






wallhaven的热度壁纸爬取
首先介绍一下wallhaven
wallhaven这个壁纸网站是一个壁纸质量十分高的网站,最主要它还是一个免费的壁纸网站,于是突发奇想想去爬取一下里面的热度壁纸,在博客上看过许多大佬的作品,终于有一点思路,于是借鉴了这位大佬的成果。
大佬的博客链接:
https://blog.csdn.net/qq_29367075/article/details/111940621
过程
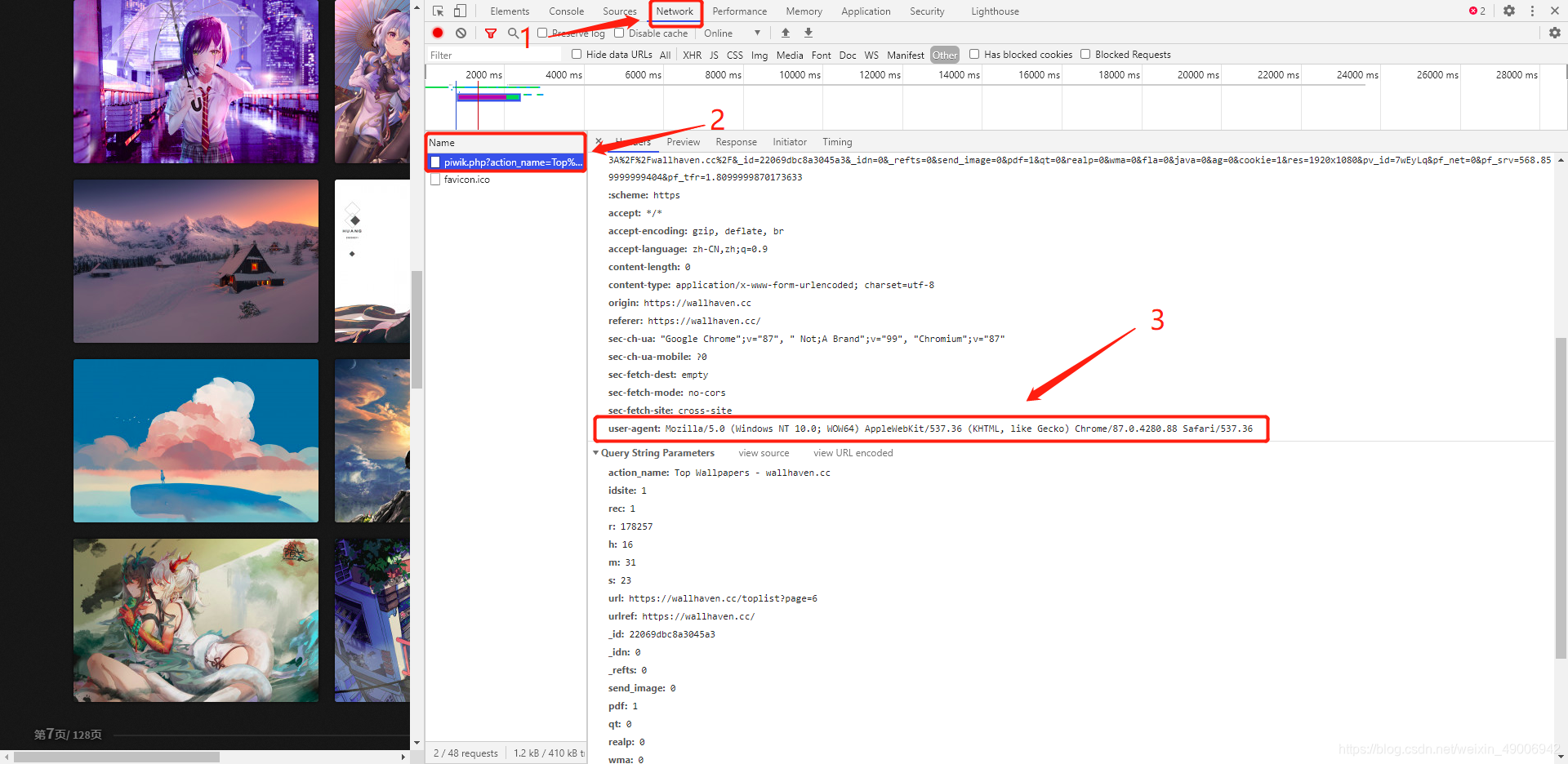
1.我们要开始爬虫,需要先设置一个headers,将我们书写的爬虫伪装成为浏览器,打开我们的网页,按下F12,按照如下步骤获取user-agent
2.第二步当然是获取需要爬取的网站网址,这里我们爬取的是wallhaven热度榜,网址如下:https://wallhaven.cc/toplist?page=1
3.使用request包获取网页图片缩略图的链接,获取链接我们使用正则,通过观察我们发现图片的缩略图都是在w/后面有6位字符,所以我们在使用正则进行匹配的时候可以这样:
reg = r"""<a.*?href="(https://wallhaven.cc/w/......)".*?</a>"""
reg = re.findall(reg, wall_txt)
4.之前我们获取的还只是我们想要获取图片的外衣,所以我们还需要使用request进行请求

