






1. 总结脚本高级命令trap, install, mktemp, expect, 进程优先级命令:nice, renice, 进程管理工具: ps, pstree, prtstat, pgrep, pidof, uptime,mpstat,top,htop, free, pmap, vmstat, iostat, iotop, iftop, nload, nethogs, iptraf-ng, dstat, glances, cockpit, kill, job, 任务相关的命令: at, crontab, 命令,选项,示例。
trap
信号是进程间通信的一种机制,而trap命令是shell进程自定义如何捕捉信号的,但是,trap不能够捕捉Tremil信号和KILL信号,即15号信号和9号信号,因为捕捉信号的目的在于可以定义一旦信号到达我们可以做什么操作,即可以定义不是其默认操作,这样一来可以想象如果一个进程可以捕捉KILL信号,那么任何人KILL他的时候他都可以说杀不死,即刀枪不入,这是不可取的。
示例:使用trap在shell脚本中捕捉SIGINT(对应信号2,ctrl+c),
trap用法
a、trap 'COMMAND' SIGNALS
b、常可以进行捕捉的信号
HUP,INT
例子:
#!/bin/bash
trap 'echo "捕捉到了"' INT
ping 8.8.8.8install
install命令的作用是安装升级软件或备份数据,install命令和cp命令类似,都可以将文件/目录拷贝到指定的地点。install允许控制目标文件的属性。
install通常用于程序的makefile,使用它来将程序拷贝到目标(安装)目录。
用法:
install [OPTION]... [-T] SOURCE DEST 拷贝文件
install [OPTION]... SOURCE... DIRECTORY
install [OPTION]... -t DIRECTORY SOURCE...
install [OPTION]... -d DIRECTORY... 创建目录
# 支持多个,类似mkdir -p支持递归
[root@mdns zaishu]#install -d dir1/dir2 dir3/dir4
[root@mdns zaishu]#ls
dir1 dir3
mktemp
mktemp 创建随机临时文件的,个人感觉规范管理,临时文件就放在tmp目录下就好
[root@localhost weijie]# mktemp wj123.XXXX //名字包含4个X wj123.kpET You have new mail in /var/spool/mail/root [root@localhost weijie]# mktemp wj123.XXXXXX //名字包含6个X wj123.oH2o4P [root@localhost weijie]# ls 1.c wj123.kpET wj123.oH2o4P
expect
spawn,开一个子进程来执行命令,
expect,期待出现某某字符,
send,如果出现某字符,则发送xxx
expect中,需要使用set来定义变量
set ip 10.10.10.10
expect的位置参数
[lindex $argv 1]
例子:
#!/bin/bash
ip=192.168.174.158
user=root
echo "开始$ip"
/usr/bin/expect << EOF
set time 20
spawn ssh $user@$ip
expect "*\#"
send "mysql\r"
expect "*\>"
send "create database zabbix character set utf8 collate utf8_bin;\r"
expect "*\>"
send "grant all on zabbix.* to zabbix@'localhost' identified by '123456';\r"
expect "*\>"
send "flush privileges;\r"
expect "*\>"
send "quit\r"
#interact
expect eof
EOF
nice
启动时调整进程优先级的,相当于优先级高的进程能分配更多的cpu时间片
renice
可以调整正在运行的进程优先级
用法:
renice nice值 PID

ps
ps aux
ps a,与终端相关的进程
ps x 与终端无关的
ps u 更丰富
ps aux 比ef更好
ps axo 可以指定列
ps -auxk -%cpu,按cpu排序 -%cpu 与%cpu一个正序一个倒序
%mem同理
ps auxf f显示父子关系

pstree
查看进程树
方括号括起来的是线程
prtstat
prtstat pid,查看一个进程的详细信息

pgrep
pgrep 相当于 ps xx|grep 这种
pidof
Usage:
pidof [options] [program [...]]
用来检索命令或者进程的名字,返回进程id
利用pidof命令,可以省略ps与grep组合命令,直接把指定命令的进程ID写入到标准输出。
uptime
显示系统上线时间和负载

