







一、Spark Streaming处理的数据流程
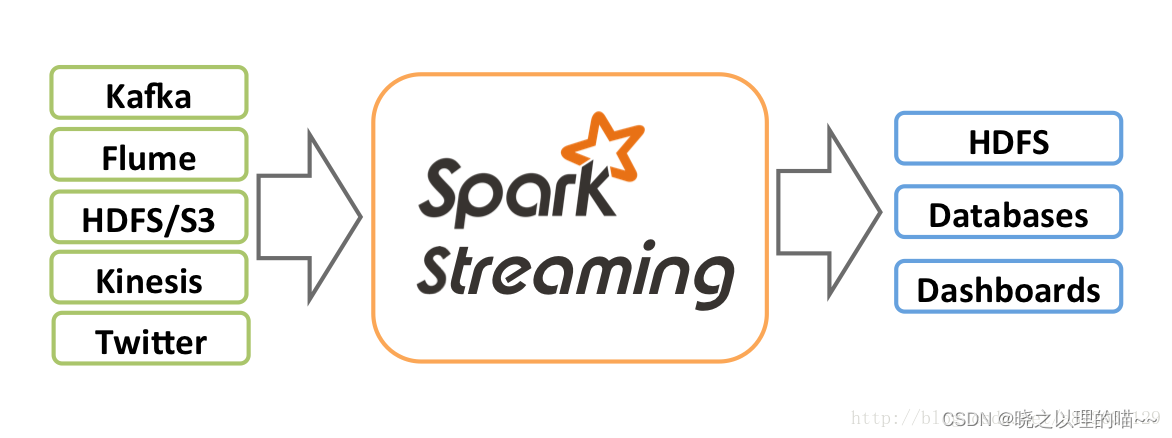
1、Spark Streaming接收Kafka、Flume、HDFS和Kinesis等各种来源的实时输入数据,进行处理后,处理结果保存在HDFS、Databases等各种地方。
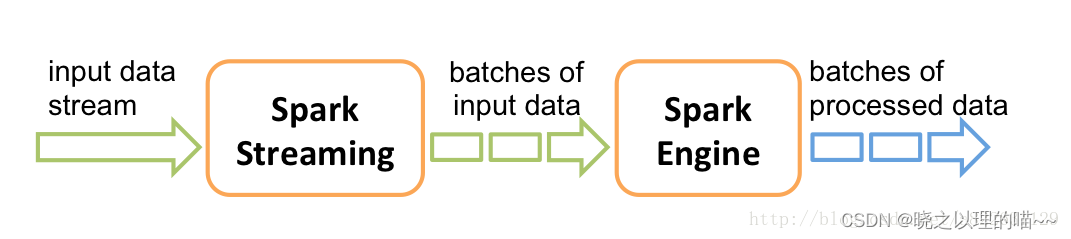
2、Spark Streaming接收这些实时输入数据流,会将它们按批次划分,然后交给Spark引擎处理,生成按照批次划分的结果流。
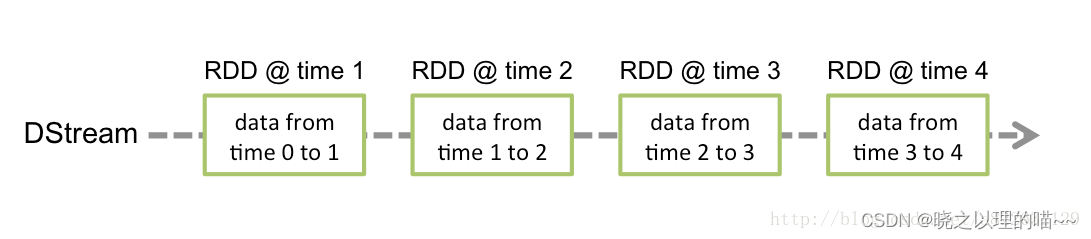
3、Spark Streaming提供了表示连续数据流的、高度抽象的被称为离散流的DStream。DStream本质上表示RDD的序列。任何对DStream的操作都会转变为对底层RDD的操作。在内部实现上,Spark Streaming的输入数据按照时间片(如1秒)分成一段一段,每一段数据转换为Spark中的RDD,并且对DStream的操作都最终被转变为对相应的RDD的操作。
4、Spark Streaming使用数据源产生的数据流创建DStream,也可以在已有的DStream上使用一些操作来创建新的DStream。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4428
4428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