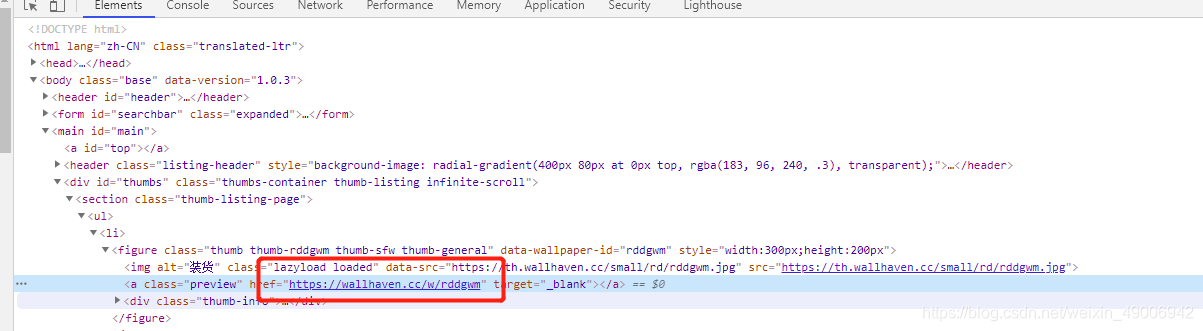
我们不难发现这个图片的真实链接,这时候我们想要获取图片就简单的多,通过观察我们发现这个图片的链接和缩略图的链接是有关联的,(主要还是在大佬的博客中发现的),如图:

所以我们在获取图片的链接的时候可以先对缩略图的链接进行字符串的分割,之后在对分割后的最后一项进行切片,最后拼接起来就完成了图片链接的获取。
5.最后由于网页有翻页,所以我们在外面套上一个for循环,使其在吧当页的内容获取完成后可以继续获取下一页。完整代码在下面;
import time
import requests
import re
for i in range(17, 127):
Referer = 'https://wallhaven.cc/toplist?page='
Referer_url = Referer + str(i)
print(f"开始第{i}页")
headers = {
"Referer": 'https://wallhaven.cc/?',
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
'Accept-Language': 'en-US,en;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
} ###设置请求的头部,伪装成浏览器
response = requests.get(headers=headers, url=Referer_url)
if response.status_code == 200:
wall_txt = response.text
reg = r"""<a.*?href="(https://wallhaven.cc/w/......)".*?</a>"""
reg = re.findall(reg, wall_txt)
pass
for j in reg:
print(j)
sp = j.split('/')
last = sp[4]
new_last = sp[4][0:2]
image_url = 'https://w.wallhaven.cc/full/{}/wallhaven-{}.jpg'.format(new_last, last)
res = requests.get(url=image_url, headers=headers)
print(res, image_url)
with open('D:/wallhaven/{}.jpg'.format(last), "wb") as f:
f.write(res.content)
tt = time.localtime()
print(f'{tt[3]}时{tt[4]}分{tt[5]}秒')














 8639
8639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









