







python - PySpark
提示:本文根据b站黑马python课整理
链接指引 => 2022新版黑马程序员python教程
文章目录
一、PySpark库的安装
在”CMD”命令提示符程序内,输入:
pip install pyspark
或使用国内代理镜像网站(清华大学源)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
二、PySpark的编程模型是?
- 数据输入:通过SparkContext完成数据读取
- 数据计算:读取到的数据转换为RDD对象,调用RDD的成员方法完成计算
- 数据输出:调用RDD的数据输出相关成员方法,将结果输出到list、元组、字典、文本文件、数据库等
# 导包
from pyspark import SparkConf, SparkContext
# 创建sparkconf类对象
conf = SparkConf().setMaster('local[*]').setAppName('test_spark_app')
# 基于SparkConf类对象创建SparkContext对象
sc = SparkContext(conf=conf)
# 打印
print(sc.version)
# 停止SparkContext对象的允许
sc.stop()
三、数据输入
3.1 RDD对象
RDD全称为:弹性分布式数据集(Resilient Distributed Datasets)
PySpark针对数据的处理,都是以RDD对象作为载体,即:
- 数据存储在RDD内
- 各类数据的计算方法,也都是RDD的成员方法
- RDD的数据计算方法,返回值依旧是RDD对象
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 准备一个rdd
rdd = sc.parallelize([1, 2, 3, 4, 5])
print(rdd.collect())
sc.stop()
四、数据计算
4.1 map算子
map算子(成员方法):
- 接受一个处理函数,可用lambda表达式快速编写
- 对RDD内的元素逐个处理,并返回一个新的RDD

from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 准备一个rdd
rdd = sc.parallelize([1, 2, 3, 4, 5])
# print(rdd.collect())
# 使用map方法把数据都*10
# def func(data):
# return data * 10
#
rdd2 = rdd.map(lambda x: x * 10)