mpstat
监控cpu指标的命令

top
动态查看系统资源情况的工具

第一列其实是uptime的返回。
load average:系统负载,即任务队列的平均长度。三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。1,5,15分钟的情况
Tasks:进程数,running(正在运行的) sleeping(睡眠状态的),stopped(停止态),zombie(僵尸态)
Cpus:cpu时间,us(用户空间占用的cpu时间),sy(内核空间占用的cpu时间),ni(由用户进程空间内改变过优先级的进程占用 CPU 百分比。它是系统所有进程发生了用户态到系统态的调度,一个进程的用户态到另一个进程用户态间的调度,他们总的占用 CPU 时间比。),id(空闲时间),wa(wait,等待输入输出的CPU时间百分比,如等待磁盘io),hi(hardware interrupt,网卡等硬件发送中断信号,cpu处理消耗的时间,) si(software interrupt,软件发送的中断指令,cpu处理消耗的时间),st(被虚拟机偷走的时间)
MiB mem:total(总内存)free(空闲的内存)used(使用的内存)
buffer,缓冲区,比如a往一个文件写东西,b也往一个文件写东西,可以先丢缓冲区里,一段时间后再一起写,减少io次数
cache,缓存
我想访问一个文件,先写到缓存里,然后再放内存中。。缓存还存留,方便下次再次访问,提高读取的速度
swap,交换分区,对于内存不足的情况下,会将内存中长时间未访问的数据放到swap空间里,需要用到的时候再交换出来,所以叫交换分区。
PID,进程ID,是唯一标识进程的
USER,进程属于哪一个用户的
PR,优先级,rt是实时优先级
NI,nice值,越低优先级越高
htop
比top功能跟丰富,是菜单式的,PID这一列可以鼠标点击下就可以排序,F1这种也可以鼠标点击,进程的一行也可以点击

常见用法:

free
查看内存占用,free -h

方便写脚本的时候用。
pmap
process memory map)命令用于查看进程的内存映射
pmap 1(进程id)
vmstat

b,等待io完成的进程数
si,so,swap in/swap out ,从交换分区进出的数据量
bi/bo ,从块设备进出的数据量 (blocks/s)
其余详见man vmstat
iostat
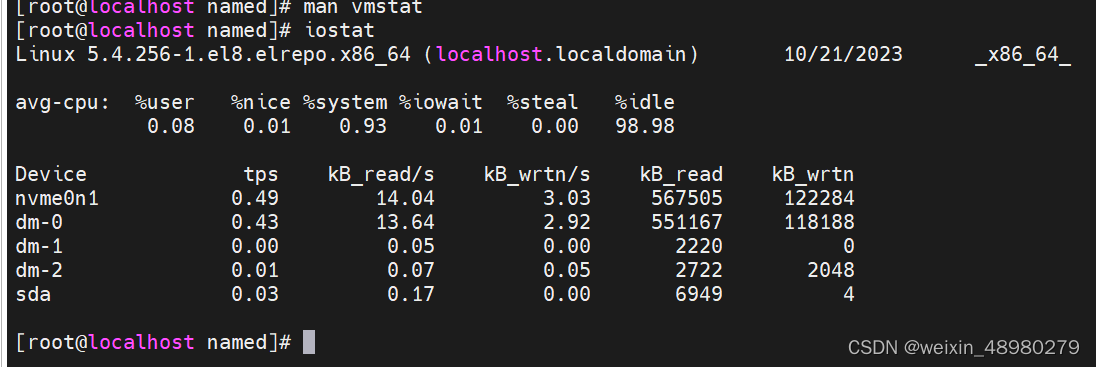
tps,等于IOPS,每秒的传输次数
iotop

