









文章目录
理解性能测试理论
概述、策略、指标、流程
性能测试的概念
为什么要学习性能测试
满足 真实的业务场景(活动场景) \color{red}{真实的业务场景(活动场景)} 真实的业务场景(活动场景)、支持 大量的用户 \color{red}{大量的用户} 大量的用户。满足 商用 \color{red}{商用} 商用要求,如:电商双11活动、微信日常在线用户数。
性能测试的概念
性能:就是软件质量属性中的"
效率
\color{red}{效率}
效率"特性。
效率特性包含:
时间
\color{red}{时间}
时间特性:表示系统处理用户请求的响应时间。
资源
\color{red}{资源}
资源特性:表示系统运行过程中,系统资源的消耗情况。
性能测试的概念:使用
自动化工具
\color{red}{自动化工具}
自动化工具,模拟
不同的场景
\color{red}{不同的场景}
不同的场景,对
软件各项性能指标
\color{red}{软件各项性能指标}
软件各项性能指标进行测试和评估的过程。
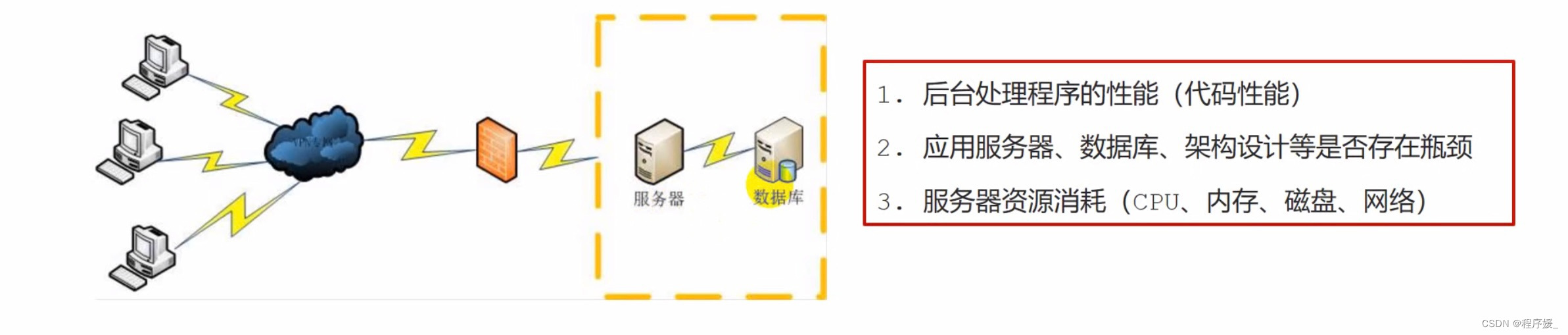
性能测试的目的:
-
评估 当前系统能力 \color{red}{当前系统能力} 当前系统能力。如:验收第三方提供的软件;获取关键的性能指标,与其他类似产品进行比较。

-
寻找性能瓶颈, 优化性能 \color{red}{优化性能} 优化性能。如:12306订票bug。
-
评估软件是否能够满足 未来的需要 \color{red}{未来的需要} 未来的需要。如:双十一热度逐年升高。
性能测试与功能测试对比
区别:
功能测试:验证软件系统操作功能是否符合产品
功能需求规格
\color{red}{功能需求规格}
功能需求规格,主要焦点在功能
(正向、逆向)
\color{red}{(正向、逆向)}
(正向、逆向);
正向(功能),例如:输入正确的用户名密码,登录成功
逆向(功能),例如:输入错误的用户名密码,登录失败给出提示
性能测试:验证软件系统是否满足 业务需求场景 \color{red}{业务需求场景} 业务需求场景,主要焦点是业务场景的满足 (时间、资源) \color{red}{(时间、资源)} (时间、资源);
例如:100w人使用正确的用户名密码登录,1s内能登录成功,——时间
同时服务器的CPU使用率低于70%,内存使用率低于60%等。——资源
关系:
一般项目中,
先功能测试
\color{red}{先功能测试}
先功能测试通过后,
再进行性能测试
\color{red}{再进行性能测试}
再进行性能测试。
性能测试的策略
基准测试
为什么要进行基准测试?
- 单用户性能不达标,有必要进行多用户性能测试吗?
- 影响性能的因素有很多(如:服务器配置、资源、代码效率),如何判断谁在导致性能变好/变坏?
什么是基准测试?
狭义上讲:就是
单用户测试
\color{red}{单用户测试}
单用户测试。测试环境确定后,对业务模型中的重要业务做单独的测试,获取单用户运行时的各项性能指标。
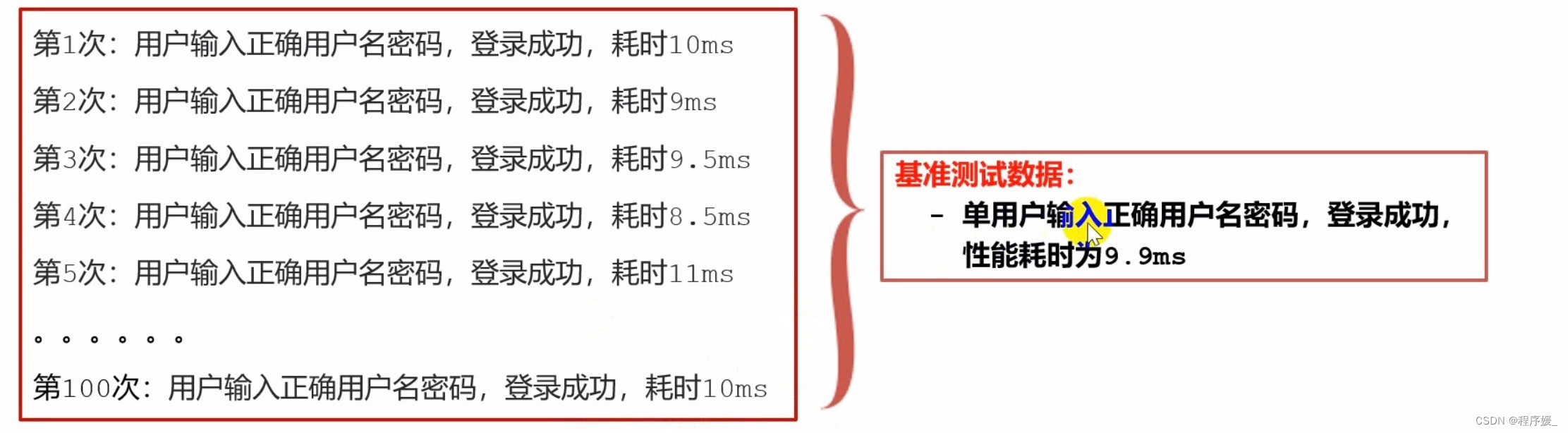
广义上讲:是一种测量和评估软件性能指标的活动。你可以在某个时刻通过基准测试建立一个已知的
性能基准线
\color{red}{性能基准线}
性能基准线,当系统的
软硬件环境发生变化
\color{red}{软硬件环境发生变化}
软硬件环境发生变化之后再进行一次基准测试以
确定变化对性能的影响
\color{red}{确定变化对性能的影响}
确定变化对性能的影响。

基准测试数据的用途?
- 基准测试不会单独存在
- 为多用户并发测试和综合场景测试等提供参考依据
负载测试
为什么要进行负载测试?
电商系统平时可以正常运行,双11时能保证也可以正常运行吗?一
用户量大
\color{red}{用户量大}
用户量大
什么是负载测试?
通过
逐步增加系统负载
\color{red}{逐步增加系统负载}
逐步增加系统负载,确定在
满足系统的性能指标情况下
\color{red}{满足系统的性能指标情况下}
满足系统的性能指标情况下,找出系统所能够承受的
最大负载量
\color{red}{最大负载量}
最大负载量的测试。
负载测试的作用?
系统
最大负载量
\color{red}{最大负载量}
最大负载量达到
用户要求
\color{red}{用户要求}
用户要求时,系统才能正式上线使用。

稳定性测试
为什么要进行稳定性测试?
电商系统能抗住双11时的考验,能保证长时间运行不出问题吗?
什么是稳定性测试?
在服务器
稳定运行(用户正常的业务负载下)
\color{red}{稳定运行 (用户正常的业务负载下)}
稳定运行(用户正常的业务负载下)的情况下进行
长时间测试(
1
天
−
1
周等)
\color{red}{长时间测试 (1天-1周等)}
长时间测试(1天−1周等),并最终保证服务器能满足线上业务需求。
稳定运行时的负载量设置为多少?
例如:前面电梯案例中,实际测试的最大负载为:13人
- 场景1:如果甲方要求用户正常的负载人数为15人,稳定运行的负载量为多少?先优化使得负载人数达到15人后再进行负载量15的稳定性测试。
- 场景2:如第甲方要求用户正常的负载人数力10人,稳定运行的负载量为多少?用户要求的10即可。
稳定性测试的作用?
系统
在用户要求的业务负载下
\color{red}{在用户要求的业务负载下}
在用户要求的业务负载下运行达到
规定的时间
\color{red}{规定的时间}
规定的时间时,系统才能正式上线使用。
压力测试
为什么要进行压力测试?
1、软件实际使用时,用户量超过预期(系统最大负载量),该如何反应?
2、软件由于意外情况出现问题,多久能恢复?
什么是压力测试?
在强负载下的测试,查看系统在
峰值情况下
\color{red}{峰值情况下}
峰值情况下是否功能隐患、系统是否具有良好的
容错能力
\color{red}{容错能力}
容错能力和
可恢复能力
\color{red}{可恢复能力}
可恢复能力。
压力测试的场景?
- 极限负载 \color{red}{极限负载} 极限负载情况下的 破坏性压力测试 \color{red}{破坏性压力测试} 破坏性压力测试
-
高负载
\color{red}{高负载}
高负载下的长时间的
稳定性压力测试
\color{red}{稳定性压力测试}
稳定性压力测试

并发测试
为什么要进行并发测试
电商系统能抗住双11时的考验,能保证在秒杀活动时不出问题吗?秒杀特点:时间短,请求量大。
什么是并发测试?
并发测试(绝对并发):是指在
极短的时间内
\color{red}{极短的时间内}
极短的时间内,发送
多个请求
\color{red}{多个请求}
多个请求,来验证服务器对并发的处理能力。
并发测试的应用场景?
特定活动场景,如:抢红包、秒杀、抢购等。
性能测试的指标
为什么要学习性能测试的指标?
如何衡量功能?有/没有;肉眼可观察,可衡量
如何衡量性能?好/不好;个人感受,不容易量化,不好衡量
对性能测试结果进行
量化衡量
\color{red}{量化衡量}
量化衡量
性能测试的指标?
一些经过运算得出的结果,来量化衡量某种操作的性能好坏;比如:错误率 0.58%
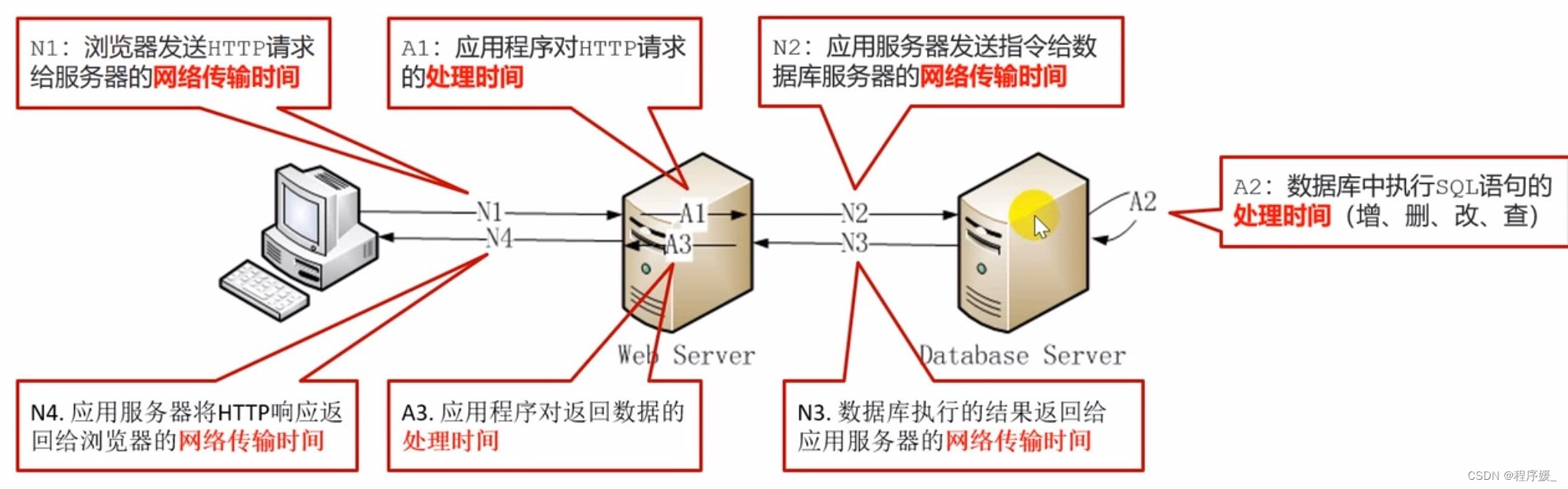
响应时间
响应时间:指用户
从客户端发起一个请求开始
\color{red}{从客户端发起一个请求开始}
从客户端发起一个请求开始,到客户端接收到
从服务器端返回的结果
\color{red}{从服务器端返回的结果}
从服务器端返回的结果,整个过程所耗费的时间。包括:
服务器处理时间
\color{red}{服务器处理时间}
服务器处理时间 +
网络传输时间
\color{red}{网络传输时间}
网络传输时间
注意:
- 通过HTTP接口消息消意来测试
- 不包括发消息时前端页面的处理时间和收到消息后前端页面的渲染显示时间
并发数
并发(用户)数:某一时刻 同时 \color{red}{同时} 同时向服务器 发送请求 \color{red}{发送请求} 发送请求的用户数。
淘宝系统案例—哪个是并发数?
场景1:淘宝商城,注册用户数有5亿。—系统用户数(系统注册的总用户数);数据库用户表的数据条数,对性能无影响。
场景2:当前登录了淘宝商城的用户数为2000万。—在线用户数(某段时间内访问过系统的用户),这些不一定同时向系统在提交请求。
场景3:目前正在刷淘宝的用户数有500万。—并发用户数(某段时间內同时向系统提交请求),请求就会产生负载。
吞吐量
吞吐量 (Througbput):指的是
单位时间内
\color{red}{单位时间内}
单位时间内处理的客户端
请求数量
\color{red}{请求数量}
请求数量,直接体现软件系统的性能承载能力。
吞吐量的单位有哪些?
- 从业务角度:业务数/天、访问人数/天、页面访问量/天
- 从网络角度:字节数/小时、字节数/ 天
- 从技术指标: Q P S (每秒请求数)、 T P S (每秒事务数 ) \color{red}{QPS(每秒请求数)、TPS(每秒事务数)} QPS(每秒请求数)、TPS(每秒事务数)

QPS(Query Per Second)每秒查询数:即控制服务器
每秒
\color{red}{每秒}
每秒处理的指定
请求
\color{red}{请求}
请求的数量。

TPS(Transaction Per Second)每秒事务数:即控制服务器
每秒
\color{red}{每秒 }
每秒处理的
事务请求
\color{red}{事务请求}
事务请求的数量。事务:即业务,页面上的一次操作,可能对应一个请求/多个请求。

QPS和TPS有什么关系?
事务,即业务。
一个事务可以对应一个请求
/
多个请求
\color{red}{一个事务可以对应一个请求/多个请求}
一个事务可以对应一个请求/多个请求
- 一个事务对应一个请求时:TPS = QPS
- 一个事务对应n个请求时: TPS = n * QPS
点击数
点击数:指客户端向服务端发送请求时,所有的
页面资源元素
\color{red}{页面资源元素}
页面资源元素(如:图片、链接、框架css、js等)的
请求总数量
\color {red}{请求总数量}
请求总数量。
注意:
- 只有web项目才有此指标
- 点击数是请求数,不是页面上的一次点击

错误率
错误率:指系统在
负载情况
\color{red}{负载情况}
负载情况下,失败业务的概率。错误率=(失败业务数/业务总数)*100%。
注意:
- 大多系统都会要求错误率 无限接近于 0 \color{red}{无限接近于0} 无限接近于0。
- 错误率是一个 性能指标 \color{red}{性能指标} 性能指标,是高负载下的失败业务的概率。
- 错误率不是功能上的 随机 b u g \color{red}{随机bug} 随机bug,先解决随机bug才能进行性能测试。
资源利用率
资源使用率:是指系统各种资源的使用情况,一般用“资源的使用量/总的资源可用量x100%”形成资源利用率的数据。
常见资源指标:
(1) CPU使用率:不高于75%-85%
(2) 内存(大小)使用率:不高于80%
(3)磁盘IO(速率):不高于90%
(4) 网络(速率):不高于80%

