






概要
开发中,公司要求我把公司项目的几张万级的MySQL数据库表同步到MongoDB,以减少对数据库的访问压力,而且要对其中的数据库表进行数据清洗和数据加密等操作,因为是同步四张表,我就想着能不能写一个通用的公共的同步方法,每个表只需要取出自己的数据,去调用这个公共方法就同步了,以后有需要同步的表直接调用我的方法,想着想着开干!
整体架构流程
这里我们用到架构是SpringBoot+mybatis+mysql+MongoDB
技术细节
话不多说直接上代码
@Slf4j
@Service
public class DataSyncServiceImpl implements DataSyncService {
@Autowired
private MongoTemplate mongoTemplate;
@Transactional(isolation = Isolation.READ_COMMITTED, propagation = Propagation.REQUIRES_NEW, rollbackFor = Exception.class)
@Override
public <T extends Identifiable> ResponseEntity<String> syncData(DataFetcher<T> fetcher, Function<T, T> preProcessor) {
Instant start = Instant.now(); // 记录开始时间
try {
log.info("开始同步数据");
//设置分页参数
int pageSize = 10000;
int pageNum = 0;
// 循环从数据源获取数据,直到数据源返回空数据
while (true) {
// 通过 fetcher 获取数据
List<T> dataFromMysql = fetcher.fetch(pageNum, pageSize);
// 如果获取的数据为空,则退出循环
if (CollUtil.isEmpty(dataFromMysql)) {
break;
}
log.info("从第 {} 页获取了 {} 条记录", (pageNum / pageSize) + 1, dataFromMysql.size());
// 调用 syncTableData 方法,进行数据同步
syncTableData(dataFromMysql,preProcessor);
// 更新 pageNum,准备获取下一页数据 这个page是偏移量,不是分页的页码,这里没有用分页插件
pageNum = pageNum + pageSize;
}
} catch (Exception e) {
log.error("同步数据异常:{}", e.getMessage());
}
Instant end = Instant.now(); // 记录结束时间
Duration duration = Duration.between(start, end); // 计算耗时
log.info("同步数据完成,总耗时:{} 秒", duration.getSeconds());
return ResponseEntity.ok("同步数据完成,总耗时:" + duration.getSeconds() + "秒");
}
private <T extends Identifiable> void syncTableData(List<T> dataFromMysql, Function<T, T> preProcessor) {
log.info("同步数据条数:{}", dataFromMysql.size());
// 创建 MongoDB 的 BulkOperations 对象它可以执行批量的更新和插入操作每个文档都会根据唯一标识符进行查询,如果存在则执行更新操作否则执行插入操作
BulkOperations bulkOperations = mongoTemplate.bulkOps(BulkOperations.BulkMode.ORDERED, dataFromMysql.get(0).getClass());
Instant startProcessing = Instant.now(); // 记录开始处理时间
// 遍历从数据源获取的数据
for (T entity : dataFromMysql) {
// 在构建 Update 对象之前对实体进行预处理
T processedEntity = preProcessor.apply(entity);
// 构建查询条件 通过id去查询MongoDB是否有相同数据 注意这是全表扫描,可以给_id加上索引来优化查询速度,提升整体性能
Query query = Query.query(Criteria.where("id").is(processedEntity.getId()));
// 构建 Update 对象 传入参数是处理后的实体 比如加密后的实体
Update update = buildUpdate(processedEntity);
// 执行 upsert 操作 upsert操作是如果MongoDB存在重复数据 那我就更新,不存在就添加
bulkOperations.upsert(query, update);
}
Instant endProcessing = Instant.now(); // 记录结束处理时间
Duration processingDuration = Duration.between(startProcessing, endProcessing); // 计算处理时间
if (!dataFromMysql.isEmpty()) {
bulkOperations.execute();
log.info("数据处理完成,总耗时:{} 秒", processingDuration.getSeconds());
} else {
log.info("没有数据需要处理");
}
}
/**
* 同步一条数据公共方法
* @param entity
* @param preProcessor
* @return
* @param <T>
*/
@Transactional(isolation = Isolation.READ_COMMITTED, propagation = Propagation.REQUIRES_NEW, rollbackFor = Exception.class)
public <T extends Identifiable> ResponseEntity<String> syncSingleData(T entity, Function<T, T> preProcessor) {
try {
// 记录日志,表示开始同步单条数据
log.info("开始同步单条数据");
// 在构建 Update 对象之前对实体进行预处理
T processedEntity = preProcessor.apply(entity);
// 构建查询条件
Query query = Query.query(Criteria.where("id").is(processedEntity.getId()));
// 构建 Update 对象
Update update = buildUpdate(processedEntity);
// 执行 upsert 操作
mongoTemplate.upsert(query, update, entity.getClass());
} catch (Exception e) {
// 记录异常信息
log.error("同步单条数据异常:{}", e.getMessage());
}
log.info("同步单条数据完成");
// 返回同步完成的信息
return ResponseEntity.ok("同步单条数据完成");
}
private <T extends Identifiable> Update buildUpdate(T entity) {
Update update = new Update();
// 使用反射获取所有字段,并检查非空字段
Field[] fields = entity.getClass().getDeclaredFields();
for (Field field : fields) {
try {
// 设置字段可访问
field.setAccessible(true);
// 获取字段的值
Object value = field.get(entity);
// 如果字段值不为空,则添加到 Update 对象中
if (value != null) {
update.set(field.getName(), value);
}
} catch (IllegalAccessException e) {
log.error("获取字段值时发生异常:{}", e.getMessage(), e);
}
}
return update;
}
}
首先,我们使用了事务管理来确保数据同步的原子性。在 MongoDB 中,我们使用 @Transactional 注解,配置事务的隔离级别、传播行为,并指定回滚条件。这样,即使在同步过程中发生异常,事务会回滚到之前的状态,保证数据的一致性
@Transactional(isolation = Isolation.READ_COMMITTED, propagation = Propagation.REQUIRES_NEW, rollbackFor = Exception.class)
public <T extends Identifiable> ResponseEntity<String> syncData(DataFetcher<T> fetcher, Function<T, T> preProcessor) {
// ...
}
然后我定义了一个DataSyncService接口,参数是DataFetcher和一个Function函数
public interface DataSyncService {
<T extends Identifiable> ResponseEntity<String> syncData(DataFetcher<T> fetcher, Function<T, T> preProcessor);
}
DataFetcher是将获取数据的逻辑抽象为一个接口,并将该接口作为参数传递给syncData方法,从而使代码更加通用
public interface DataFetcher<T> {
List<T> fetch(int pageNum, int pageSize);
}
然后是我们如何调用方法?
dataSyncService.syncData((pageNum, pageSize) -> talkRecordMapper.selectTalkByPage(pageNum, pageSize),
entity -> {
// 加密context字段
entity.setContent(AESUtil.encrypt(entity.getContent()));
entity.setUuid(entity.getId());
return entity;
}
);
上述代码就是把所有要同步的数据查询出来,作为一个参数,和数据里要处理的数据一起传给syncData方法talkRecordMapper.selectTalkByPage(pageNum, pageSize)是一个DataFetcher的实现,它知道如何从testMapper获取分页数据;
这个Function函数的作用是接受一个实体并返回一个处理过的实体,这里我用了lambad表达式的写法
entity -> {
// 加密context字段
entity.setContent(AESUtil.encrypt(entity.getContent()));
entity.setUuid(entity.getId());
return entity;
}
);
把这个部分作为一个参数preProcessor传给了syncData方法,preProcessor 是应用于每个实体的
// 对实体进行预处理
T processedEntity = preProcessor.apply(entity);
Query query = Query.query(Criteria.where("id").is(processedEntity.getId()));
因为我需要构建一个查询条件, 通过id去查询MongoDB是否有相同数据,但是processedEntity 是没有getter和setter方法,有两种解决办法
第一:
private <T> Serializable getId(T entity, String idField) {
try {
Field field = entity.getClass().getDeclaredField(idField);
field.setAccessible(true);
return (Serializable) field.get(entity);
} catch (NoSuchFieldException | IllegalAccessException e) {
throw new RuntimeException(e);
}
}
通过反射的方法是获取id,不过反射有性能上的损耗
第二:
public interface Identifiable {
Serializable getId();
}
@Data
@Document("test")
public class Test implements Identifiable {
@Id
private Integer id;
private String phone;
private String name;
private Date updateTime;
@Override
public Integer getId() {
return id;
}
}
我定义一个公共的接口,叫做Identifiable,这个接口有一个方法叫做getId,然后,所有实体类都实现这个接口。这样就可以在不知道具体类型的情况下,通过这个接口来获取实体的ID。在上诉代码中我用的是processedEntity.getId()方法,我们不再需要使用反射来获取ID,而是直接调用getId方法。这样,我们就可以避免反射带来的性能开销,提高代码的效率
测试
然后给大家来看看测试效果吧
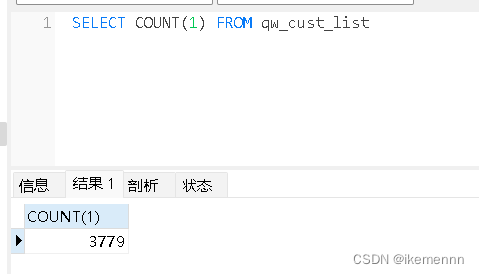