显示正在进行io的进程,iotop -o,TID(线程id)
iftop
网卡实时流量监控工具
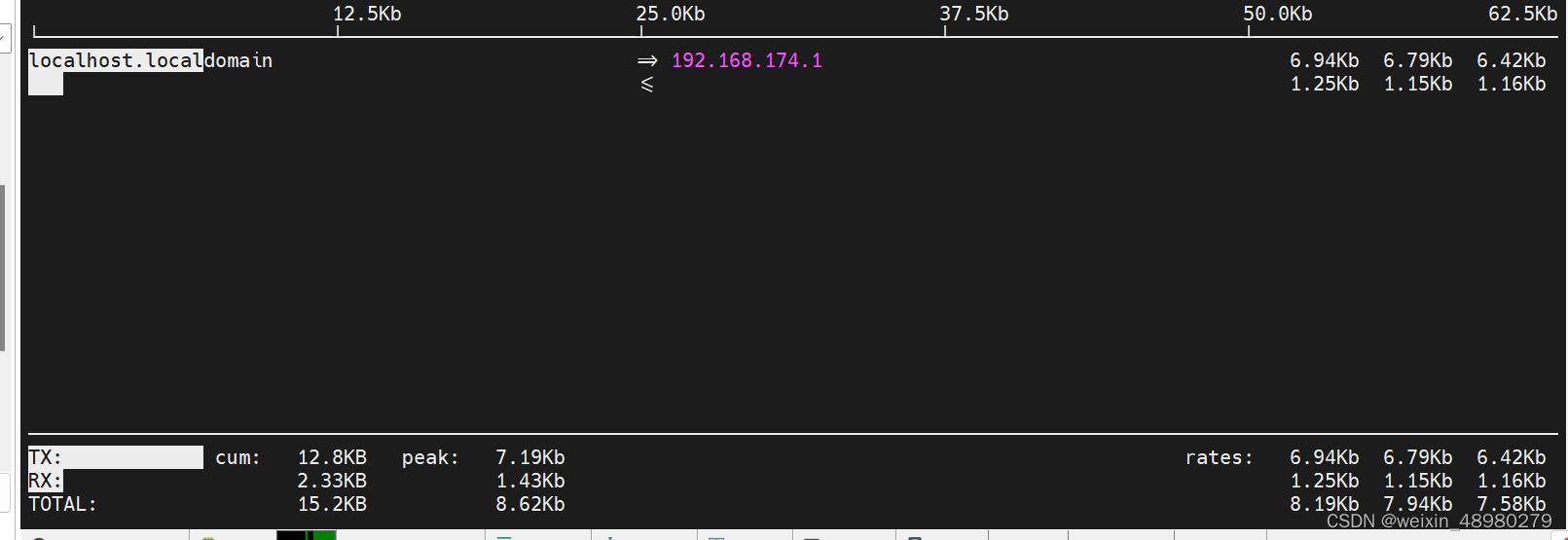
nload
也是网卡流量工具,有一个总的流量
nethogs
流量监控
iptraf-ng
dstat