性能测试的流程
为什么要学习性能测试的流程?
- 被分配了性能测试任务,需要按照什么样的步骤来推进?
- 使用不同的性能测试工具时,流程会不一样吗?
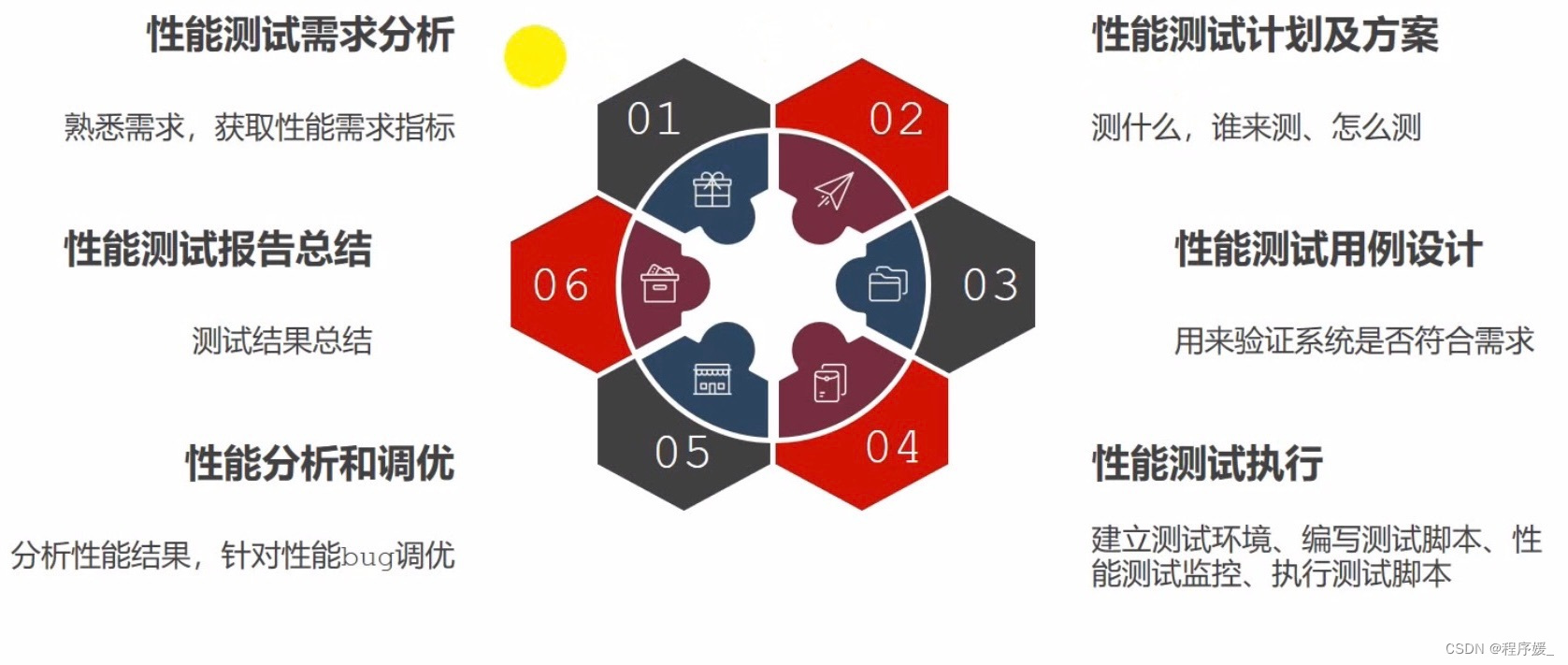
01 性能测试需求分析

02 性能测试计划和方案
- 测什么?
项目背景
测试目的
测试范围 - 谁来测?
讲度与分工
交付清单 - 怎么测
测试策略
03 性能测试用例
测试标题、测试步骤、预期结果、实际结果(系统指标、资源指标)

04 性能测试执行
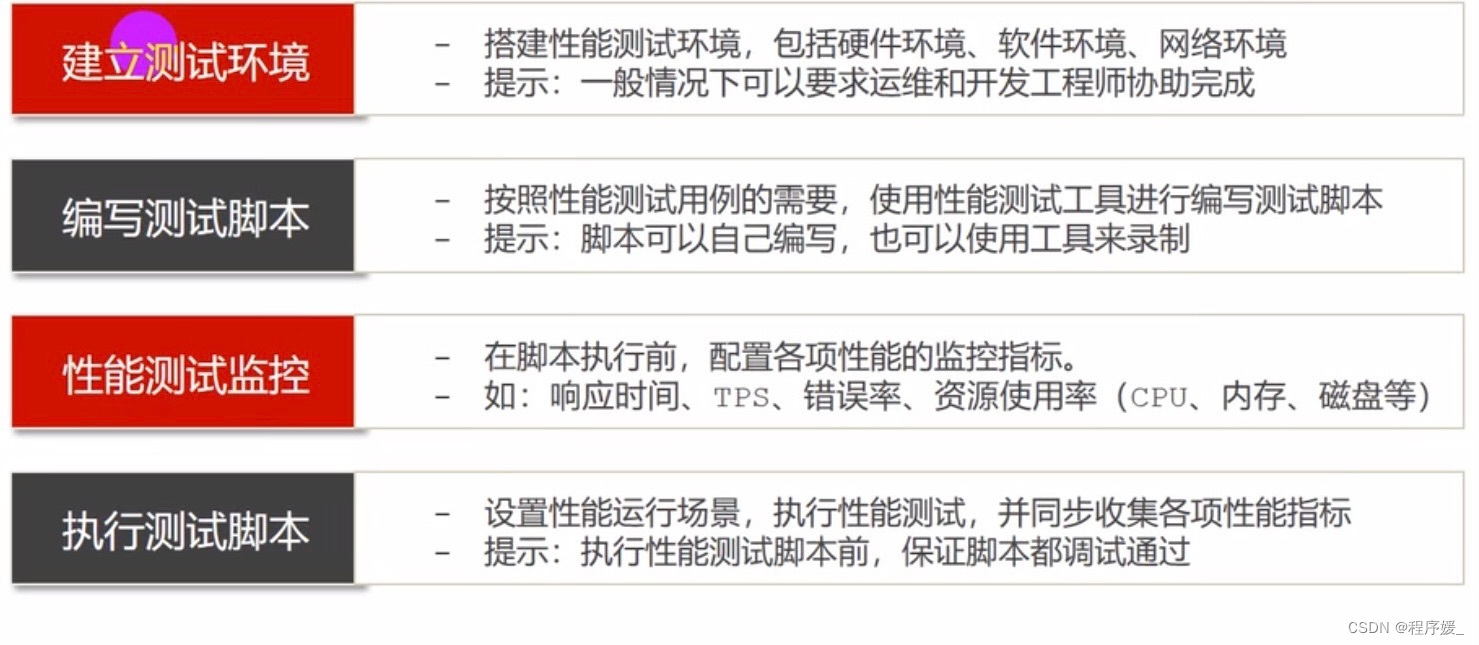
05 性能分析和调优
- 说明: 性能测试分析人员 \color {red}{性能测试分析人员} 性能测试分析人员经过对结果的分析以后,如果不符合性能需求,则会 提出性能 b u g \color{red}{提出性能bug} 提出性能bug,然后由 开发人员进行后续的调优 \color{red}{开发人员进行后续的调优} 开发人员进行后续的调优。
- 提示:
调优:开发人员为主导,数据库管理员、系统管理员、网络管理员、性能测试分析人员配合进行。
验证:性能测试人员继续进行第二轮、第三轮……的测试,与以前的测试结果进行对比,从而确定经过调整以后系统的性能是否有提升。
06 性能测试报告总结
- 测试报告是对性能测试工作的总结,为软件后续验收和交付打下基础。
- 测试报告的主要内容:
测试工作的经过回顾(测试过程记录)
缺陷分析和调优(问题分析)
风险评估(风险识别)
性能测试结果(测试结论)
测试工作总结与改进(经验教训)
掌握JMeter性能测试工具的使用
JMeter基本使用、JMeter参数化、断言、关联、JMeter录制脚本、连接数据库、分布式、测试报告等
项目实战
性能测试工具介绍
- Loadrunner
HP Ioadrunner是一种工业级标准性能测试负载工具,可以模拟上万用户实施测试,并在测试时可实时检测应用服务器及服务器硬件各种数据,来确认和查找存在的瓶颈。
支持多协议:Web (HTTP/HTML)、Windows Sockets、FTP、 ODBC、 MS SQI Server等协议。
采用C语言编写。
| 优点 | 缺点 |
|---|---|
| 多用户(支持用户以万为单位) | 收费 |
| 详细的分析报表(以秒为单位) | 体积庞大(安装包单位GB) |
| 支持IP欺骗功能 | 无法定制功能 |
- JMeter
JMeter是Apache组织开发的基于Java的开源软件,用于对系统做功能测试和性能测试。
它最初被设计用于web应用测试,但后来扩展到其他测试领域,例如静态文件、Java 程序、shell 脚本、数据库、FTP、Mail等。
| 优点 | 缺点 |
|---|---|
| 开源免费 | 不支持IP欺骗 |
| 小巧(安装包50MB左右) | 分析和报表能力相对于LR欠缺精度(以分钟为单位) |
| 丰富的学习资料和扩展组件 |
- 主流性能测试工具Loadrunner和JMeter对比
相同点:
(1)都能 模拟大量用户 \color{red}{模拟大量用户} 模拟大量用户
(2)都能 支持多协议 \color{red}{支持多协议} 支持多协议(常见的协议都支持,如:HTTP)
(3)都有 监控及分析报表 \color{red}{监控及分析报表} 监控及分析报表功能
不同点:
| 工具 | 用户量 | 分析报表 | IP欺骗功能 | 费用 | 体积 | 扩展性 |
|---|---|---|---|---|---|---|
| Loadrunner | 多(万) | 精确(秒) | 支持 | 收费 | 大(单位GB) | 不能扩展 |
| JMeter | 少 | 较差(分钟) | 不支持 | 免费 | 小(50MB) | 有扩展组件 |
| 结论:项目日常性能测试JMeter足够用,出商业报告优先Loadrunner。 |
JMeter基本使用
JMeter环境安装
参考文章:JMeter详细安装教程
功能概要
-
JDK常用文件目录介绍
bin目录: 存放 可执行文件 \color{red}{可执行文件} 可执行文件和 配置文件 \color{red}{配置文件} 配置文件
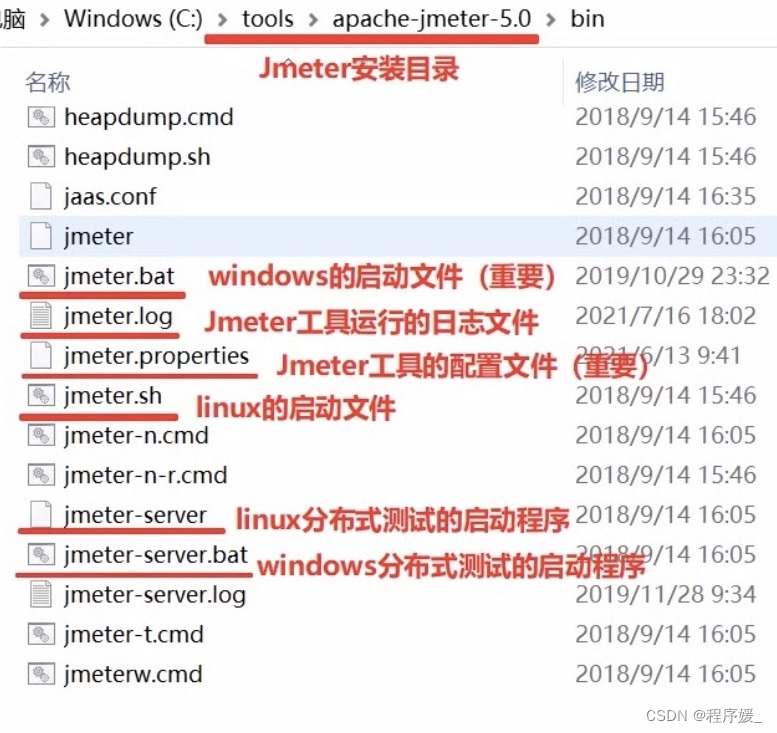
docs目录: 是JMeter的api文档,用于 c o l o r r e d 开发扩展组件 color{red}{开发扩展组件} colorred开发扩展组件
printable docs目录: 用户帮助手册 \color{red}{用户帮助手册} 用户帮助手册

lib目录: 存放JMeter依赖的iar包和用户扩展所依赖的 j a r 包 \color{red}{jar包} jar包

总结:- 修改JMeter配置文件:Bin目录
- 下载第三方插件(jar包)并使用:lib/ext目录
- 查找用户帮助手册:printable_docs目录
- 启动Jmeter程序:Bin目录
-
修改默认配置——JMeter界面的汉化
参考文章:将JMeter设置为中文的两种方法 -
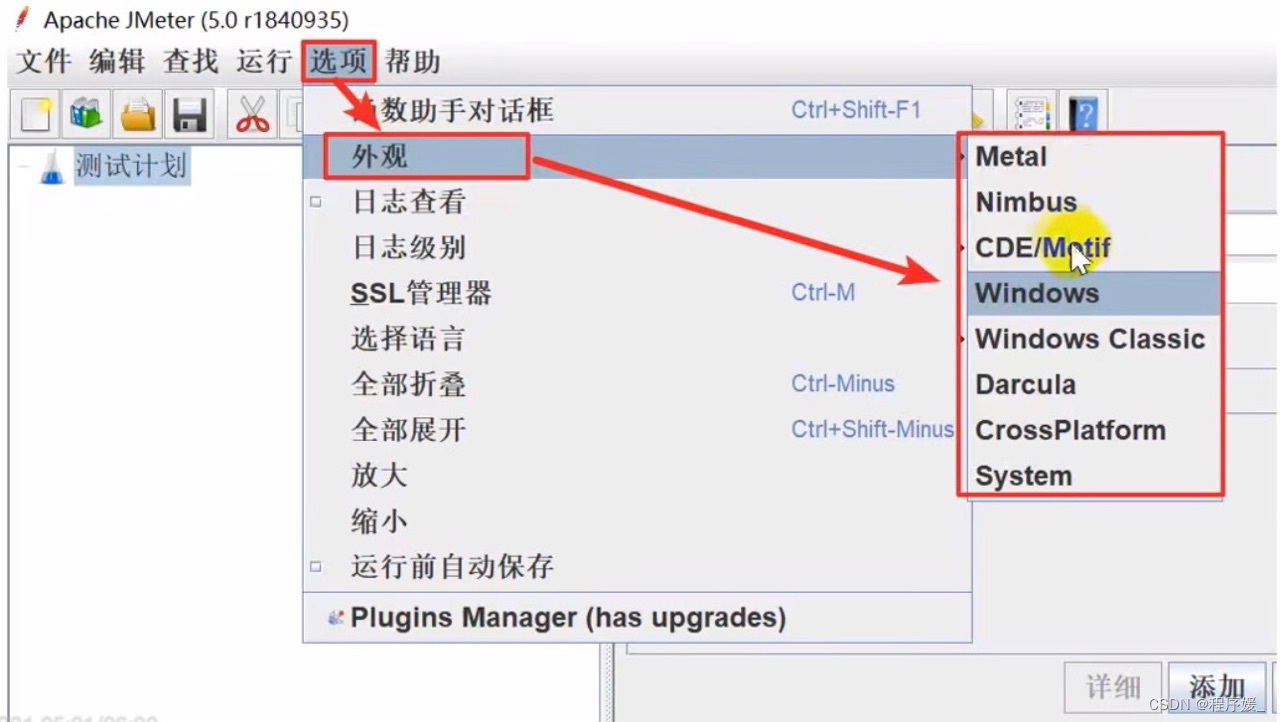
修改默认配置——修改主题
JMeter默认主题是黑色的,可以通过以下步骤修改:
启动JMeter>>选择菜单”选项”>>外观>>windows(选择自己喜欢的主题即可)
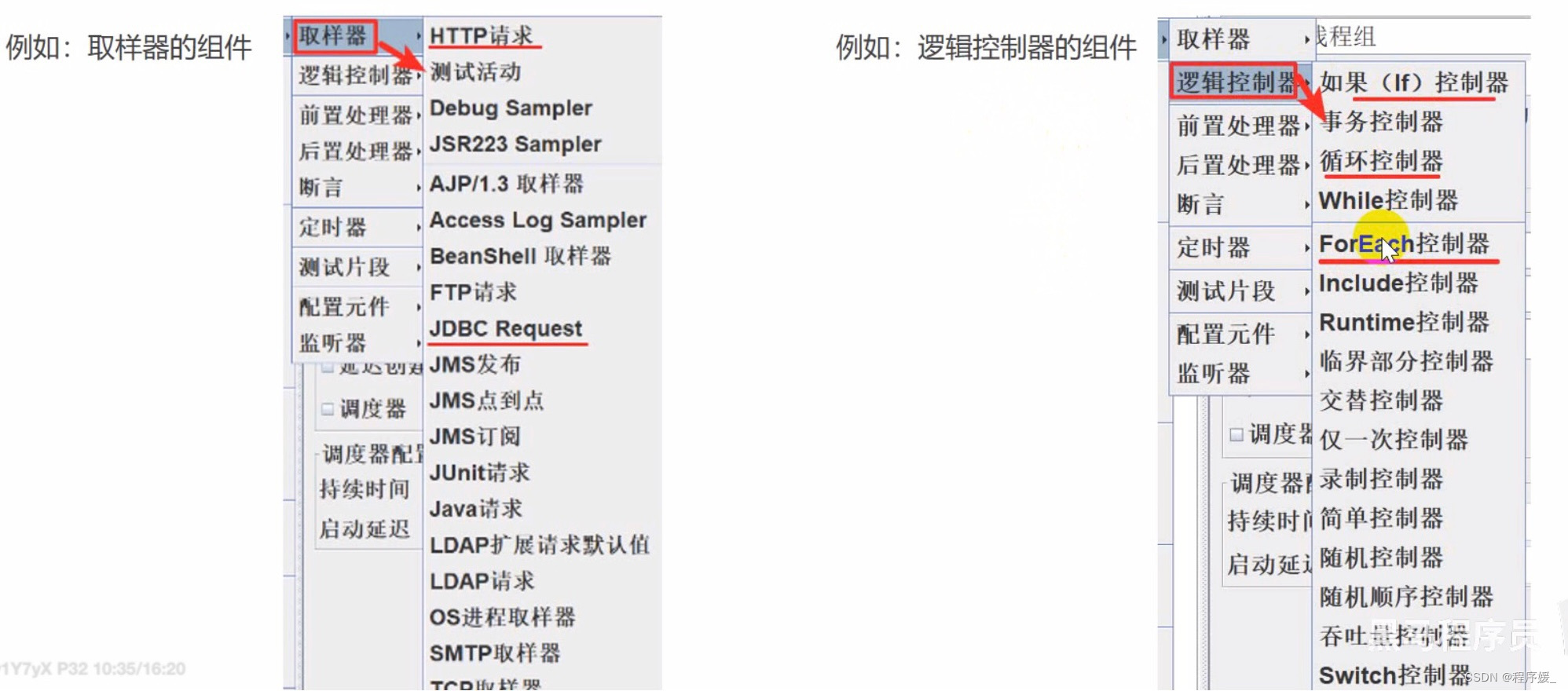
元件和组件的介绍
- 元件:多个类似功能组件的
容器
\color{red}{容器}
容器(类似于
类
\color{red}{类}
类)
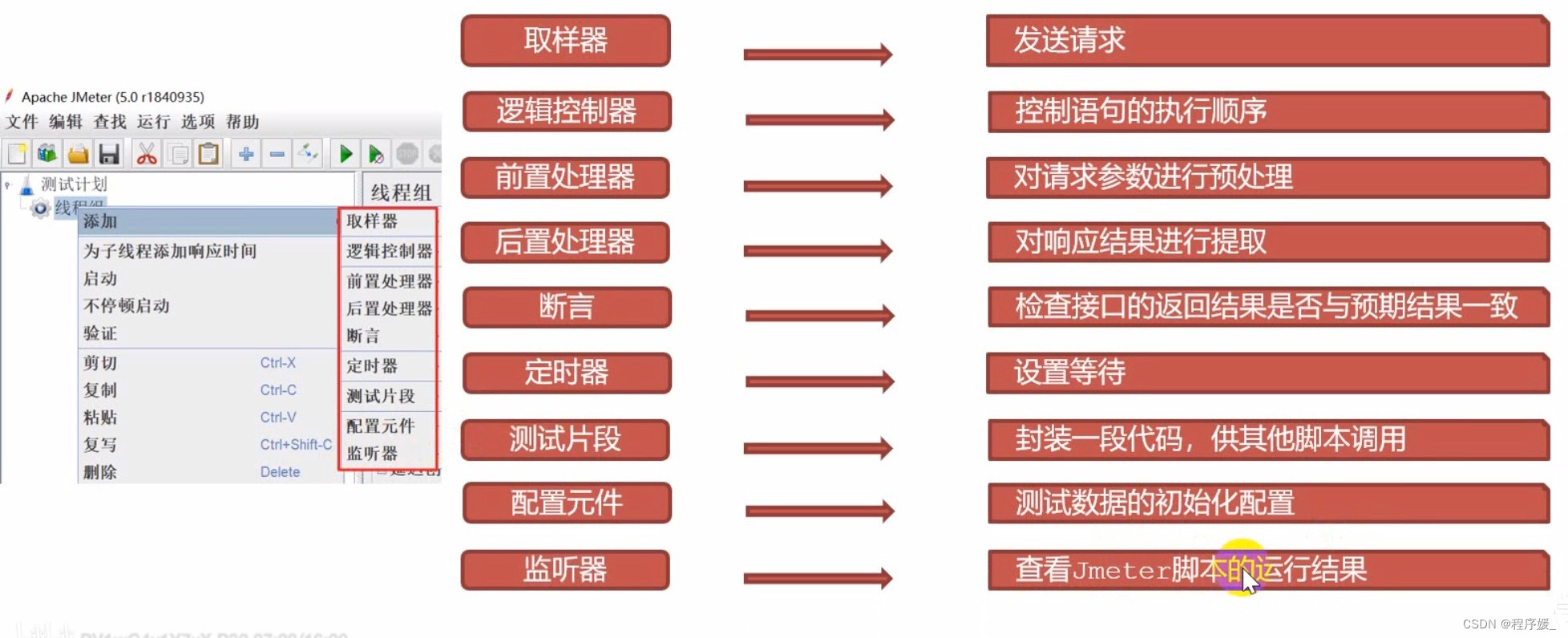
- 组件:
容器中
\color{red}{容器中}
容器中实现独立的某个功能(类似于
方法
\color{red}{方法}
方法)
- 元件的作用域和执行顺序
参考文章:JMeter元件作用域和执行顺序
JMeter基本组成
线程组
作用: 线程组就是控制Jmeter用于执行测试的一组用户
位置: 右键点击“ 测试计划” >> 添加 >> 线程(用户)>> 线程组
特点:
- 模拟多人操作
- 线程组可以添加多个,多个线程组可以并行或串行(默认并行,勾选“独立运行每个线程组”后按顺序依次串行)

