






基本查询(不带条件(where))
SQL 语句
查询语句
基本查询
-- 需求1: 准备商品数据, 查询所有数据, 查询部分字段, 起字段别名, 去重
-- 查询所有数据: select * from 表名;
select * from goods;
-- 查询部分字段: select 字段名1, 字段名2 from goods;
select goodsName, price from goods;
-- 起字段别名: select 字段名 as '别名' from goods;
select goodsName as '商品名称', price as '价格' from goods;
-- 注意: 别名的引号可以省略
select goodsName as 商品名称, price as 价格 from goods;
-- 注意: as 关键字也可以省略[掌握]
select goodsName 商品名称, price 价格 from goods;
-- 起别名的作⽤: 1> 美化数据结果的显示效果 2> 可以起到隐藏真正字段名的作⽤
-- 另: 除了可以给字段起别名以外, 还可以给数据表起别名(连接查询时使⽤)
-- 去重: select distinct(字段名) from goods;
-- 效果: 将⽬标字段内重复出现的数据只保留⼀份显示
-- ⼩需求: 显示所有的公司名称
select distinct(company) from goods;
条件查询
⽐较运算符&逻辑运算符
-- 需求2: 查询价格等于30并且出⾃并夕夕的所有商品信息
select * from goods;
-- 查询价格等于30 : ⽐较运算符(特殊: (⼤于等于)>=/(⼩于等于)<=/(不等于)!=/<>)
select * from goods where price=30;
-- 并且出⾃并夕夕的所有商品信息 : 逻辑运算符(and(与)/or(或)/not(⾮))
-- 注意: 作为查询条件使⽤的字符串必须带引号!
select * from goods where price=30 and company='并夕夕';
-- 补充需求: 查询价格等于30但不出⾃并夕夕的所有商品信息
select * from goods where not company='并夕夕' and price=30;
-- 注意: not 与 and 和 or (左右两边连接条件)不同之处在于, not 只对⾃⼰右侧的条件有作⽤(右边连接条件)
select * from goods where price=30 and not company='并夕夕';
模糊查询
-- 需求3: 查询全部⼀次性⼝罩的商品信息
-- 模糊查询: like 和符号 %(任意多个字符)/_(任意⼀个字符)
-- 注意: 作为查询条件使⽤的字符串必须带引号!
-- 注意: 如果需要控制字符数量, 需要使⽤_, 并且有⼏个字符就使⽤⼏个_
-- %关键词% : 关键词在中间
select * from goods where remark like '%⼀次性%';
-- %关键词 : 关键词在末尾
select * from goods where remark like '%⼀次性';
-- 关键词% : 关键词在开头
select * from goods where remark like '⼀次性%';
范围查询
-- 需求4: 查询所有价格在30-100的商品信息
-- 范围查询: 1> ⾮连续范围: in 2> 连续范围: between ... and ...
select * from goods where price between 30 and 100;
-- 注意: between ... and ... 的范围必须是从⼩到⼤
select * from goods where price between 100 and 30;
判断空
-- 需求5: 查询没有描述信息的商品信息
-- 注意: 在 MySQL 中, 只有显示为 NULL 的才为空! 其余空⽩可能是空格/制
表符(tab)/换⾏符(回⻋键)等空⽩符号
-- 判断空: 1> 为空: is null 2> 不为空(双重否定表肯定): is not null
select * from goods where remark is null;
-- 补充需求: 查询有描述信息的所有商品
select * from goods where remark is not null;
其他复杂查询
排序
-- 需求6: 查询所有商品信息, 按照价格从⼤到⼩排序, 价格相同时, 按照数量少到多排序
-- select * from 表名 order by 列1 asc|desc,列2 asc|desc,...