glances

cockpit
一个web界面的linux网管,可以考虑进行二开,嵌入到集中网管里面
kill
kill命令用于向运行中的进程发送信号,默认发送的信号是终止信号,会请求进程退出。kill(杀)可能会引起误解,实际上发送的信号可能与杀死进程无关
默认是发送15信号,打比方:15信号是正常关机按钮关机,9信号是直接暴力拔电源关机。
job
jobs命令是一个阉割版本的ps,只能查看当前shell运行的后台进程。通过jobs来管理后台进程。jobs管理后台进程,也是使用kill命令,只不过,kill命令本身也可以向job id发送相应的信号。
当前台进程运行时,可以使用ctrl+c停止该进程,也可以使用ctrl+z将该进程放到后台,注意,当个进程由前台切换到后台时(ctrl+z),那么该进程的状态就会变成stop,如果你想继续运行该进
程,需要使用kill命令发送让该进程继续运行的信号。
at
一次性的定时任务
crontab
周期性定时任务,*****,分时日月周
所有时间的关系是是并且,但是分时日月周中 ,定义的日与周可能冲突,这个就是或者的关系
2. 总结索引数组和关联数组,字符串处理,高级变量使用及示例。
索引数组,相当于数组下标就是从012开始算,关联数组属于下标自定义的。关联数组必须先声明,
declare -A array,声明关联数组
declare -a array 声明普通数组
declare定义的变量在函数中默认是局部变量,如果想全局生效,那就加上参数-g
数组赋值:
weekday[0]="aaa"
或者一次性赋值,weekday=(a,b,c)
echo ${weekday[0]}
打印全部echo ${weekday[*]}
生成数字weekday=({1..10})
可以跳过几个取元素:
echo ${weekday[*]:3:4} 3是offset,4是取的个数
查看数组个数
加一个#号
echo ${#weekday[*]}
可以使用这个来添加新的数组元素,因为数组是从0开始计算的
weekday[${#weekday[*]}]="aaa"
字符串处理
字符串切片:
var=“abcde”
${var:2:3},从第二个开始取,取三位
${var:2:-3}
基于模式切片:
例:url=1.1.1.1 — The free app that makes your Internet faster.
echo ${url#*/},剪切匹配到的之前的字符,懒惰模式,找到一个就算
echo ${url##*/},,找到一个继续往后面找,直到最后一次,这个叫贪婪模式。
echo ${url%%*/},,往前取
搜索替代
{url/a/b},与sed相似
{url//a/b},贪婪
eval
eval会执行两次扫描,第一次命令行的扫描替换,第二次再执行
shell是一次性的处理,看见变量就替换后,就不展开{},需要用到eval
变量间接引用
变量的值是第二个变量的名称
x=y
y=n81
echo \$$x,第一个$转义下
eval echo \$$x ,就可以直接取出x=n81这种操作来
或者echo ${!x},也可以取出来
在这个里面!等同于$符号,${$x},不支持这个写法,所以用${!x
3. 求10个随机数的最大值与最小值。
[root@localhost ~]# cat paixu.sh
#!/bin/bash
declare -a array
array_create()
{
for i in `seq 0 9`
do
array[$i]=$RANDOM
done
echo ${array[*]}
}
sort_max()
{
for ((j=1;j<=9;j++))
do
h=$[j-1]
if [ ${array[$j]} -gt ${array[$h]} ];then
max=${array[$j]}
else
max=${array[$h]}
fi
done
echo "max is $max"
}
sort_min()
{
for ((j=1;j<=9;j++))
do
h=$[j-1]
if [ ${array[$j]} -lt ${array[$h]} ];then
min=${array[$j]}
else
min=${array[$h]}
fi
done
echo "min is $min"
}
array_create
sort_max
sort_min
[root@localhost ~]# sh paixu.sh
1765 20666 8978 10401 29616 12162 934 3731 25105 25781
max is 25781
min is 25105
[root@localhost ~]#
4. 使用递归调用,完成阶乘算法实现。
[root@localhost ~]# cat digui.sh
#!/bin/basih
sum=1
digui()
{
sum=$[$1*$sum]
if [ $1 -eq 1 ];then
echo $sum
else
b=$[$1-1]
digui $b
fi
}
digui $1
[root@localhost ~]#
[root@localhost ~]# sh digui.sh 5
120
[root@localhost ~]#
3. 解析进程和线程的区别?
pstree中,花括号里面就是线程
花括号,叫线程
一个进程里面至少有一个线程
线程进程区别:
比如706办公室,一个人带工位就是线程,共用的工器具就是进程的资源。
线程最大的优势就是开销小
cat /proc/pid/status 中的threads的数量就是线程数
ll /proc/pid/exe 可以看到用的哪一个二进制程序启动的
4. 解析进程的结构。
进程 = 加载到内存的程序 + 进程控制块
这里的进程控制块可以用一个结构体来表示 task_struct
存(pid,ppid,打开文件,信号,线程信息等等等)
5. 解析磁盘中的代码如何在计算机上运行的?
1.程序就是以文件的形式存在磁盘中
2.运行此程序的时候,通过程序加载器(比如exe文件)给他加载到内存中