- 取样器(请求)和逻辑控制器必须依赖线程组才能使用
- 线程组下可以添加其他元件下组件
参数:

线程组分类:
线程组:普通的、常用的线程组,可以看做一个虛拟用户组,线程组中的每一个线程都可以理解为一个虚拟用户。
setUp线程组:预测试操作,所有脚本之前执行
tearDown线程组:测试后操作,所有脚本之后执行
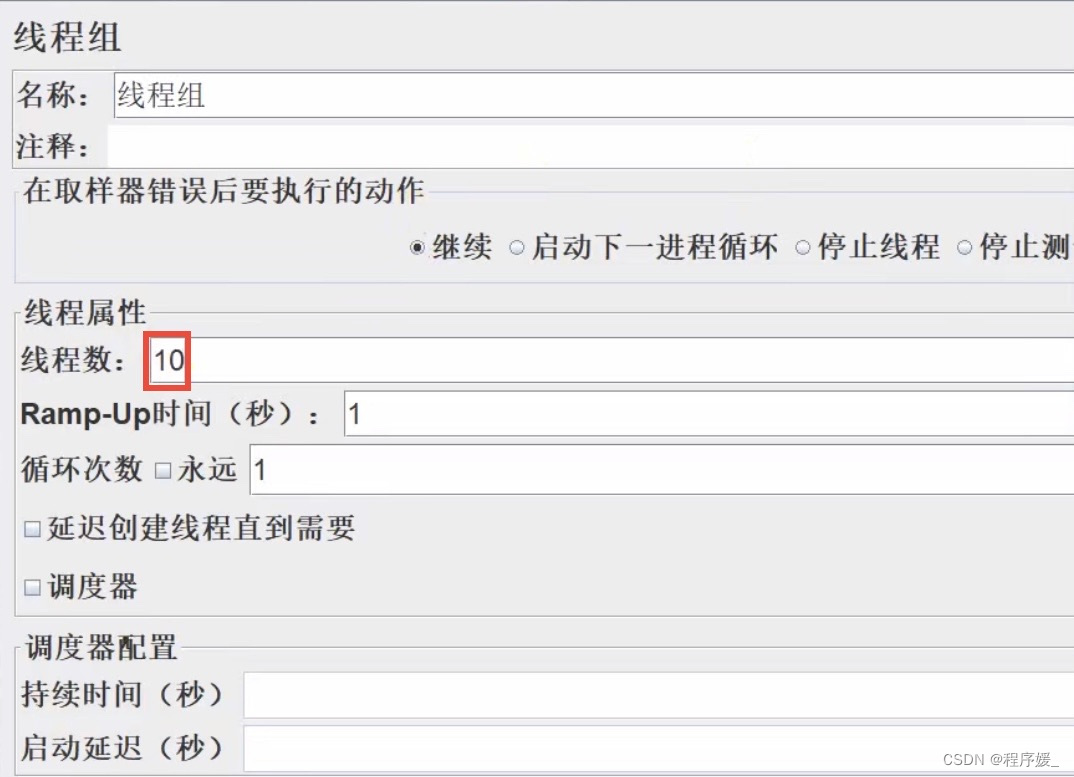
如下场景如何设置线程组?
- 模拟10个用户并行执行:
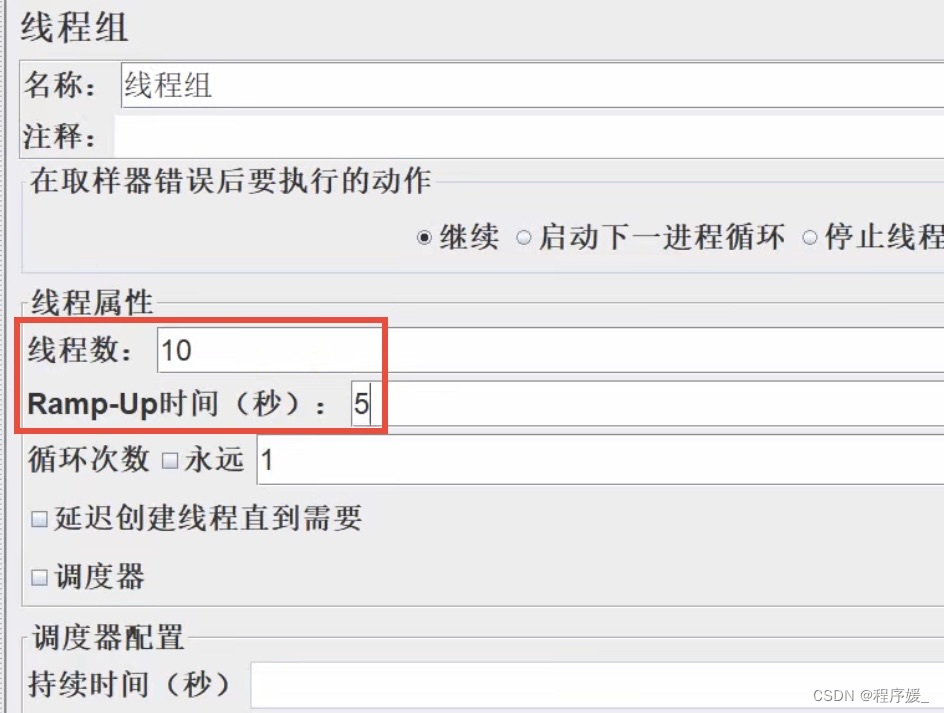
- 模拟10个用户5s内启动完成:
- 模拟2个用户各循环3次:
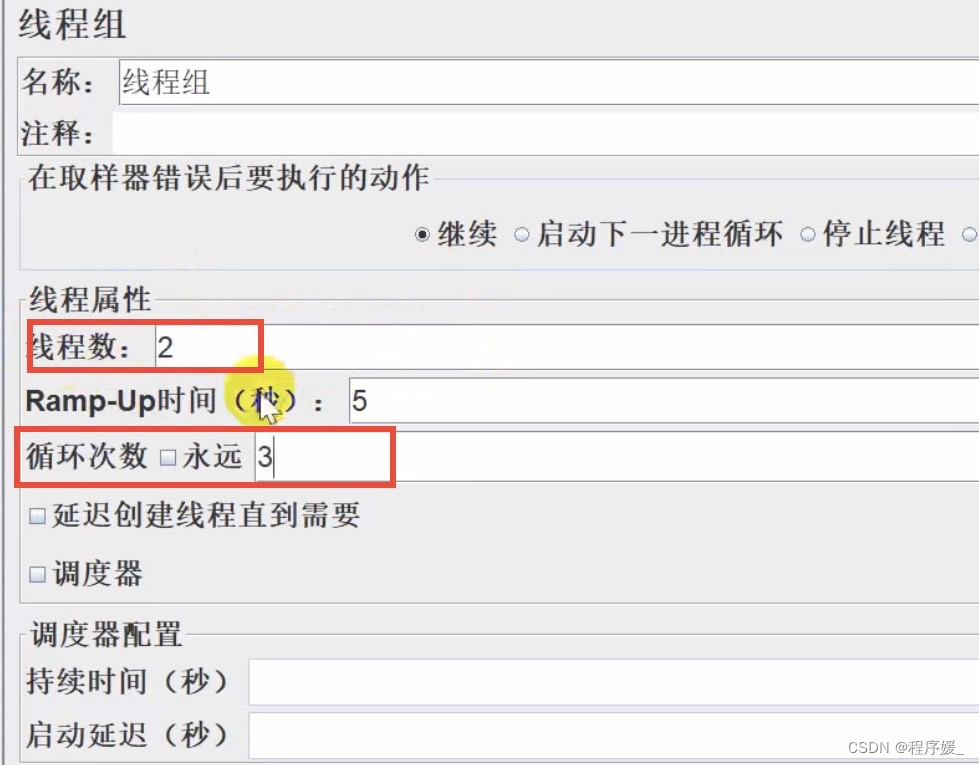
- 模拟2个用户运行15s:
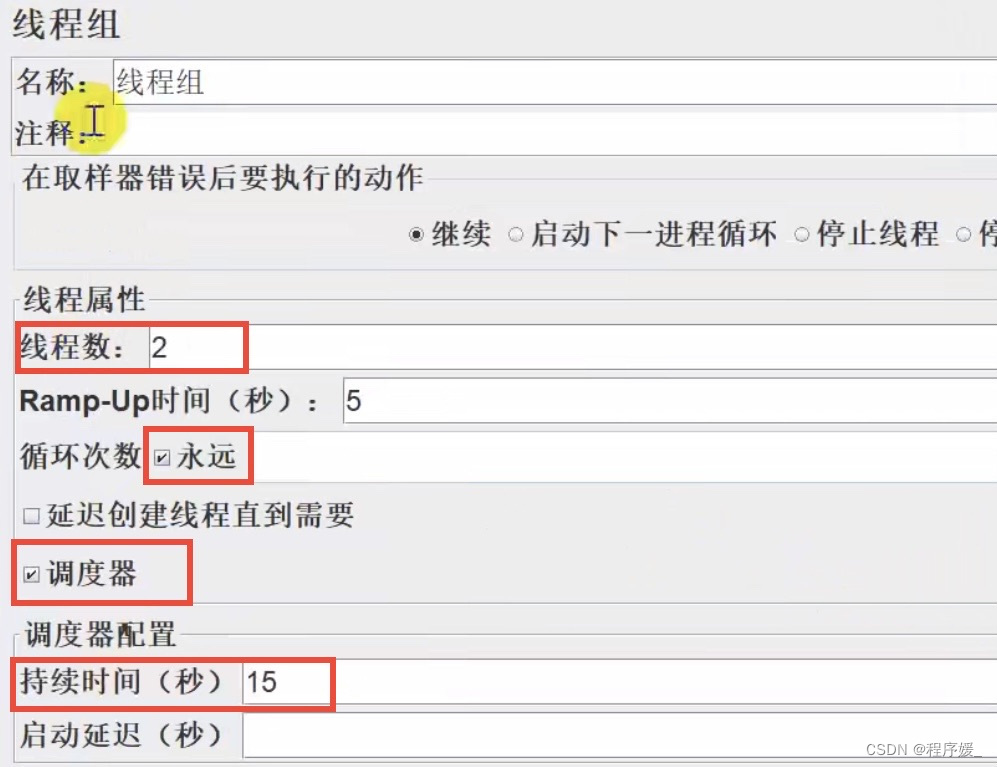
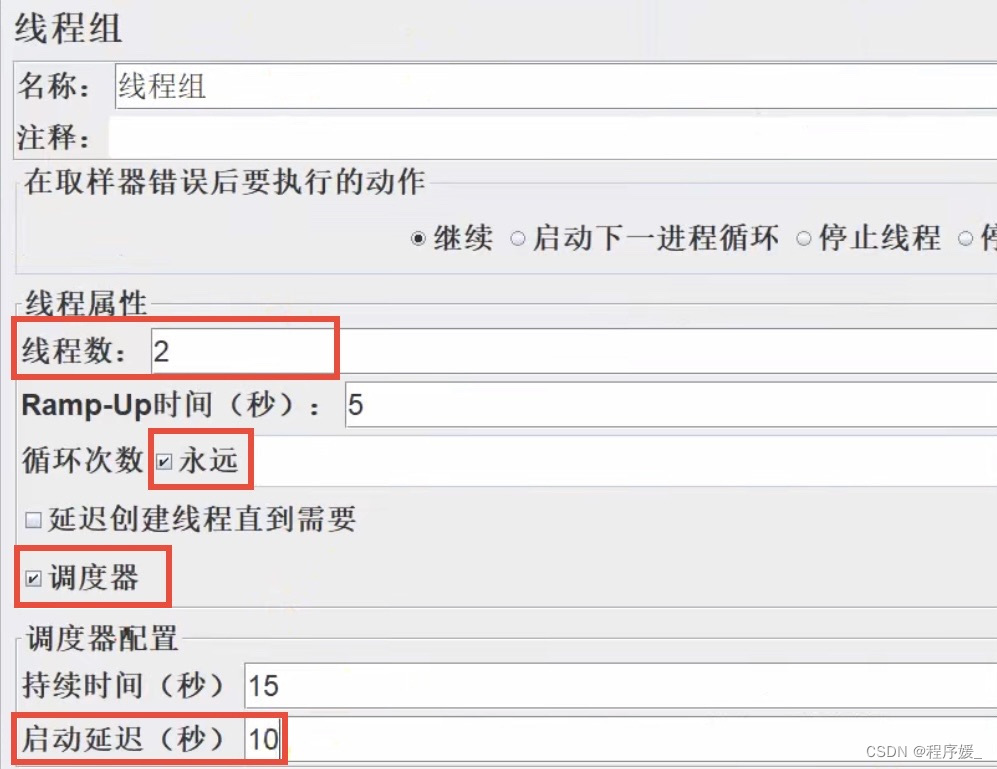
- 模拟2个用户等待10s后开始执行:
案例分析
使用1个线程组,添加HTTP请求(百度)
(1) 配置线程数为2,循环次数为3时,运行观察结果
(2)配置线程数为3,循环次数为2时,运行观察结果,对比不同
分析:
(1)线程数代表虚拟用户数,用户数越多,负载越大
(2)循环次数代表运行时间,次数适多,运行时间越长
HTTP请求
作用: 向服务器发送http及https请求
位置: 选中线程组>>右键>>添加>>取样器>>HTTP请求
参数:
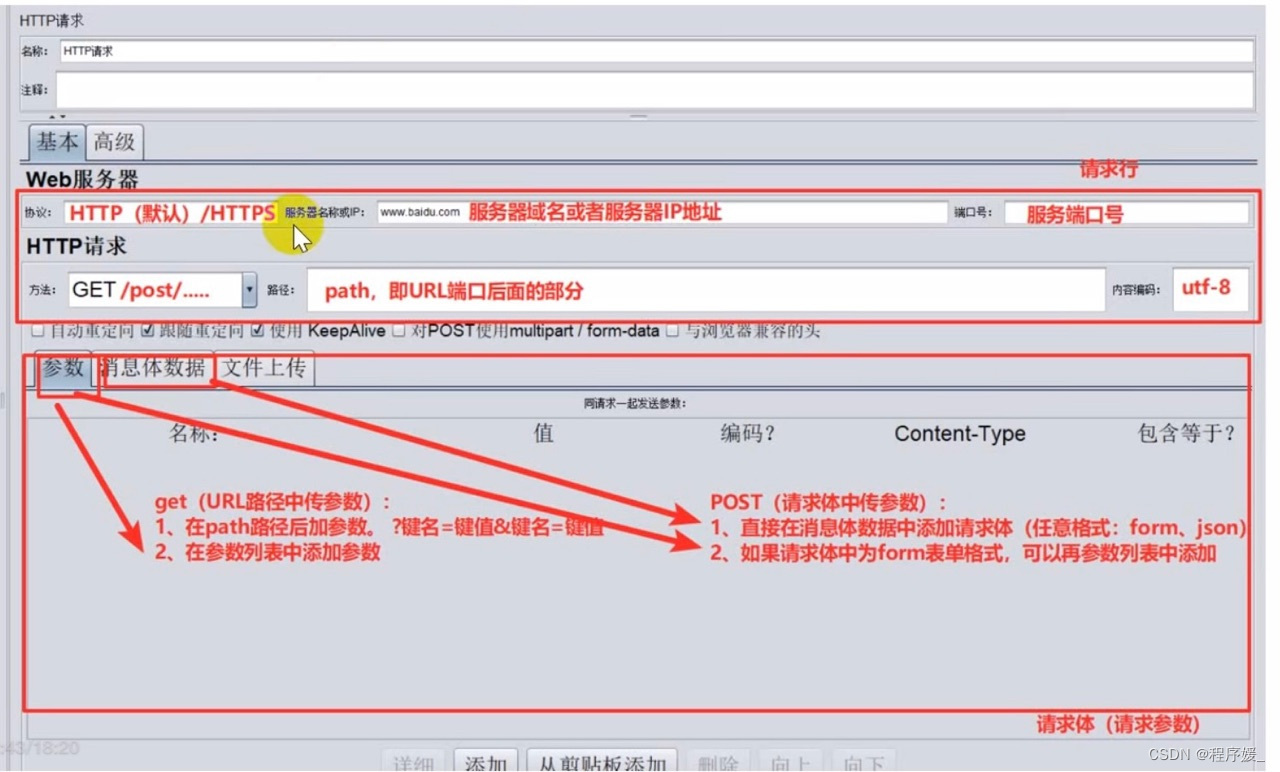
注意:协议默认为http;http默认端口为80,https默认端口为443
如何配置来发送HTTP请求?
- 发送GET请求(
请求参数在路径中
\color{red}{请求参数在路径中}
请求参数在路径中):
URL: 协议、服务器域名或IP、端口、方法(GET)、路径、编码格式
参数:
在路径后添加参数。格式:?键名=键值&键名=键值
在参数列表中添加参数。格式:名称(键名)、值(键值) - 发送POST请求(
请求参数在消息体数据中
\color{red}{请求参数在消息体数据中}
请求参数在消息体数据中):
URL: 协议、服务器域名或IP、端口、方法(POST)、路径、编码格式
参数:
在消息体数据中添加请求体 (form/json)
在参数列表中添加参数 (form)
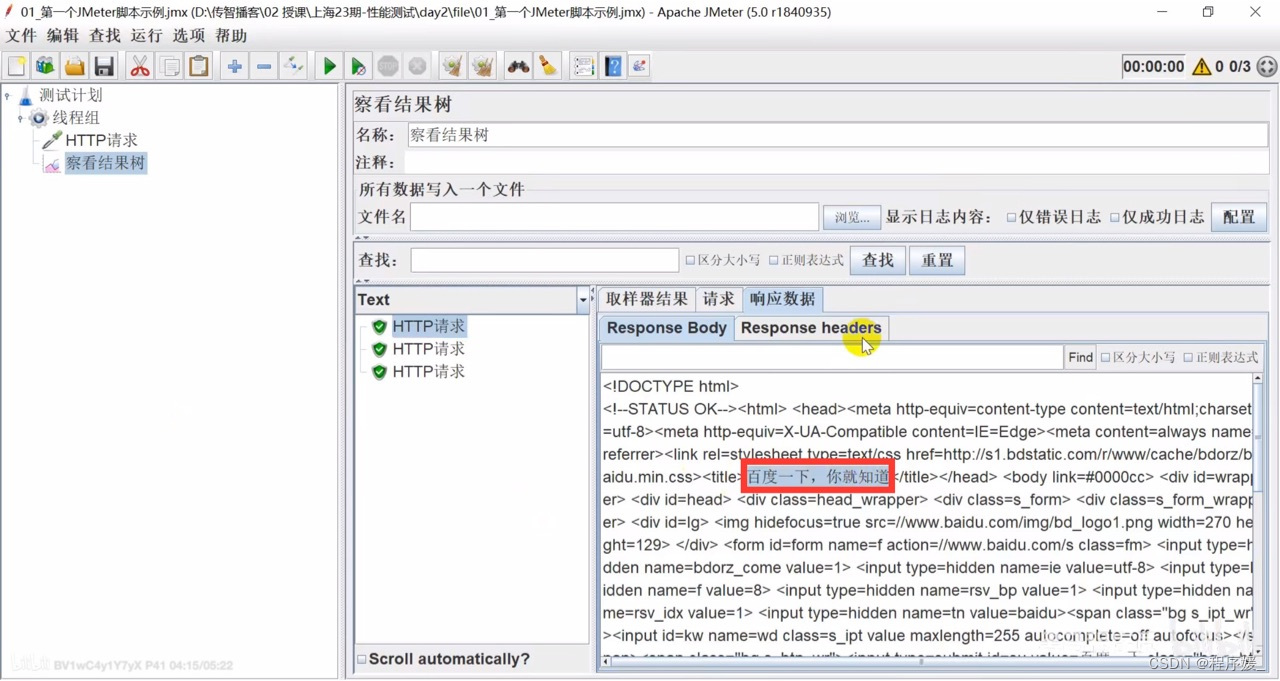
查看结果树
作用: 查看HTTP请求的请求和响应结果
位置: 选中测试计划/线程组>>右键>>添加>>监听器->>察看结果树
组成:
- 取样结果:查看响应信息头信息、响应状态码
- 请求:查看请求相关信息 (url、方法、参数)
- 响应:查看响应信息
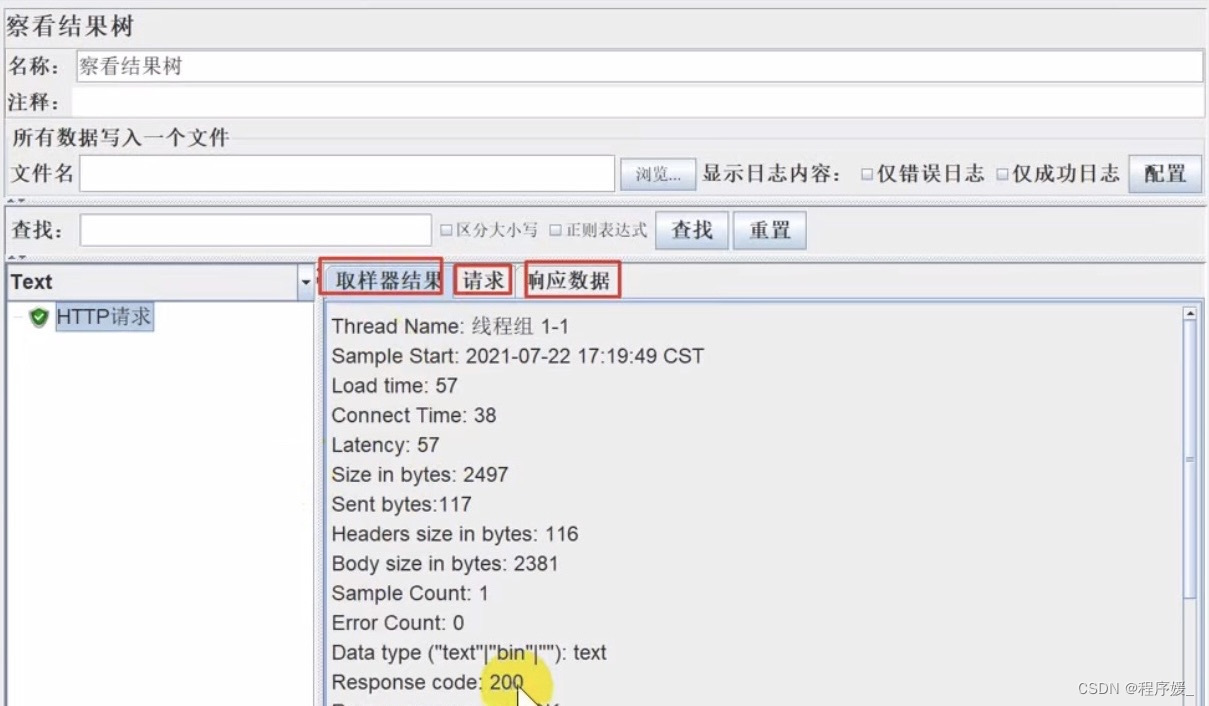
如何解决JMeter查看结果树的响应中的中文乱码?