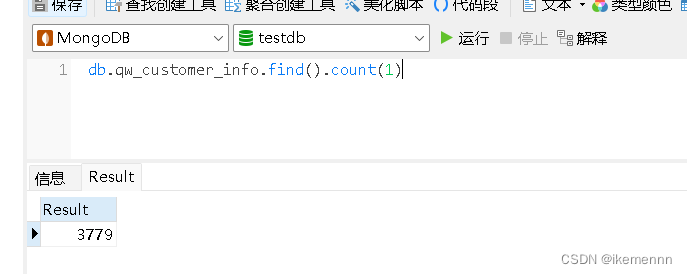
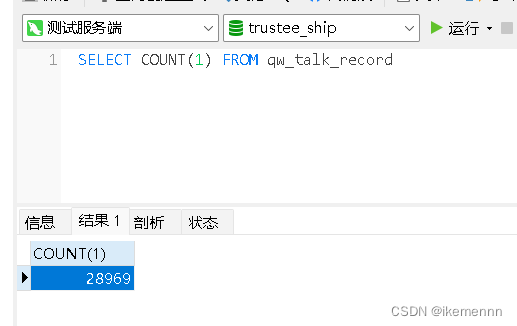

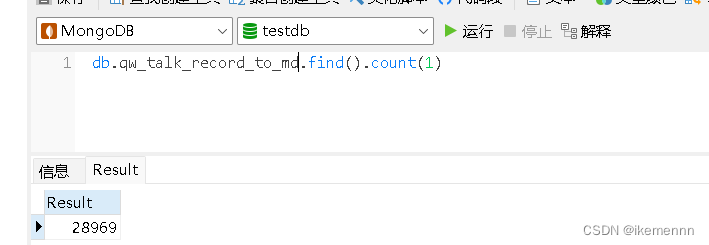
小结
可以看到像这种几千条数据基本都是2-3秒,几万条数据就10秒左右,这么看来效率还是很快的,如果是数据量大的情况可以考虑,给MongoDB加索引,使用多线程等等















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