3.内核会为加载到内存中的代码和数据创建一个进程控制块(PCB,进程的元数据(pid,ppid等),类似于c语言的结构体),进程控制块记录着当前进程的属性信息,如程序代码的指针、进程的优先级等各种信息(除了PCB,还有虚拟地址空间、页表等内容)

这个时候,进程才算创建完了
6. 总结OOM原理,及处理方法。
内核通常在分配内存时,允许申请的内存量超过实际可分配的free内存,这种技术称为Overcommit,可以认为是一种画大饼的策略。开启了Overcommit,其实是基于一个普遍的规律——大部分应用并不会将其申请的内存全部用满——来尽量提升内存的利用率,可以允许系统分配出的内存总和超过系统能提供之和(物理内存+Swap空间),但是这种做法也导致OOM的风险
通常oom_killer的触发流程是:进程A想要分配物理内存(通常是当进程真正去读写一块内核已经“分配”给它的内存)->触发缺页异常->内核去分配物理内存->物理内存不够了,触发OOM。
当系统物理内存不足时,oom_killer遍历当前所有进程,
根据进程的内存使用情况进行打分,然后从中选择一个分数最高的进程,杀之取内存。处理方法:
触发oom后,在系统日志massage中有记录,先查看是哪一个进程被杀死了,有网管记录的话,查看故障之前的内存占用趋势。用内存泄漏监测工具,及时释放未使用的内存资源,增加物理内存等
7. 结合进程管理命令,说明进程各种状态。
(1) R 运行状态running
表示当前进程在运行队列中或者正在运行

(2) S 睡眠状态
进程在等待事件的完成,可以归为等待状态的一类(该状态可以被中断,然后切换到其他状态)
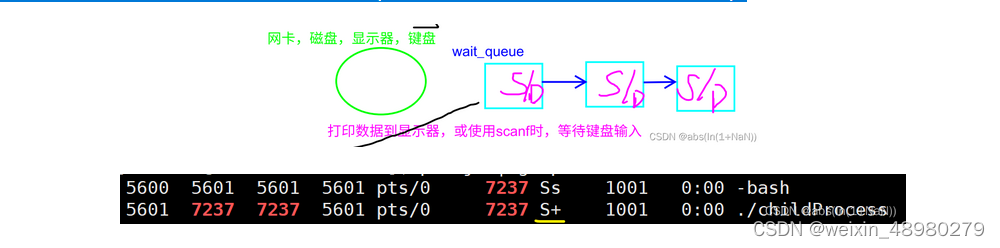
(3) D 磁盘休眠状态
也叫做“ 深度睡眠状态 ”(该状态下的进程无法被立即中止,即便是OS也无法中止该进程)
为什么会存在这种状态呢??

磁盘加载到内核内存,然后复制给进程内存,期间需要让他睡眠,腾出cpu时间给别进程用
假设某个进程在向磁盘传输数据,这个时候,OS路过,发现进程在休眠,于是该进程被kill了
磁盘存好数据以后,发现进程没了,数据传输的结果不知道应该给谁?
这个时候是谁的问题? OS ?进程 ?
为了避免OS误杀,如果进程处于D状态,OS也无法中止这个进程,只能等待IO结束
(4) T 停止状态
暂停在内存中,不会被调度,除非手动启动
发送SIGSTOP信号给进程来停止进程,暂停的进程可以发送SIGCONT信号让进程继续运行
(5) X 死亡状态
这个状态只是一个返回状态,无法在任务列表中观察到
3、进程的异常状态
上述所说的,都是进程的正常状态,但是存在两种异常状态,会对内存造成影响
(1) 僵尸进程
僵尸可以理解为僵化的尸体,僵化的尸体不作处理,就会危害到周围环境
什么时候会出现僵尸进程呢? 原本子进程运行完,会进入“死亡”状态,需要父进程回收(获取子进程的退出码) 但是!!此时父进程挂了后,子进程“死亡”以后,无人回收,一直在占用资源 此时的子进程就是僵尸进程 ,需要托孤给init进程