解决方法:
- 找到JMeter安装目录下的bin目录
- 打开jmeter.properties文件,修改配置sampleresult. default.encoding=UTF-8
- 重启JMeter即可

JMeter进行HTTP接口测试的技术要点
参数化
为什么要使用参数化?
如果要访问某一请求10次,要求每次请求发送不同的参数值,该怎么做?
参数化测试: 把测试数据组织起来,用
不同的测试数据
\color{red}{不同的测试数据}
不同的测试数据调用
相同的测试方法
\color{red}{相同的测试方法}
相同的测试方法。
参数化的实现方式:
- 用户定义的变量——全局变量
- 用户参数——为每个用户分配不同的参数值
- CSV Data Set Config(CSV数据文件设置)——文件方式参数化
- 函数——随机数据
- 数据库
用户定义的变量
作用: 定义全局变量
局限性: 每次取值(无论是否相同的用户)都是固定值
位置: 测试计划 >> 线程组 >> 配置元件 >> 用户定义的变量
参数:

参数化步骤:
- 添加线程组
- 添加用户定义的变量。格式:变量名 一变量值
- 添加HTTP请求,引用定义的变量名。格式:${变量名}
- 添加查看结果树

用户参数
为什么使用用户参数?
性能测试时有多个用户同时请求,每个用户在登录请求时需要使用不同的用户名密码进行登录,该怎么做?
作用: 保证不同的用户针对同一组参数,可以取到不同的值
局限性: 同一个用户在多次循环时,取到相同的值
位置: 测试计划 >> 线程组 >> 前置处理器 >>用户参数
参数:

参数化步骤:
- 添加线程组,设置线程组数为n(表示模拟的用户数)
- 添加用户数:第一列添加多个变量名;后续每一列为一组用户的数据
- 添加HTTP请求,引用定义的变量名。格式:${变量名}
- 添加查看结果树

CSV数据文件设置
为什么要使用CSV数据文件参数化?
性能测试时有多个用户登录,登录后循环添加商品,每次添加时商品的参数不能相同,该怎么做?
作用: 保证不同的用户或者同一用户多次循环时,都可以取到不同的值
局限性: 需要手动进行测试数据的设置
位置: 测试计划>>线程组> 配置元件>> CSV 数据文件设置
参数:

参数化步骤:
- 定义CSV数据文件
- 添加线程组
- 添加CSV数据文件设置
- 添加HTTP请求,引用定义的变量名。格式:${变量名}
- 添加查看结果树

函数(__counter)
为什么要使用函数参数化?
性能测试时,如果模拟1000个用户,每个用户循环执行10万次添加商品操作,请求参数要求不同,该怎么做?
作用: 计数函数,一般做执行次数统计使用。自动生成不重复的数据,让每个用户每次循环都能取到不同的数据,且不需要提前定义。
局限性: 输入数据有特定的业务要求时无法使用(如:登录时的用户名密码)
位置: 在菜单中选择>>选项>>函数助手对话框
设置:
- TRUE,每个用户有自己的计数器;EAISE,使用全局计数器
- Name of variable in which to store the result (optional):用于存储结果的变量名(可选)
使用: 生成-复制
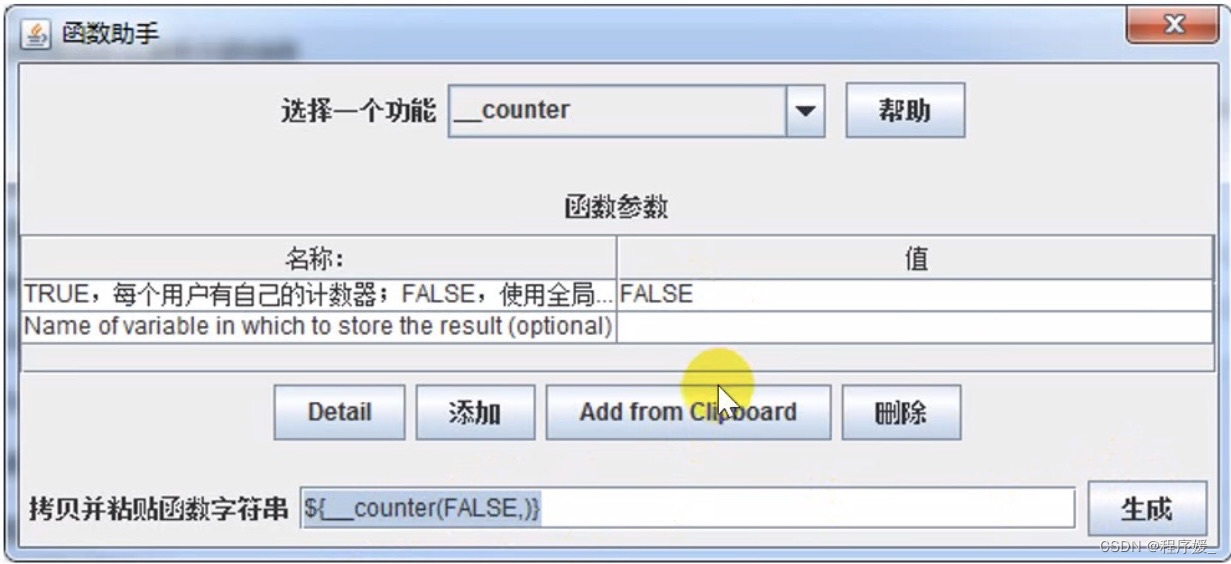
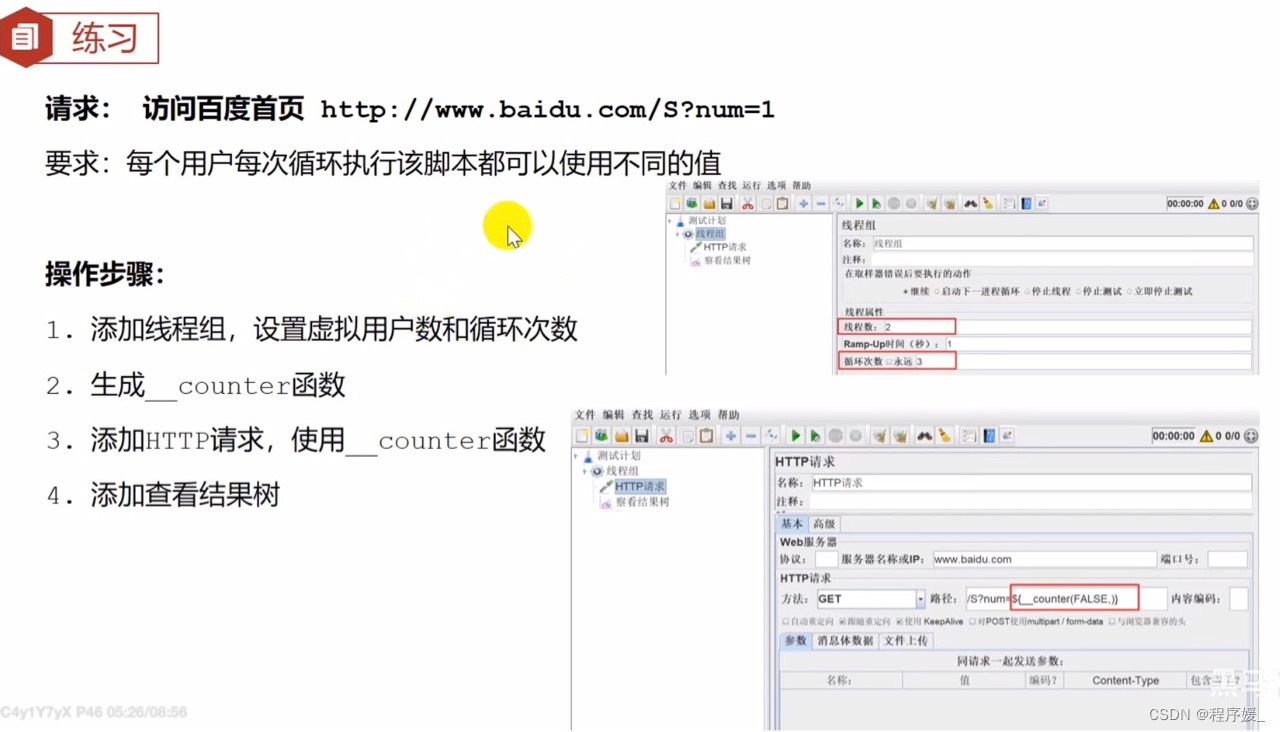
参数化步骤:
- 添加线程组,设置虚拟用户数和循环次数
- 生成__counter函数
- 添加HTTP请求,使用__counter函数。格式:${__counter(FALSE,)}
- 添加查看结果树
案例分析:查看结果树中多个HTTP请求的原因分析
问题描述: 当发送www.jd.com的http请求时,查看结果树看到的发送消息和HTTP取样器中配置的不完全一样?