# rdd2 = rdd.map(func)
print(rdd2.collect())
# sc.stop()
4.2 flatMap算子
计算逻辑和map一样
可以比map多出,解除一层嵌套的功能
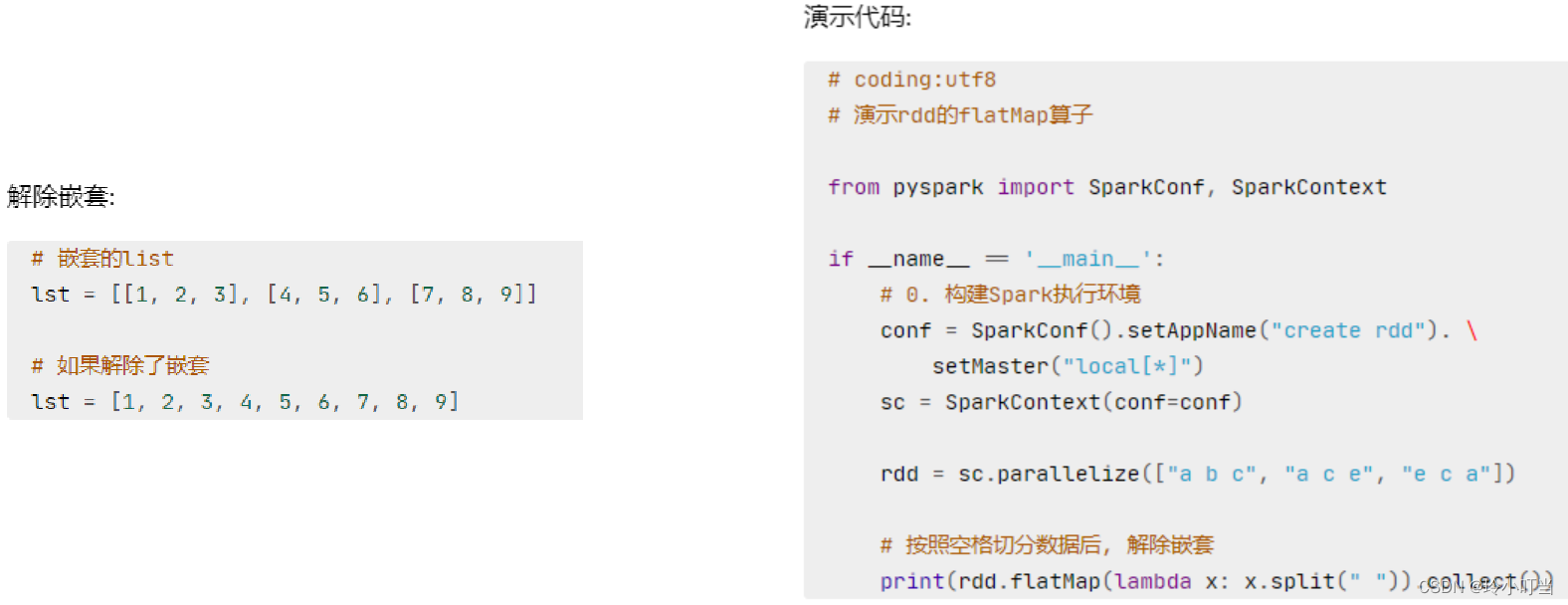
4.3 reduceByKey算子
接受一个处理函数,对数据进行两两计算
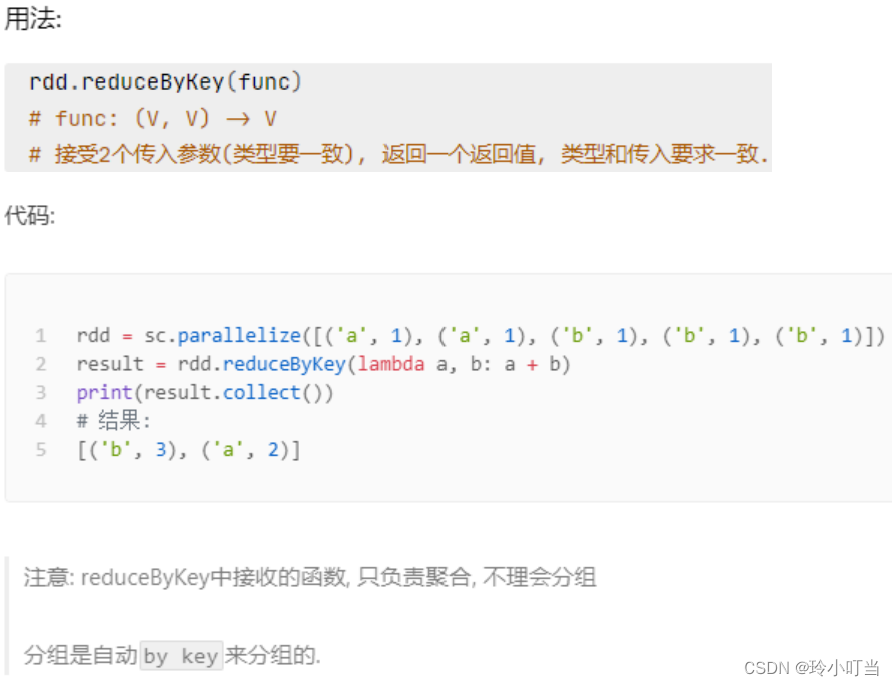
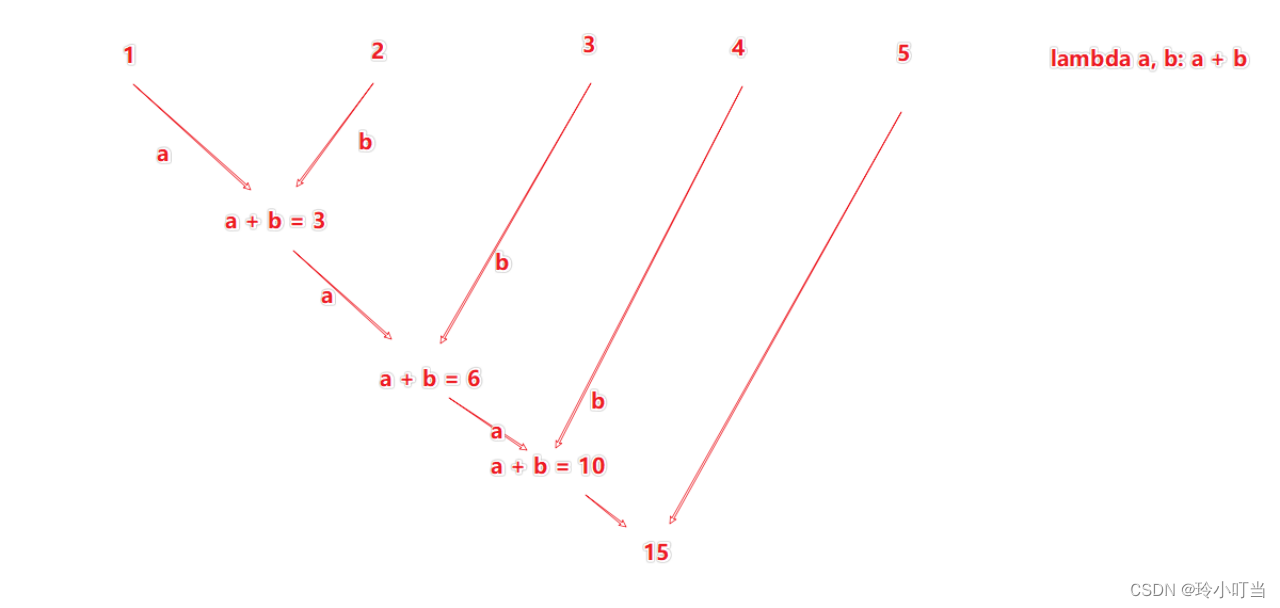
4.4 filter算子
filter算子
- 接受一个处理函数,可用lambda快速编写
- 函数对RDD数据逐个处理,得到True的保留至返回值的RDD中
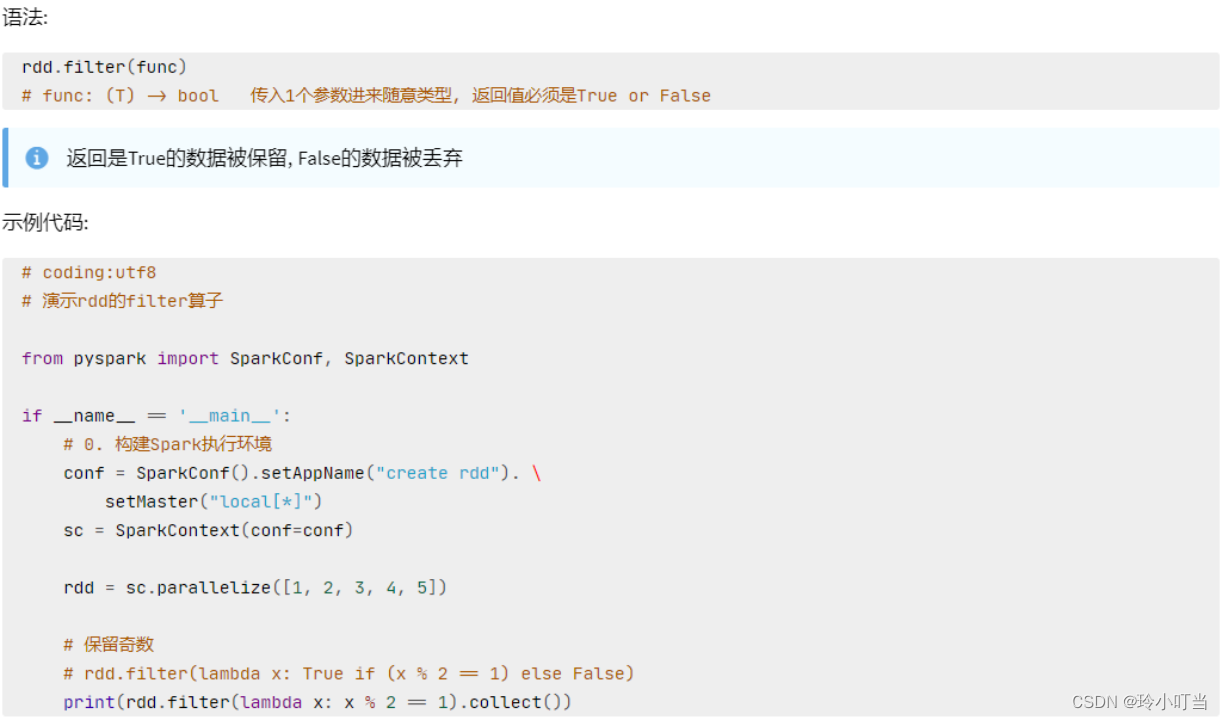
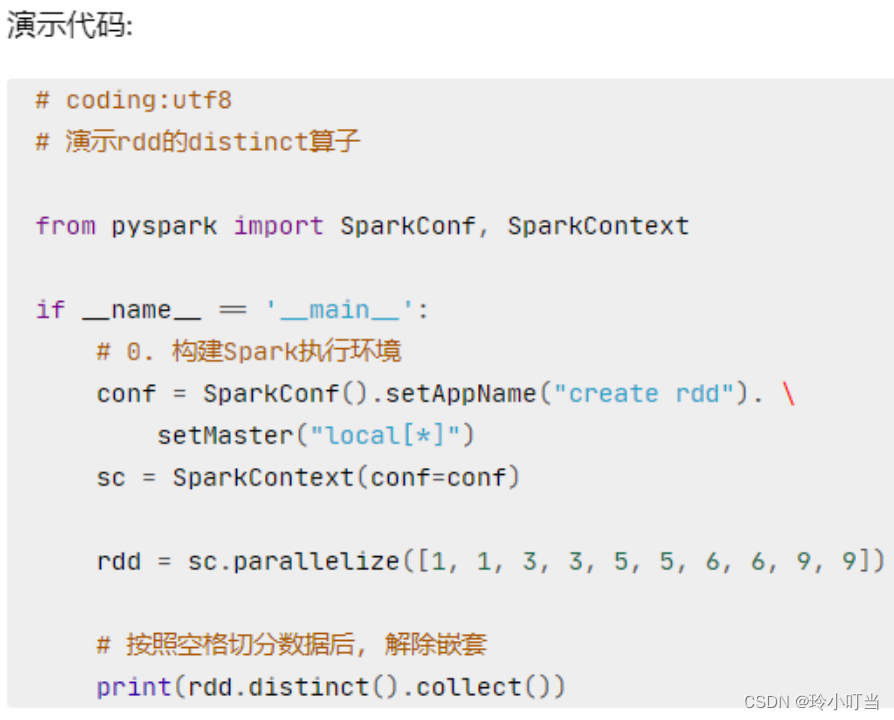
4.5 distinct算子
distinct算子: 完成对RDD内数据的去重操作
4.6 sortBy算子
sortBy算子:
- 接收一个处理函数,可用lambda快速编写
- 函数表示用来决定排序的依据
- 可以控制升序或降序