(2) 孤儿进程
孤儿可以理解为没有双亲
为什么会出现孤儿进程?? 当父进程先退出了,也就是“死亡”了,只留下孤零零的子进程,没人回收 这个时候,子进程就会变成孤儿进程 但是不要紧,父进程先退出了,子进程会被1号Init进程领养,也就是回收
(3) 僵尸进程的危害
子进程退出,父进程在忙,此时子进程无人回收,一直在占用资源
- 进程控制块(PCB)也要一直维护这个进程
- 创建的task_struct(PCB) 也要一直占用内存
这样会造成很多内存泄漏!
8. 说明IPC通信和RPC通信实现的方式。
IPC,进程间通信
RPC,远程过程调用
同一主机:
管道
mkfifo /data/test.fifo ,单向的
有人读取后就输入就退出了
socket
双向传输,套接字文件
文件映射,
共享内存
信号
锁,lock,互斥锁,因为有些事务是不能并行执行的
信号量
不同主机:
socket:ip地址加端口号
RPC,远程过程调用
MQ,消息队列
9. 通过mkfifo, cat, 来解释秒杀的并发问题,如何通过队列解决的?最好结合图形。说明消息队列的作用?
在Linux中,mkfifo命令可以创建FIFO(命名管道),通过FIFO可以实现进程间通信。而cat命令则可以读取FIFO中的数据。
假设有一个秒杀场景,多个用户同时发起秒杀请求,如果直接处理请求,可能会导致并发问题。这时可以通过FIFO来解决。
具体做法是,先创建一个FIFO,多个用户的请求都写入FIFO中,然后由另外一个进程(例如Web服务器)读取FIFO中的请求,进行处理。这样就可以避免多个请求同时被处理的问题。
消息队列也是基于此(解耦,异步,削峰),对于突发的请求,直接发送给服务器,不一定能全部处理过来,可以先丢到一个队列里,服务器进行读取,逐步处理。
10. 总结Linux,前台和后台作业的区别,并说明如何在前台和后台中进行状态转换。
在Linux中,前台作业指的是当前屏幕上正在执行的,比如top显示资源,此时就无法执行其他的程序了。后台作业指的是在后台运行的任务,这些任务不需要用户输入,可以在后台运行并继续执行其他任务。以下是前台和后台作业的区别:
1、用户交互:前台作业需要等待用户输入,而后台作业不需要用户输入。
2、运行状态:前台作业一直处于运行状态,直到任务执行完毕或被中断,而后台作业可以在后台继续运行。
3、输出:前台作业的输出会显示在终端上,而后台作业的输出不会显示在终端上。
4、在前台和后台之间进行状态转换可以使用以下命令:
5、将前台作业转换为后台作业:在终端中按下Ctrl + Z,该任务将被暂停,并且可以使用“bg”命令将其转换为后台任务。
6、将后台作业转换为前台作业:在终端中使用“fg”命令将后台作业转换为前台作业。
11. 总结内核设计流派及特点。
Linux内核设计流派分为两种:
微内核设计流派:将操作系统的核心功能放置在内核空间之外,只在必要时通过消息传递与内核进行通信。典型的微内核设计流派有Mach、L4等。Linux曾经也有过微内核设计的尝试,但是最终还是采用了单内核设计。
单内核设计流派:将操作系统的核心功能全部放置在内核空间中,并且以模块化的方式进行组织。典型的单内核设计流派有Unix、Linux等。
Linux内核采用的是单内核设计流派,其特点如下:
单内核设计,所有操作系统的核心功能都在内核空间中实现,提高了操作系统的运行效率。
模块化设计,可以根据需要动态加载或卸载模块,减少内核体积,提高了系统的可扩展性和灵活性。
多任务设计,支持多任务并发运行,提高了系统的并发能力。
按需调度,根据进程的优先级和调度策略,动态地分配CPU资源,提高了系统的响应能力和效率。
支持虚拟内存,将物理内存和磁盘空间组合起来管理,提高了系统的内存利用率和可靠性。