原因分析: 重定向!


注意:
- 查看结果数中最外层HTTP请求的请求信息和响应信息,应该与子节点中最后一个HTTP请求的请求消息和响应消息一致;
- 配置的HTTP请求,应该与子节点中第一个HTTP请求的请求信息一致;
断言
为什么要使用Jeter断言?
手工执行用例时可以肉眼观察结果;使用工具代替手工执行用例时,如何判断用例是否通过?
断言: 让程序
自动判断
\color{red}{自动判断}
自动判断预期结果和实际结果
是否一致
\color{red}{是否一致}
是否一致。
提示:
- JMeter会 自动判断响应状态码 \color{red}{自动判断响应状态码} 自动判断响应状态码(如果状态码为4xx/5xx,判定为失败)
- 但是请求成功了,并不代表结果一定正确,因此需要检测机制提高测试准确性。
JMeter中常用断言:
- 响应断言
- JSON断言
- 持续时间断言 (Duration Assertion)
响应断言
作用: 对HTTP请求的
任意格式
\color{red}{任意格式}
任意格式的响应结果进行断言
位置: 测试计划 >> 线程组 >> HTTP请求 >>(右键添加)断言 >> 响应断言
参数:


步骤:
- 添加线程组
- 添加HTTP请求
- 添加响应断言:
测试字段:要检查的项(实际结果)
模式匹配规则:比较方式
测试模式:预期结果 - 添加查看结果树

JSON断言
作用: 对HTTP请求的
J
S
O
N
格式
\color{red}{JSON格式}
JSON格式的响应结果进行断言
位置: 测试计划 >> 线程组 >> HTTP请求>>(右键添加)断言>> JSON断言
参数:

步骤:
- 添加线程组
- 添加HTTP请求
- 添加JSON断言:
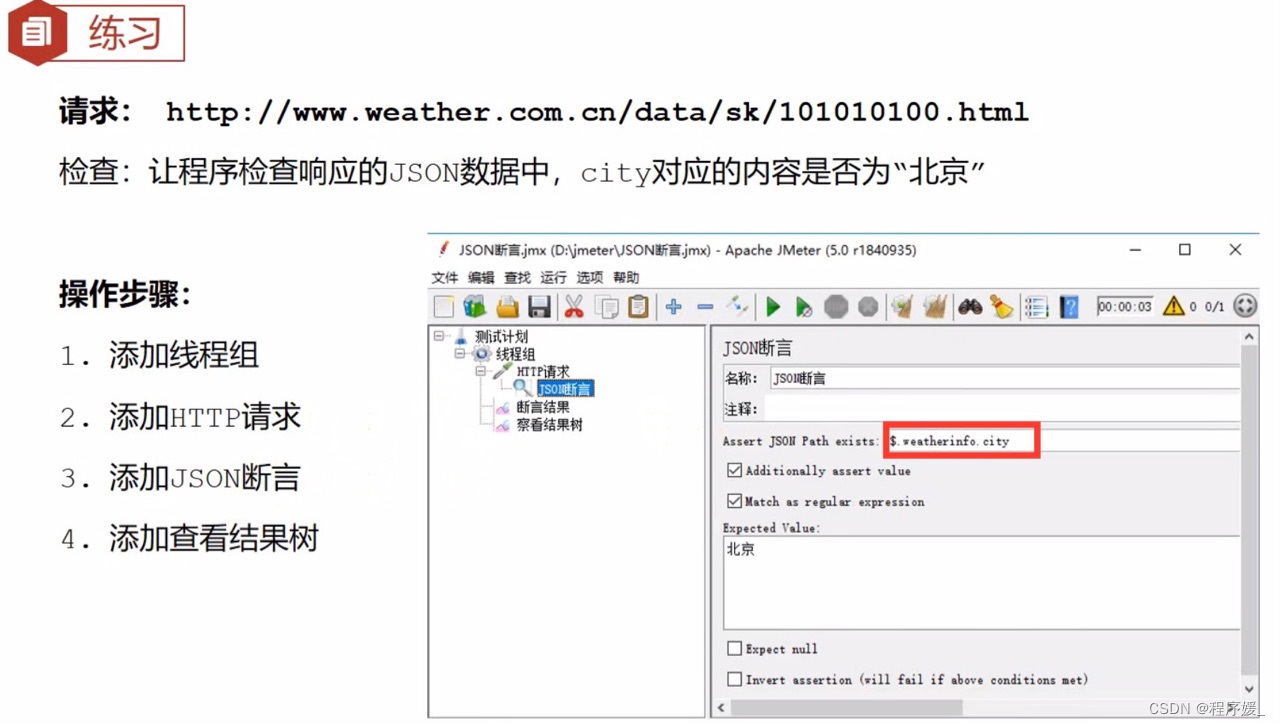
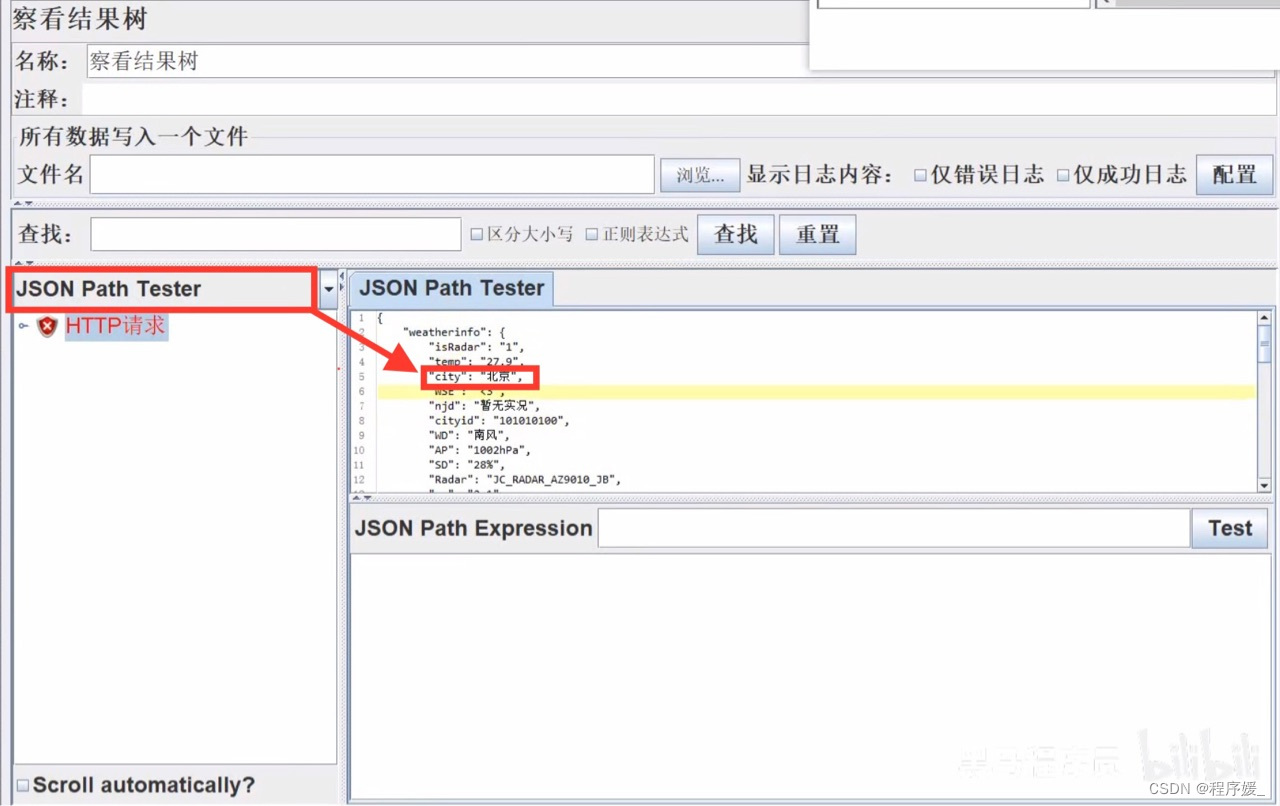
填写Assert JSON Path exists ( 实际结果 − j s o n 路径 ) \color{red}{(实际结果-json路径)} (实际结果−json路径)
勾选Additionally assert value
填写Expected Value (期望结果) \color{red}{(期望结果)} (期望结果) - 添加查看结果树
持续时间断言
作用: 检查HTTP请求的
响应时间
\color{red}{响应时间}
响应时间是否超出要求范围
位置: 测试计划 >> 线程组>> HTTP请求 >>(右键添加)断言 >> 断言持续时间
参数: 持续时间(毫秒):HTTP请求允许的
最大响应时间(单位:毫秒)
\color{red}{最大响应时间 (单位:毫秒)}
最大响应时间(单位:毫秒)。超过则认为失败。

步骤:
- 添加线程组
- 添加HTTP请求
- 添加断言持续时间
填写持续时间(允许的最大响应时间,单位:ms) - 添加查看结果树

关联
关联: 当请求之间有
依赖关系
\color{red}{依赖关系}
依赖关系,比如一个请求的入参是另一个请求返回的数据,这时候就需要用到关联处理。
JMeter中常用的关联方法:
同一个线程组内
\color{red}{同一个线程组内}
同一个线程组内,多个请求之间的关联:
- 如果响应数据为 J S O N 格式 \color{red}{JSON格式} JSON格式,优先使用 J S O N 提取器 \color{red}{JSON提取器} JSON提取器进行关联
- 如果响应数据为 H T M L 格式 \color{red}{HTML格式} HTML格式,优先使用 X P a t h 提取器 \color{red}{XPath提取器} XPath提取器进行关联
- 如果JSON提取器和XPath提取器都无法实现关联,使用 正则表达式提取器 \color{red}{正则表达式提取器} 正则表达式提取器进行关联,针对 任意格式 \color{red}{任意格式} 任意格式的响应数据。
不同线程组之间 \color{red}{不同线程组之间} 不同线程组之间,多个请求之间的关联:
- JSON提取器 + J M e t e r 属性 \color{red}{JMeter属性} JMeter属性
- XPath提取器 + J M e t e r 属性 \color{red}{JMeter属性} JMeter属性
- 正则表达式提取器 + J M e t e r 属性 \color{red}{JMeter属性} JMeter属性
正则表达式关联
正则表达式
正则表达式就是一个公式,或者说一套规则,使用这套规则可以从任意字符串中提取出想要的数据内容。
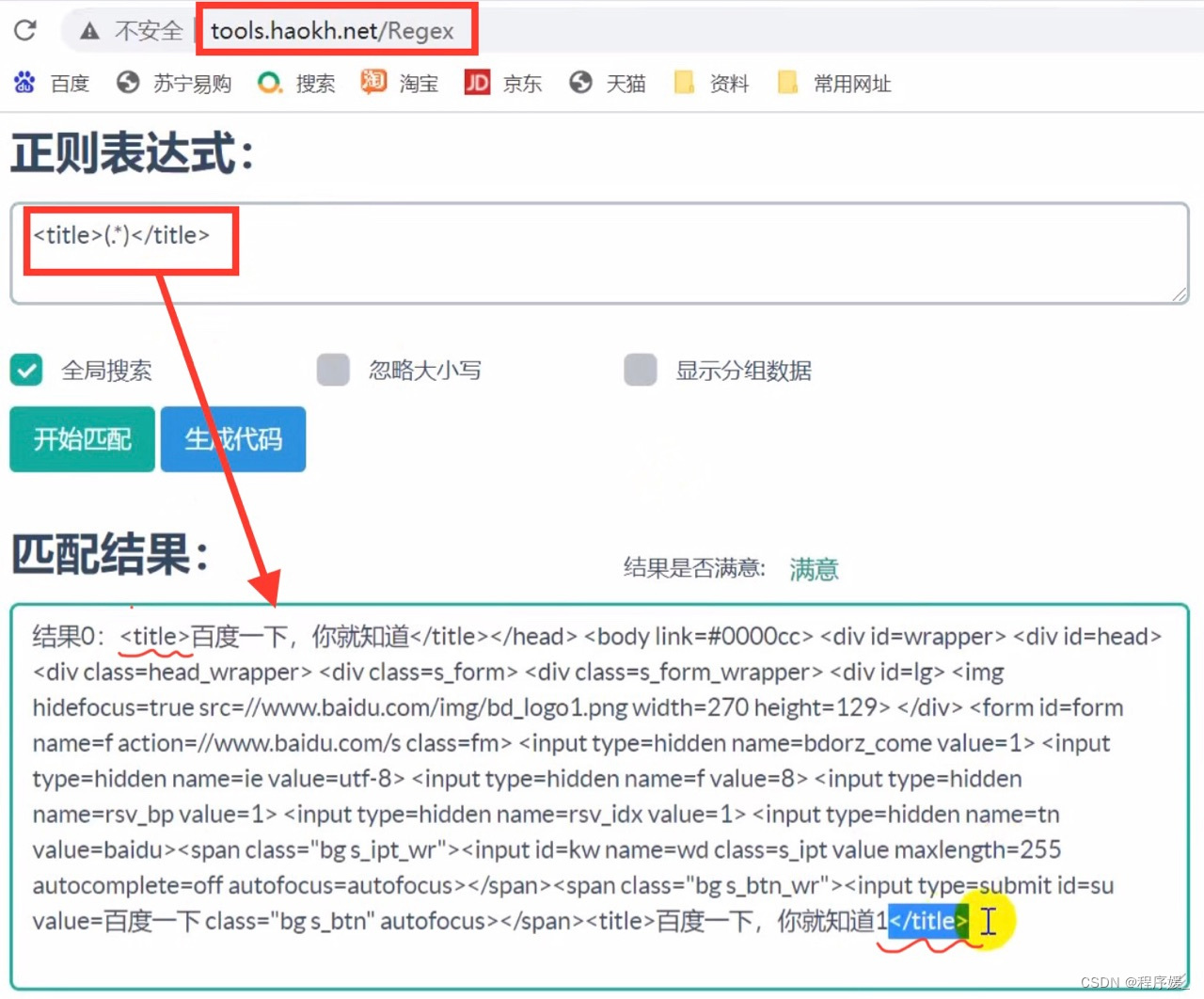
<title>百度一下,你就知道</title><title>百度一下,你就知道</title>
<title>.*?</title>
左边界(.*?)右边界:可以提取出想要获取的数据内容
| 符号 | 定义 |
|---|---|
| . | 通配符,可以代表任意字符(除换行回车) |
| * | 代表前面的字符出现0次或者多次 |
| ? | 代表非贪婪匹配,找到左边界后,往右查找匹配右边界,只要有匹配的右边界就停止继续查找;再次查找左边界和右边界 |
案例:


正则表达式提取器
作用: 针对
任意格式
\color{red}{任意格式}
任意格式的响应数据进行提取
位置: 测试计划 >> 线程组 >> HTTP请求 >>(右键添加)后置处理器 >> 正则表达式提取器
参数:
步骤:
- 添加线程组
- 添加HITP请求-传智播客
- 添加正则表达式提取器
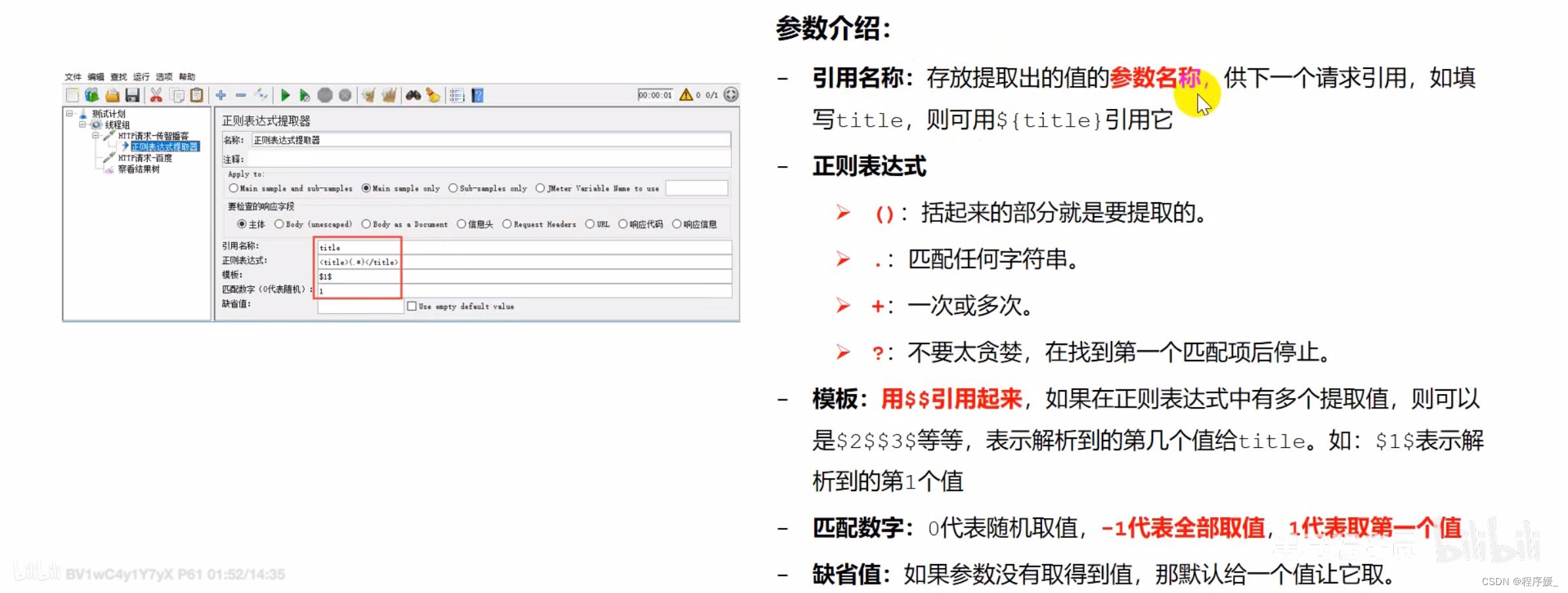
引用名称:存放提取出的值的 参数名称 \color{red}{参数名称} 参数名称,如填写tit1e
正则表达式: 左边界 ( . ∗ ? ) 右边界 \color{red}{左边界(.*?)右边界} 左边界(.∗?)右边界
模板:用$n$ 引用起来,表示解析出第n个()里的值
匹配数字: 1 表示第 1 个值, − 1 表示所有取值, 0 表示随机取值 \color{red}{1表示第1个值,-1表示所有取值,0表示随机取值} 1表示第1个值,−1表示所有取值,0表示随机取值 - 添加红TP请求-百度
引用正则表达式中的引用名称。如:用${title}引用它 - 添加查看结果树
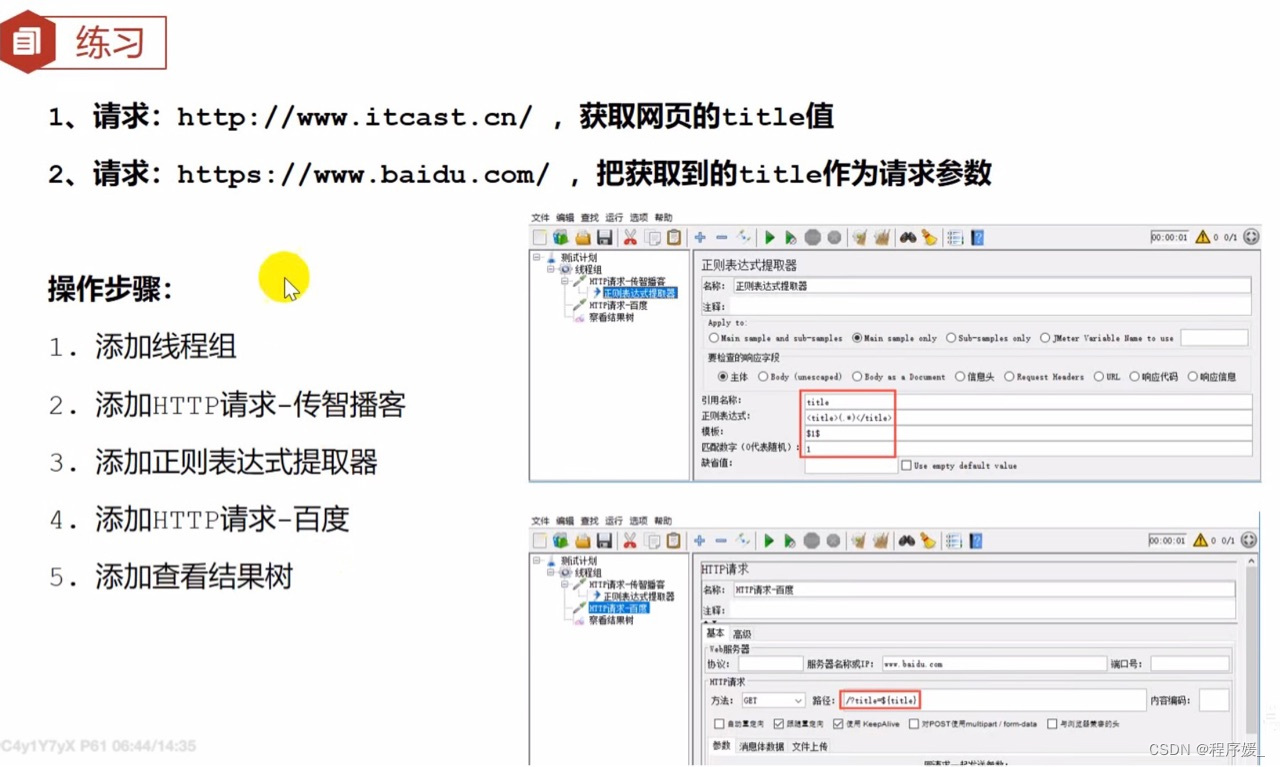
案例:
- 获取传智播客(http://www.itcast.cn/)首页的地址,把第5个校区地址作为参数传递(span为地址的校区),响应中的地址格式显示如下:
<p><Span>地址</Span>上海市浦东新区航头镇航都路18号万香创新港</p>
方法一:
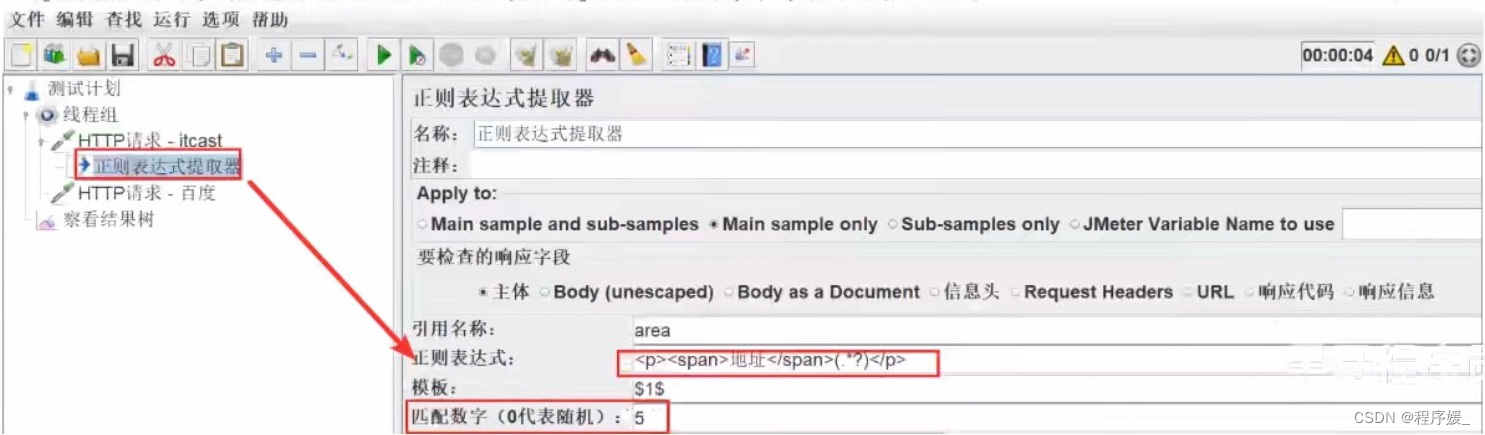
方法二:

- 引用:以列表索引的方式来引用。格式:${变量名_索引},索引从1开始。
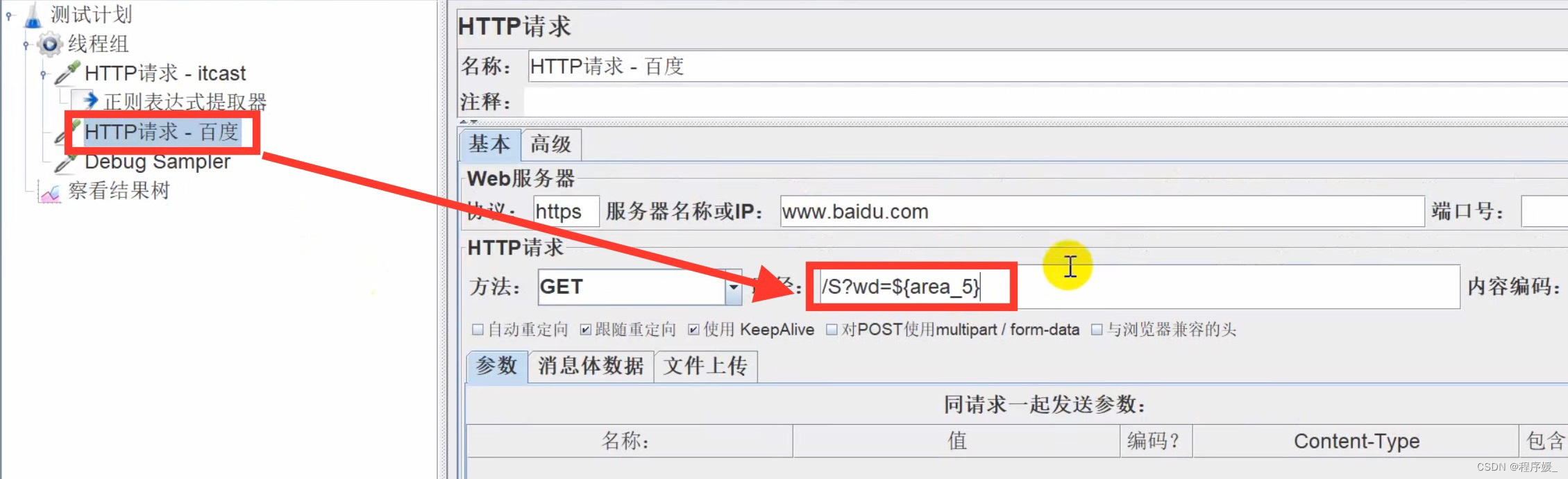
- 获取传智播客首页的地址,把第5个校区地址作为参数传递(span为地址/后面带一、二、三),响应中的地址格式显示如下:
<p><Span>地址一</span>昌平区建材城西路金燕龙办公楼一层</p>
<p><Span>地址</span>上海市浦东新区航头镇航都路18号万香创新港</p>

拓展——Debug Sampler:
在调试过程中可添加Debug Sampler查看响应信息。
位置:测试计划 >> 线程组 >>(右键添加)取样器 >> Debug Sampler

XPath提取器
作用: 针对
H
T
M
L
格式
\color{red}{HTML格式}
HTML格式的响应结果数据进行提取
位置: 测试计划 >> 线程组>> HTTP请求 >>(右键添加) 后置处理器 >> XPath提取器
参数:

步骤:
- 添加线程组
- 添加HTTP请求-传智播客
- 添加XPath提取器
勾选 U s e T i d y \color{red}{勾选Use Tidy} 勾选UseTidy (tolerant parser)
引用名称:存放提取出的值的KaTeX parse error: Undefined control sequence: \colorred at position 1: \̲c̲o̲l̲o̲r̲r̲e̲d̲}{参数名称}。如:填写tit1e
XPath Query:用于提取值的 X P a t h 表达式 \color{red}{XPath表达式} XPath表达式
匹配数字:0表示随机,-1表示提取所有结果,1表示第一个值 - 添加HTTP请求-百度
引用正则表达式中的引用名称。如:用${title}引用它 - 添加查看结果树
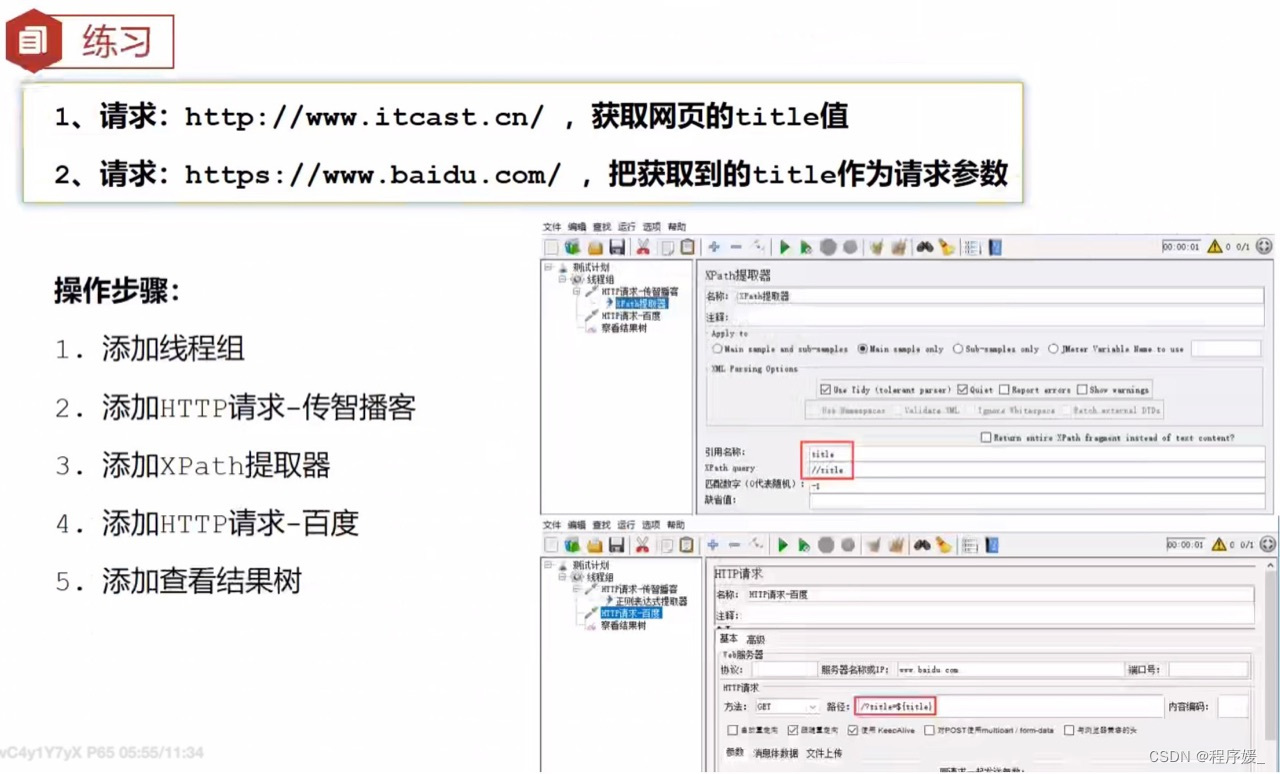
JSON提取器
作用: 针对
J
S
O
N
格式
\color{red}{JSON格式}
JSON格式的响应结果数据进行提取
位置: 测试计划 >> 线程组 >> HTTP请求 >>(右键添加) 后置处理器 >> JSON提取器
参数:

