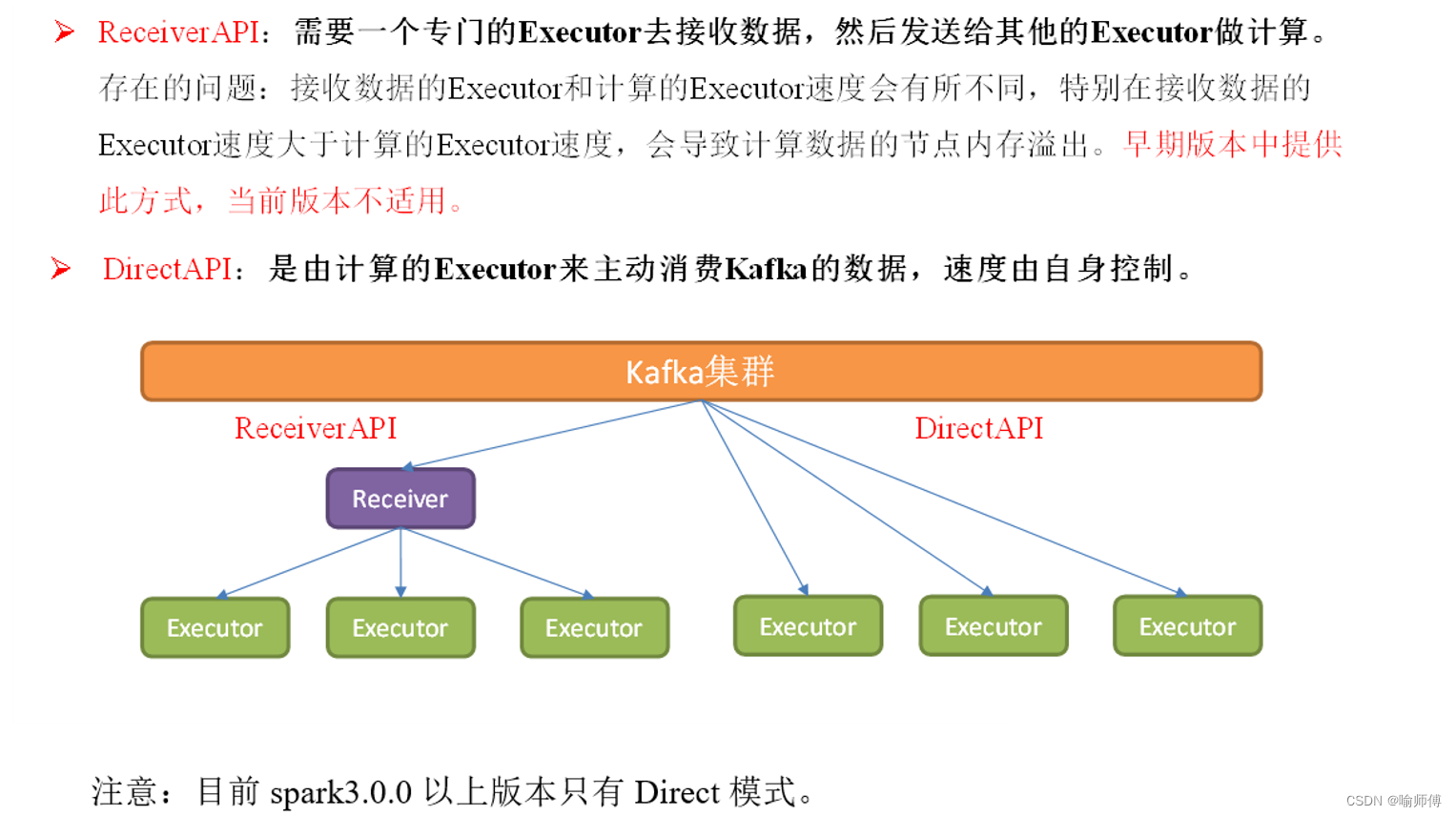
-
接收器可以连接到诸如Kafka、Flume、Kinesis等数据源,或直接通过网络套接字接收数据。