支持文件系统,将文件和目录组织起来,提供了方便的文件访问接口。
支持网络协议栈,提供了丰富的网络通信功能,支持多种网络协议。
总之,Linux内核采用了单内核设计,并且以模块化、多任务、按需调度、支持虚拟内存、文件系统和网络协议栈等特点,使其成为一款高效、可扩展、灵活的操作系统内核。
12. 总结centos 6 启动流程,grub工作流程
CentOS 6启动流程:
BIOS:通电后,先进行BIOS自检,检测硬件设备(内存条,cpu等)是否正常。
主引导记录(MBR):BIOS自检完毕后,会读取第一个扇区的MBR程序。
GRUB引导程序:MBR程序会读取安装在操作系统根分区的GRUB引导程序,把控制权交给GRUB。
GRUB菜单:GRUB会显示菜单,让用户选择要启动的操作系统或内核(启动界面的那个选择菜单)。
内核启动:用户选择后,GRUB会启动相应的内核,并把参数传递给内核。
init进程启动:内核启动后,会启动init进程,它是所有进程的父进程。
运行级别:在CentOS 6中,运行级别是由/etc/inittab文件指定的。init进程会读取该文件,并根据默认运行级别加载相应的服务。
启动服务:在相应的运行级别中,init进程会启动一系列服务,包括网络服务、文件系统服务、安全服务等。
用户登录:所有服务启动完成后,系统就进入了用户登录状态,用户可以使用用户名和密码登录系统。
Grub工作流程:
BIOS自检完成后,会把控制权转交给位于磁盘第一个扇区的MBR程序。
MBR程序会读取安装在操作系统根分区的GRUB引导程序。
GRUB引导程序会显示菜单,让用户选择要启动的操作系统或内核。
用户选择后,GRUB引导程序会加载相应的内核,并把参数传递给内核。
内核启动后,会启动init进程。
13. 手写chkconfig服务脚本,可以实现服务的开始,停止,重启。(跳过)
14. 总结systemd服务配置文件
服务配置文件采用INI格式,分为[Unit]、[Service]和[Install]三个部分。
[Unit]部分:用于定义服务名称、描述、依赖关系等信息。
[Service]部分:用于定义服务的启动方式、执行命令、环境变量等信息。
[Install]部分:用于定义服务的安装方式、启动级别等信息。
[Unit]
Description=Apache Web Server
After=network.target //在哪个后面才启动,相当于前面启动的是后面的依赖
[Service]
Type=forking
ExecStart=/usr/sbin/httpd -DFOREGROUND
EnvironmentFile=/etc/sysconfig/httpd
User=apache
Group=apache
Restart=always
[Install]
WantedBy=multi-user.target //一般在设在此target下,多用户模式
15. 总结system启动流程
1、BIOS/UEFI阶段
当计算机开机时,BIOS/UEFI会进行自检并加载启动设备。在加载设备时,如果发现有可引导的设备,BIOS/UEFI会将控制权转移到该设备的引导扇区。
2、GRUB阶段
GRUB(GRand Unified Bootloader)是一个多操作系统的引导加载程序。它会加载内核文件和初始化RAM磁盘。GRUB会在启动时显示一个菜单,让用户选择要启动的操作系统或内核版本。
3、内核引导阶段
内核是操作系统的核心部分,它会被加载到内存中并初始化系统硬件。在这个阶段,内核会执行以下任务:
加载驱动程序:例如,加载硬件驱动程序和文件系统驱动程序。
挂载根文件系统:内核会在启动时挂载根文件系统,该文件系统包含了操作系统的所有文件和目录。