步骤:
- 添加线程组
- 添加HTTP请求-天气
- 添加JSON提取器
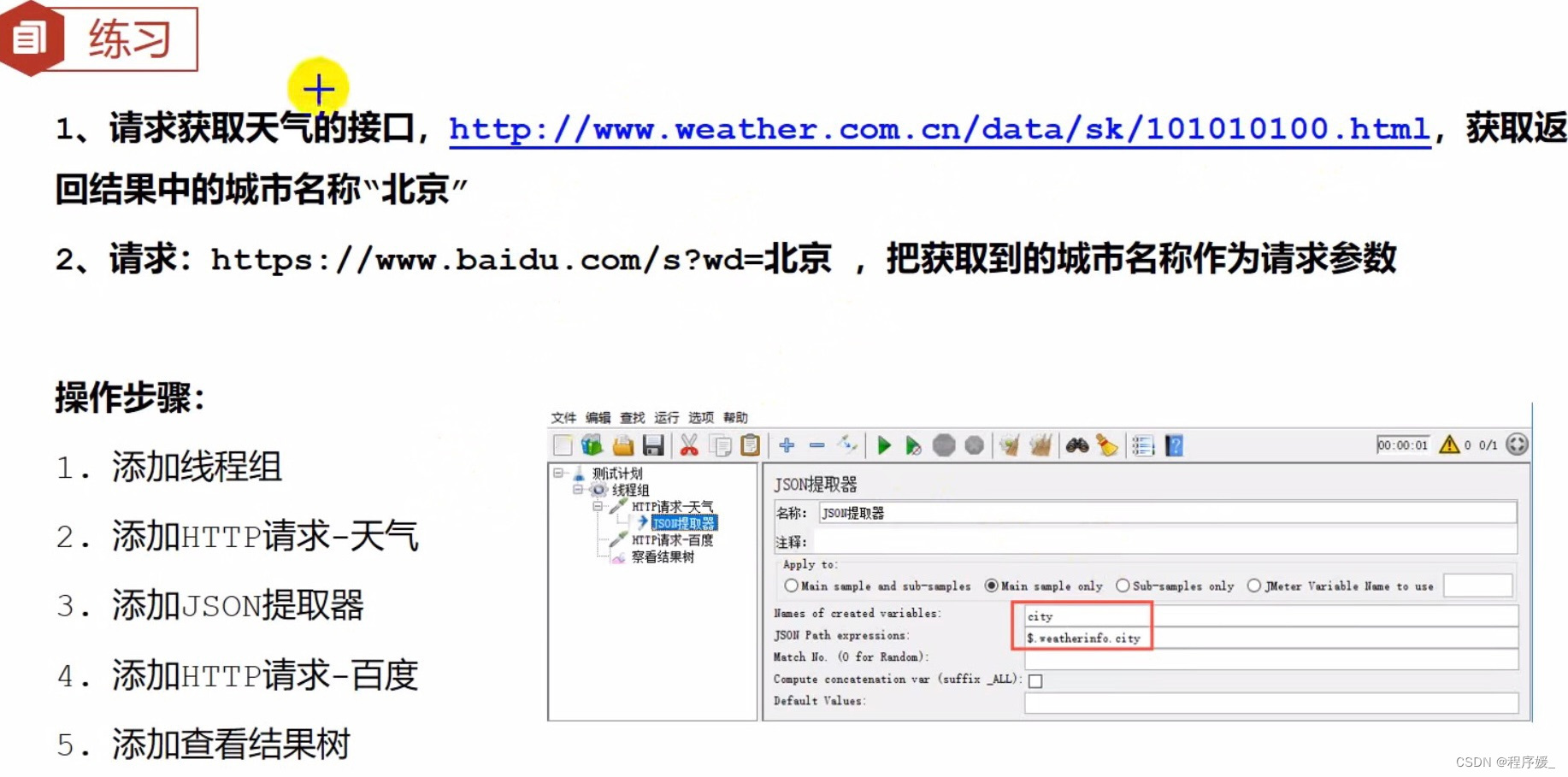
Names of created variables:存放提取出的值的 参数名称 \color{red}{参数名称} 参数名称。如:city
JSON Path Expressions: 用于提取值的 J S O N 路径表达式 \color{red}{JSON路径表达式} JSON路径表达式
Match No: 0 表示随机, − 1 表示提取所有结果, 1 表示第一个值 \color{red}{0表示随机,-1表示提取所有结果,1表示第一个值} 0表示随机,−1表示提取所有结果,1表示第一个值 - 添加HTTP请求-百度
引用正则表达式中的引用名称。如:用${city}引用它 - 添加查看结果树
跨线程组关联——JMeter属性
为什么要使用JMeter属性?
当有关联关系的两个请求在同一个线程组中时,可以使用三种提取器的变量来
实现数据传递。
当有关联关系的两个请求在不同线程组中时,如何进行数据传递呢?——JMeter属性
JMeter属性的配置函数:

JMeter属性的函数执行:

步骤:
- 添加线程组1
- 添加HTP请求-天气
- 添加JSON提取器
- 添加Beanshell取样器(将JSON提取器提取的值保存为JMeter属性)
保存JMeter属性:${__setProperty(pro_city, ${city},} - 添加线程组2
- 添加HTTP请求-百度(读取JMeter属性)
读取JMeter属性: ${__property(pro_city,)} - 添加查看结果树

直连数据库
直连数据库的使用场景

直连数据库的关键配置
-
添加MySQL驱动jar包
方式一(临时性):在测试计划面板点击“浏览…”按钮,将你的JDBC驱动添加进来。
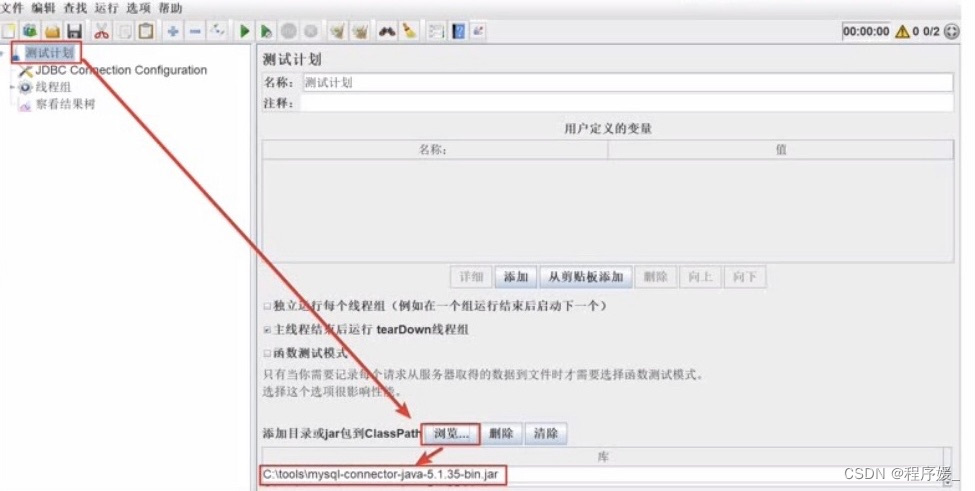
方式二(永久性):将MySQL驱动jar包放入到lib/ext目录下,重启JMeter。 -
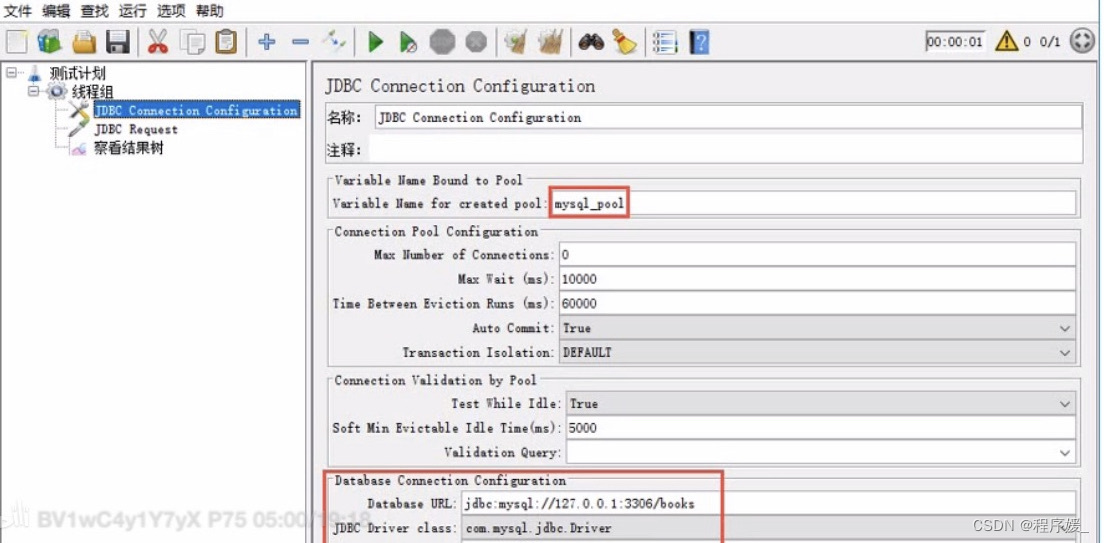
配置数据库连接信息:测试计划 >> 线程组 >>(右键添加)配置元件 >> JDBC Connection Configuration
参数介绍:
Variable Name: MySQL数据库连接池名称(JDBC请求时要引用)
Database URL: jdbc:MySQL://local host:3306/tpshop2.0(组成:协议+数据库IP+数据库端口+连接的数据库名称)
JDBC DRIVER class: com.mysql.jdbc.Driver(MySQL驱动包位置固定格式,下拉框选择)
Username: 连接数据库用户名
Password: MySQL数据库密码 -
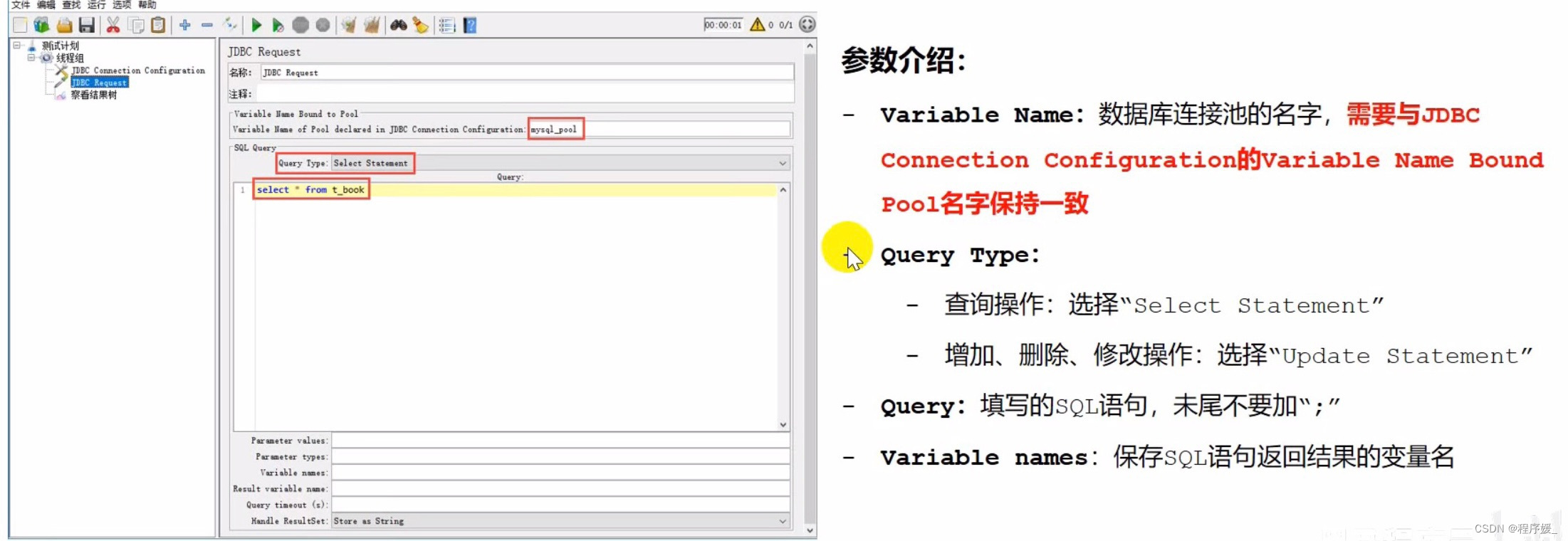
添加JDBC请求:测试计划 >> 线程组 >> 取样器 >> JDBC Request

逻辑控制器
逻辑控制器:可以按照设定的逻辑控制取样器的执行顺序
JMeter中常用的逻辑控制器:
- 如果(If)控制器
- 循环控制器
- ForEach控制器
IF控制器
作用: If控制器用来控制它下面的测试元素是否运行
位置: 测试计划 >> 线程组 >>(右键添加)逻辑控制器 >> 如果(If)控制器
参数介绍:



循环控制器
作用: 通过设置循环次数,来实现循环发送请求
位置: 测试计划 >> 线程组 >>(右键添加)逻辑控制器 >> 循环控制器
参数介绍:
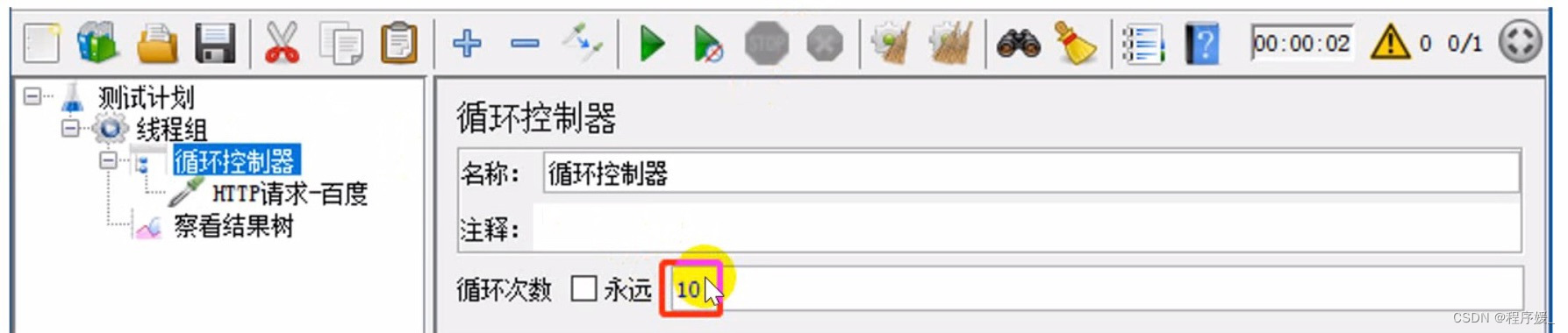

思考:线程组属性可以控制循环次数,那么循环控制器有什么用?
- 不同点:线程组的循环次数对线程组下的所有HTTP请求有效,循环控制器的循环次数对子节点下的HTTP请求有效。
- 关联:循环控制器次数为M,线程组循环次数为N,
循环控制器下的请求运行:M*N次
线程组下,非循环控制器下的请求运行:N次
ForEach控制器
作用: 一般和用户自定义变量或者正则表达式提取器一起使用,读取返回结果中一系列相关的变量。该控制器下的取样器都会被执行一次或多次,每次读取不同的变量值。
位置:测试计划 >> 线程组 >>(右键添加)逻辑控制器 >> ForEach控制器
参数:




修改上图步骤
录制脚本
为什么要录制脚本?
有API文档时,可以根据API文档的定义来编写HTTP接口测试脚本。那如果没有API文档时,该如何来编写HTTP接口测试脚本呢?
什么是JMeter录制脚本?
Jeter录制脚本:在
没有接口文档的旧项目
\color{red}{没有接口文档的旧项目}
没有接口文档的旧项目当中,快速录制web页面产生的http接口请求,
帮助编写接口测试脚本
\color{red}{帮助编写接口测试脚本}
帮助编写接口测试脚本。
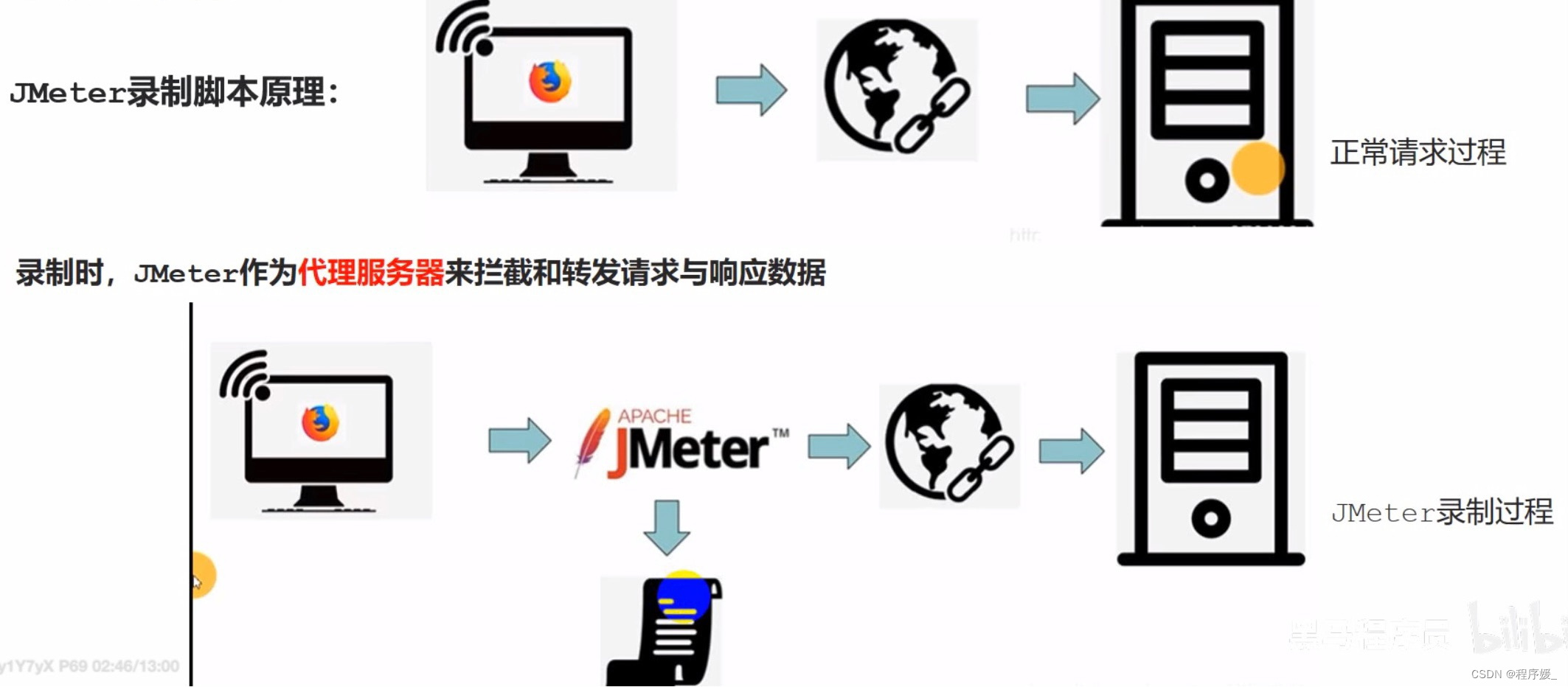
录制脚本的操作步骤:
- 添加HTTP代理服务器,并进行配置:
加HTTP代理服务器:测试计划(右键)>> 非测试元件 >> HTTP代理服务器
配置代理服务器的参数:

- 开启windows操作系统的浏览器代理


- 启动代理服务器,开始录制。
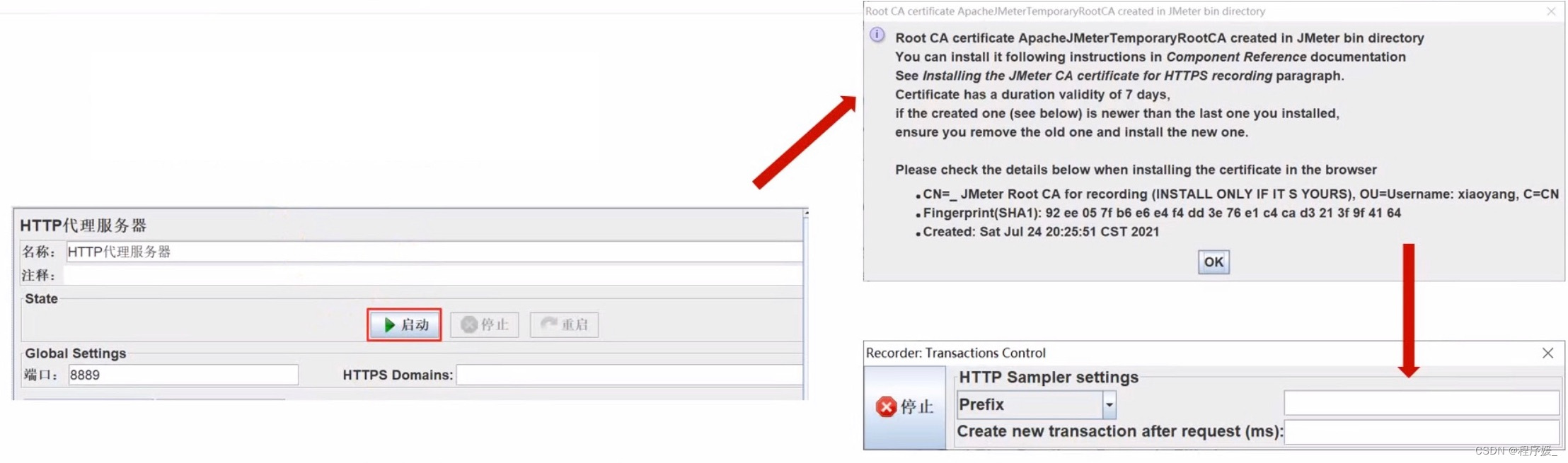
- 在浏览器页面中进行操作,成功后,就能在JMeter当中看到抓取到的接口请求了。

JMeter进行性能测试的技术要点
定时器
为什么要使用同步定时器?
如何模拟1w人同时使用电商网站?—— 相对并发
如何模拟1w人同时进行电商网站的抢购活动/秒杀活动?如何模拟1000人同时抢红包?——绝对并发
同步定时器
**同步定时器:**阻塞线程(累积一定的请求),当在
规定的时间内
\color{red}{规定的时间内}
规定的时间内达到
一定的线程数量
\color{red}{一定的线程数量}
一定的线程数量,这些线程会在同一个时间点
一起释放
\color{red}{一起释放}
一起释放,瞬间产生很大的压力。
提示: 在JMeter中叫做
同步定时器
\color{red}{同步定时器}
同步定时器,在Loadrunner中又叫
集合点
\color{red}{集合点}
集合点
使用场景: 测试抢购、秒杀、抢红包等高并发的场景
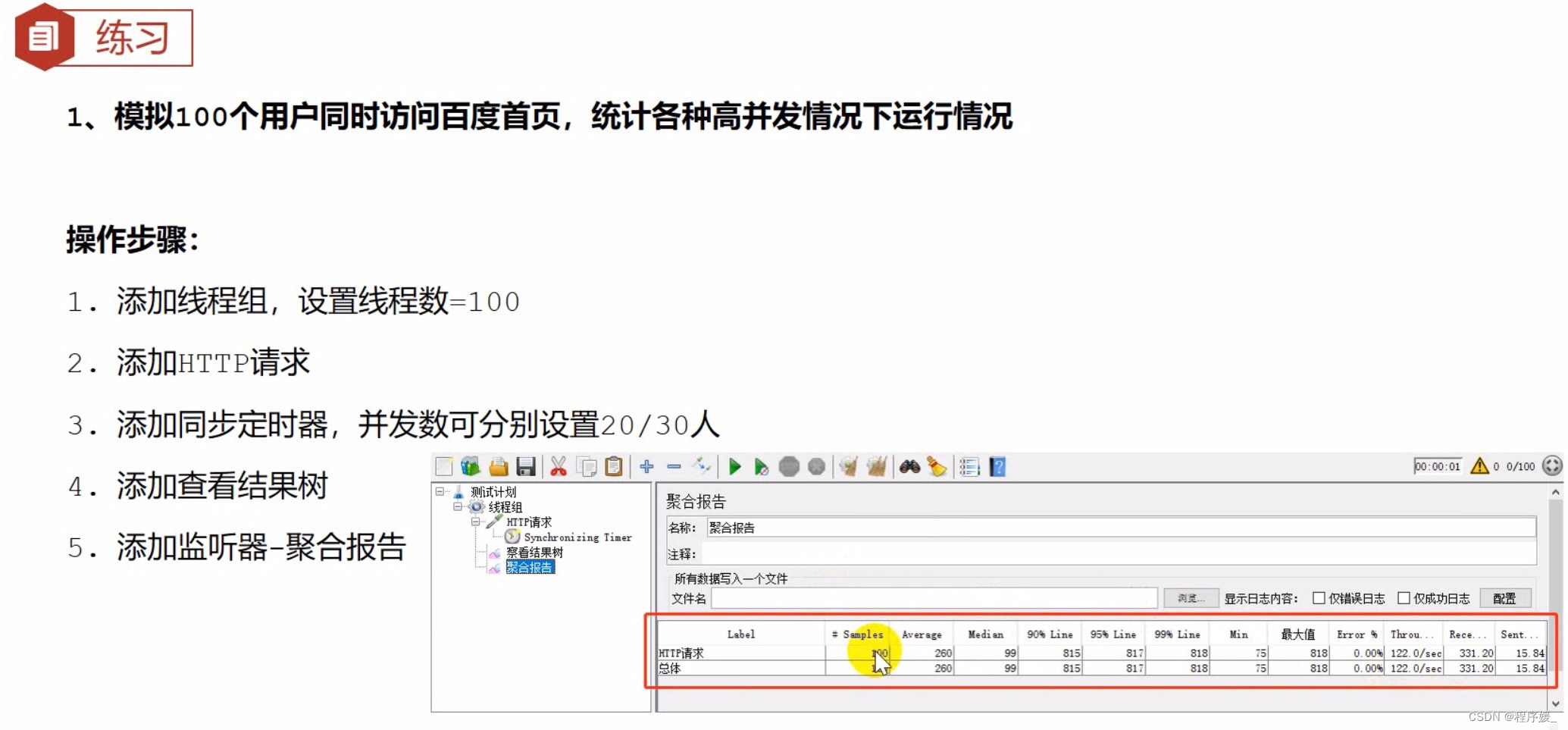
位置: 测试计划 >> 线程组 >>HTTP请求 >>(右键添加)定时器 >> Synchronizing Timer
参数:
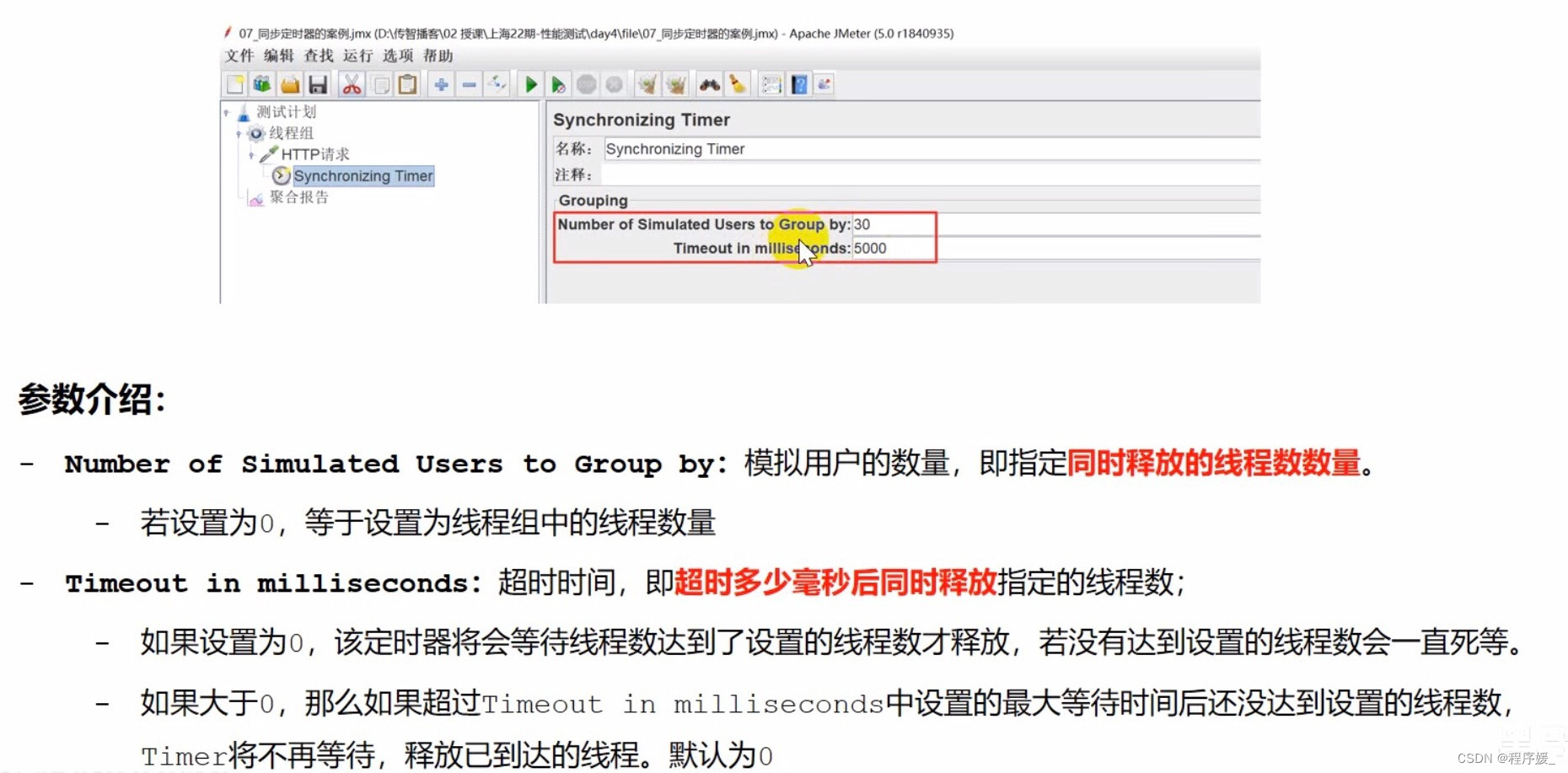
步骤:
- 添加线程组,设置线程数为n
- 添加HTTP请求
- 添加同步定时器
设置并发线程数:同时发送请求的虛拟用户数
设置超时时间:
- 建议设置 \color{red}{建议设置} 建议设置:不设置的话,若没有达到设置的线程数会一直死等
- 不能设置太小 \color{red}{不能设置太小} 不能设置太小:等待时间后还没达到设置的线程数,会释放已到达的线程 - 添加查看结果树
- 添加监听器-聚合报告
常数吞吐量定时器
为什么要使用常数吞吐量定时器?
稳定性测试时,要求模拟用户真实的业务场景。如果用户真实业务场景的QPS为20,如何精确模拟?
作用: 让JMeter按
指定的吞吐量
\color{red}{指定的吞吐量}
指定的吞吐量执行,以
每分钟为单位
\color{red}{每分钟为单位}
每分钟为单位。
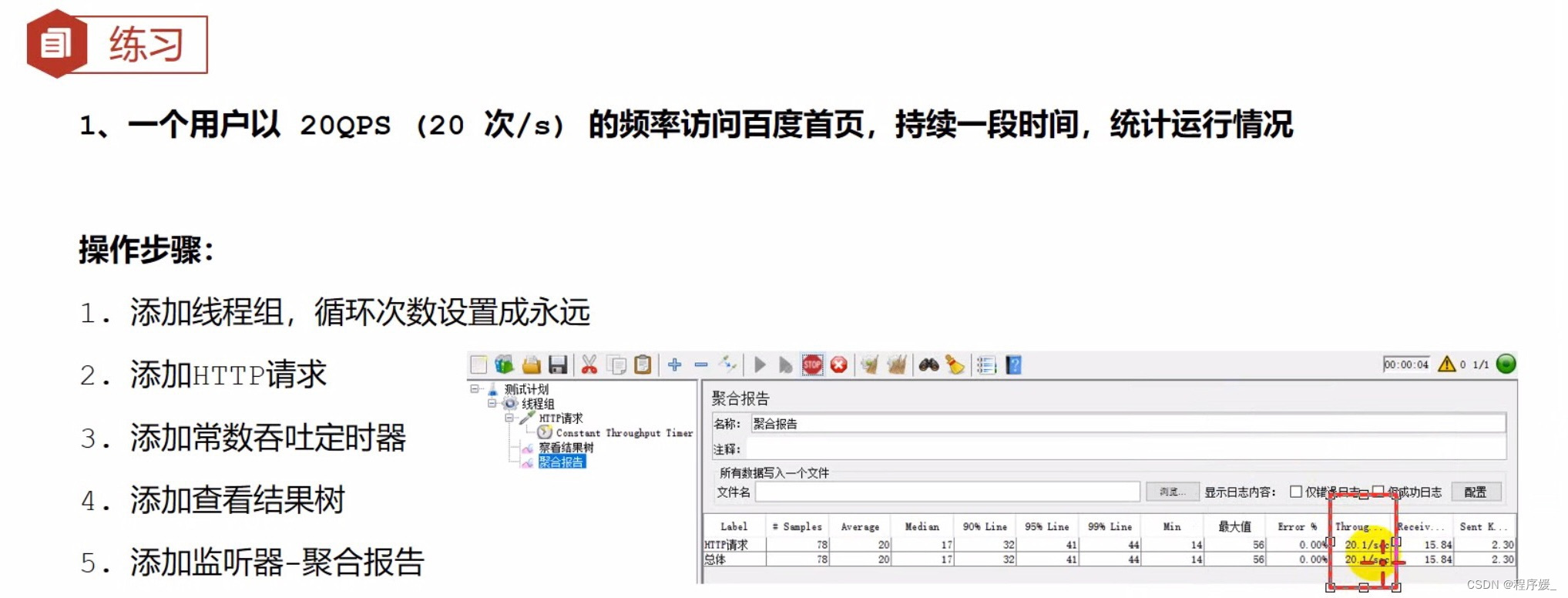
位置: 测试计划 >> 线程组>> H下TP请求>>(右键添加)定时器 >> Constant Throughput Timer(必须添加在需要等待的HTTP请求的子节点下)
参数介绍:

Target throughput (in samples per minute):目标吞吐量。注意这里是每个用户每分钟发送的请求数。
案例要求:
模拟用户真实的业务场景要求:20 QPS
- 如果线程数设置为1,则目标吞吐量设置为 20*60= 1200
- 如果线程数设置为2,则目标吞吐量设置为 20*60/2=600
步骤:
- 添加线程组,循环次数设置成永远
- 添加HTTP请求
- 添加常数吞吐定时器
设置目标吞吐量: 每个用户每分钟发送的请求数
计算方法: 要求 Q P S ∗ 60 / 线程数 \color{red}{要求QPS * 60 /线程数} 要求QPS∗60/线程数 - 添加查看结果树
- 添加监听器-聚合报告

分布式
测试报告
聚合报告
| Term | Definition |
|---|---|
| Lable | 每个JMeter的element(例如HTTP Request)都有一个Name属性,这里显示的就是Name属性的值 |
| #Samples 样本 | 表示你这次测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里显示100 |
| Average 平均值 | 平均响应时间——默认情况下是单个Request的平均响应时间,当使用了Transaction Controller时,也可以以Transaction为单位显示平均响应时间。 |
| Median 中位数 | 中位数,也就是50%用户的响应时间。 |
| 90%Line 90%百分位 | 90%用户的响应时间。 |
| Min 最小值 | 最小响应时间。 |
| Max 最大值 | 最大响应时间 |
| Error% 异常% | 本次测试中出现错误的请求的数量/请求的总数。 |
| Throughput 吞吐量 | 吞吐量——默认情况下表示每秒完成的请求数(Request per Second),当使用了Transaction Controller时,也可以表示类似LoadRunner的Transaction per Second数 |
| KB/sec | 每秒从服务器端接收到的数据量 |
响应时间单位:毫秒
















 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