-
接收器的主要功能是接收数据并将其缓冲起来,然后传输给Spark集群进行处理。
2.微批次生成器(Micro-batch Generator)
-
将接收到的数据划分为小的微批次,每个微批次包含一段时间范围内的数据。
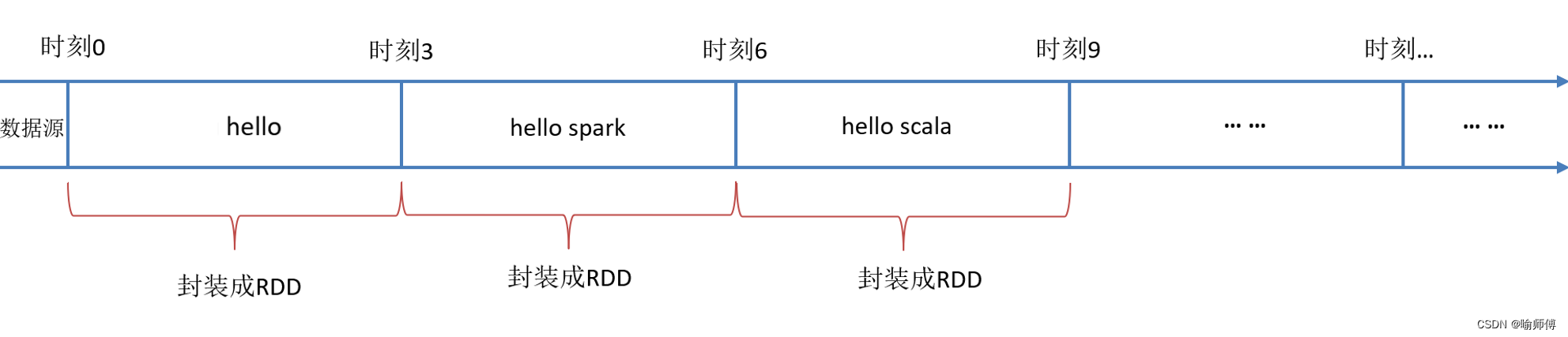
-
微批次生成器控制着微批次的生成速率,并确保数据按时到达处理流程。
3.离散化流(DStream)
- 每个微批次的数据被转换成一个DStream对象。

- DStream是一系列连续的RDD(Resilient Distributed Dataset)的抽象,每个RDD包含一个微批次的数据。
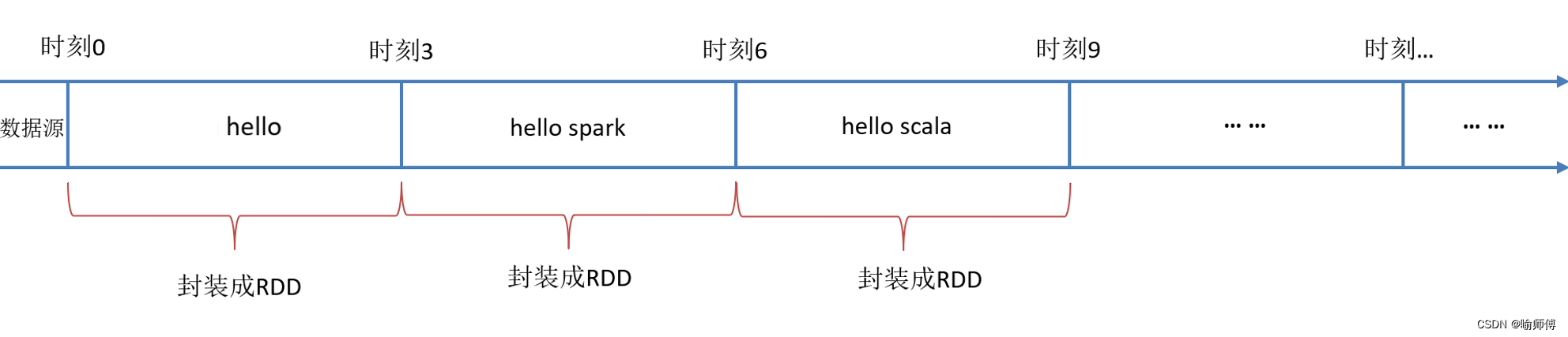
4.转换操作(Transformations)
- 在DStream上执行一系列的转换操作,例如映射、过滤、聚合等,以实现所需的业务逻辑。
- 转换操作是在微批次级别上进行的,即对每个微批次的数据执行相同的转换操作。
5.RDD生成器(RDD Generator)
- 转换操作生成的DStream会被转换成相应的RDD。
- RDD是Spark中的基本数据抽象,代表可并行操作的数据集合。
6.计算引擎(Compute Engine)
- 生成的RDD会被提交给Spark引擎进行计算执行。
- Spark引擎会根据RDD的依赖关系和转换操作构建执行计划,并将计算任务分配给集群中的工作节点执行。
7.结果输出器(Output Operations)
- 计算执行完成后,结果可以写入外部系统或存储介质中。
- 输出可以是保存到文件系统、写入数据库、发送到消息队列等操作。
- 输出操作通常在驱动器程序中定义,并在每个微批次处理完成后触发执行。
8.容错处理(Fault Tolerance)
- Spark Streaming具有内置的容错机制,可以处理节点故障或数据丢失的情况。
- 容错主要依赖于Spark引擎的RDD血统(RDD lineage)和数据日志记录,以实现数据的可靠处理和恢复。

















 2334
2334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