- 全局排序需要设置分区数为1

五、数据输出
数据输出的方法:
- collect:将RDD内容转换为list
- reduce:对RDD内容进行自定义聚合
- take:取出RDD的前N个元素组成list
- count:统计RDD元素个数
5.1 输出为Python对象
5.1.1 collect算子
将RDD各个分区内的数据,统一收集到Driver中,形成一个list对象
# 返回值是一个list
rdd.collect()
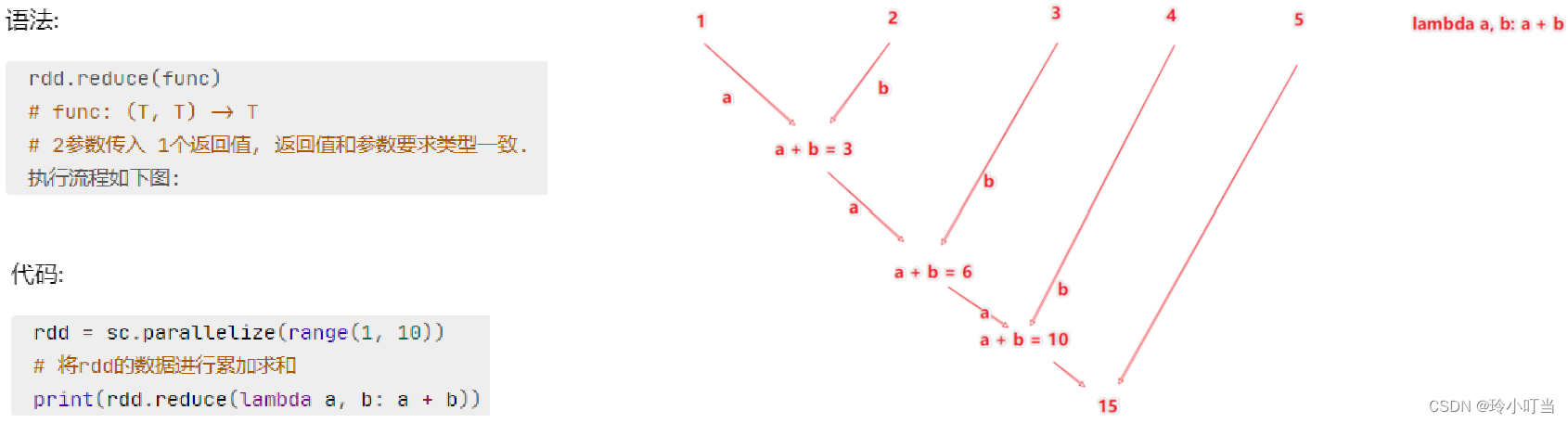
5.1.2 reduce算子
对RDD数据集按照你传入的逻辑进行聚合
5.1.3 take算子
功能:取RDD的前N个元素,组合成list返回给你

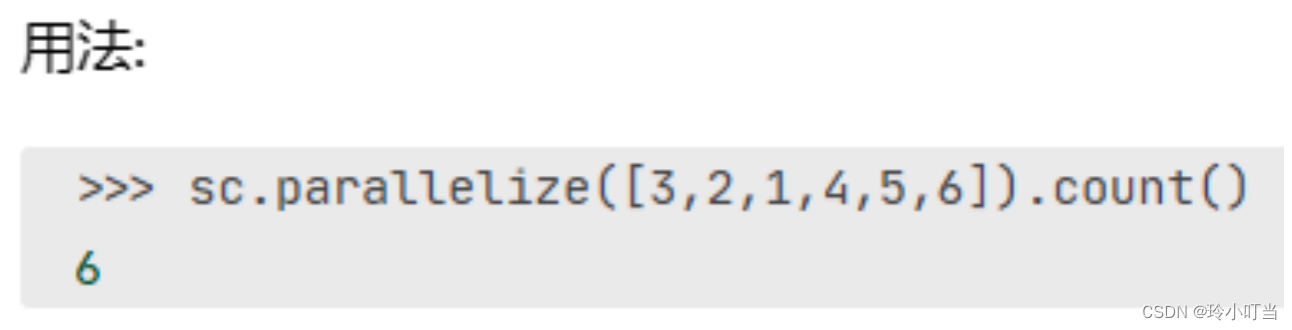
5.1.4 count算子
功能:计算RDD有多少条数据,返回值是一个数字
5.2 输出到文件中
5.2.1 rdd.saveAsTextFile算子
功能:将RDD的数据写入文本文件中
支持本地写出,hdfs等文件系统
注意事项:
调用保存文件的算子,需要配置Hadoop依赖
- 下载Hadoop安装包
- http://archive.apache.org/dist/hadoop/common/hadoop-3.0.0/hadoop-3.0.0.tar.gz
- 解压到电脑任意位置
- 在Python代码中使用os模块配置:os.environ[‘HADOOP_HOME’] = ‘HADOOP解压文件夹路径’
- 下载winutils.exe,并放入Hadoop解压文件夹的bin目录内
- https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/winutils.exe
- 下载hadoop.dll,并放入:C:/Windows/System32 文件夹内
- https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/hadoop.dll

5.2.2 修改rdd分区为1个
方式1,SparkConf对象设置属性全局并行度为1:

方式2,创建RDD的时候设置(parallelize方法传入numSlic在这里插入代码片es参数为1)

总结
以上就是python - PySpark,之后会持续更新,欢迎大家点赞关注呀~~















 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