运行init程序:在CentOS 7中,init程序被替换为systemd。
4、systemd阶段
systemd是一个系统和服务管理器,它会在CentOS 7中代替传统的init程序。它会执行以下任务:
启动各种服务:例如,网络服务、SSH服务和防火墙服务。
挂载文件系统:systemd会挂载其他文件系统,例如,/tmp和/var。
启动用户进程:systemd会启动用户进程和守护进程。
总结起来,CentOS 7的启动流程可以简要描述为:BIOS/UEFI -> GRUB -> 内核引导 -> systemd。
16. 总结awk工作原理,awk命令,选项,示例。
可以把awk看作一种程序语言
程序放在‘’里面比如‘{print $1}’
awk也是逐行处理
BEGIN END,就优先打印这个
awk{}里,如果不加双引号,就会把他当变量使用
awk的分割,不管你几个空格,都算一个分隔符
{print $1}这种
-F“%”指定分隔符
{print $1" ==="$2 },自己筛出来的===隔开
awk,有自定义变量,内置变量
内置变量:
FS:类似于-F
使用变量时候需要加-v
awk -v FS=“:” '{print $1}'
比-F好的是可以在‘’里面变量引用,如{print $1FS$3}
$0,表示此行的所有内容
列于列之间默认空格分割,使用OFS=xxx,可以指定最终的分隔符
RS,分行符,默认是换行
ORS
NF,总共有多少列
NR,行号,比如不想打印第一列,可以实现行的过滤
自定义变量可以在外面复制也可以在里面赋值
17. 总结awk的数组,函数。
awk ‘!array[$0]++’
awk的数组都是关联数组
awk支持内置函数和自定义函数两种类型的函数。
自定义函数,awk支持自定义函数,使用关键字function定义函数。自定义函数可以接受参数,也可以返回值。
18. 总结ca管理相关的工具,根据使用场景总结示例。
OpenSSL是一个开源的加密工具库,也是一个命令行工具集,支持SSL和TLS协议,可以用于生成和管理证书和密钥等操作。
使用OpenSSL生成自签名证书:
| 1 2 3 4 5 6 |
|
使用cfssl签署证书请求:
| 1 2 3 4 |
|
使用OpenSSL生成证书吊销列表并吊销证书:
| 1 2 3 4 |
|
使用easy-rsa生成服务器证书和密钥:
| 1 2 3 4 5 6 |
|
19. 总结openssh免密认证原理,及免认证实现过程。
现有加密方式中,经常结合对称加密与非对称加密来使用(一般都在建立连接的时候用非对称,连接建立后的持续数据交互用对称加密),比较关键且数据量小的数据,如对称密钥,可以采用非对称加密来传输,数据量大的用非对称加密的话速度就很慢。
ssh免密原理:
1.首先ssh客户端生成自己的公钥与私钥(ssh-keygen),然后把公钥拷贝到服务器的(authorized_keys文件中),建议使用ssh-copy-id拷贝。
2.下次登录时,客户端向服务器发送请求,服务器从authorized_keys中寻找这个用户的pubkey,并生成随机数R,服务器将这个R用这个pubkey加密得到pubKey®,然后将这个pubKey®发送给客户端
3.客户端利用自己的私钥解密这个pubKey®,得到R,然后对R和本次会话的SessionKey利用MD5生成摘要Digest1,发送给服务器
4.服务器也对R和本次会话的SessionKey利用同样的摘要算法生成Digest2,对比Digest1和Disgest2是否相同,从而完成认证过程















 116
116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