-- 说明: order by 排序, asc : 升序, desc : 降序
-- 注意: 排序过程中, ⽀持连续设置多条排序规则, 但离 order by 关键字越近, 排序数据的范围越⼤!
select * from goods order by price desc;
select * from goods order by price desc, count asc;
-- 注意: 默认排序为升序, asc 可以省略
select * from goods order by price desc, count;
聚合函数
-- 需求7: 查询以下信息: 商品信息总条数; 最⾼商品价格; 最低商品价格;商品平均价格; ⼀次性⼝罩的总数量
-- 聚合函数: 系统提供的⼀些可以直接⽤来获取统计数据的函数
-- 商品信息总条数: count(字段): 查询总记录数
select count(*) from goods;
-- 注意: 统计数据总数, 建议使⽤*, 如果使⽤某⼀特定字段, 可能会造成数据总数错误!
select count(remark) from goods;
-- 最⾼商品价格: max(字段): 查询最⼤值
select max(price) from goods;
-- 最低商品价格: min(字段): 查询最⼩值
select min(price) from goods;
-- 商品平均价格: avg(字段): 求平均值
select avg(price) from goods;
-- ⼀次性⼝罩的总数量: sum(): 求和
-- 注意: 此处的 count 是数据表中字段名!
select sum(count) from goods where remark like '%⼀次性%';
-- 扩展: 在需求允许的情况下, 可以⼀次性在⼀条 SQL语句中, 使⽤所有的聚
合函数
select count(*), max(price), min(price), avg(price) from goods;
分组
-- 需求8: 查询每家公司的商品信息数量
-- 分组: select 字段1,字段2,聚合... from 表名 group by 字段1,字段
2...
-- 说明: group by : 分组
-- 注意:
-- 1> ⼀般情况, 使⽤哪个字段进⾏分组, 那么只有该字段可以在 * 的位置处使⽤, 其他字段没有实际意义(只要⼀组数据中的⼀条)
-- 2> 分组操作多和聚合函数配合使⽤
select count(*) from goods group by company;
select * from goods;
select company, count(*) from goods group by company;
-- 说明: 其他字段没有实际意义(只要⼀组数据中的⼀条)
select price, count(*) from goods group by company;
-- 扩充: 分组后条件过滤
-- 说明: group by 后增加过滤条件时, 需要使⽤ having 关键字
-- 注意:
-- 1. group by 和 having ⼀般情况下需要配合使⽤
-- 2. group by 后边不推荐使⽤ where 进⾏条件过滤
-- 3. having 关键字后侧可以使⽤的内容与 where 完全⼀致(⽐较运算符/逻辑运算符/模糊查询/判断空)
-- 3. having 关键字后侧允许使⽤聚合函数
-- where 和 having 的区别:
-- where 是对 from 后⾯指定的表进⾏数据筛选,属于对原始数据的筛选
-- having 是对 group by 的结果进⾏筛选
-- having 后⾯的条件中可以⽤聚合函数,where 后⾯不可以
分⻚查询
-- 需求9: 查询当前表当中第5-10⾏的所有数据
-- 分⻚查询: select * from 表名 limit start,count
-- 说明: limit 分⻚; start : 起始⾏号; count : 数据⾏数
-- 注意: 计算机的计数从 0 开始, 因此 start 默认的第⼀条数据应该为 0,后续数据依次减1
-- 过渡需求: 获取前 5 条数据
select * from goods limit 0, 5;
-- 注意: 如果默认从第⼀条数据开始获取, 则 0 可以省略!
select * from goods limit 5;
-- 需求:
select * from goods limit 4, 6;
-- 扩展 1: 根据公式计算显示某⻚的数据
-- 已知:每⻚显示m条数据,求:显示第n⻚的数据
-- select * from 表名 limit (n-1)*m, m
-- 示例: 每⻚显示 4 条数据, 求展示第 2 ⻚的数据内容
select * from goods limit 0, 4; -- 第1⻚(有数据)
select * from goods limit 4, 4; -- 第2⻚(有数据)
select * from goods limit 8, 4; -- 第3⻚(有数据)
select * from goods limit 12, 4; -- 第4⻚(⼀共 12 条数据, 每⻚显示 4 条, 没有第 4 ⻚数据)
-- 扩展 2: 分⻚的其他应⽤
-- 需求: 要求查询商品价格最贵的数据信息
select * from goods order by price desc limit 1;
-- 进阶需求: 要求查询商品价格最贵的前三条数据信息
select * from goods order by price desc limit 3
连接查询: 内连接/左连接/右连接/⾃关联
连接查询
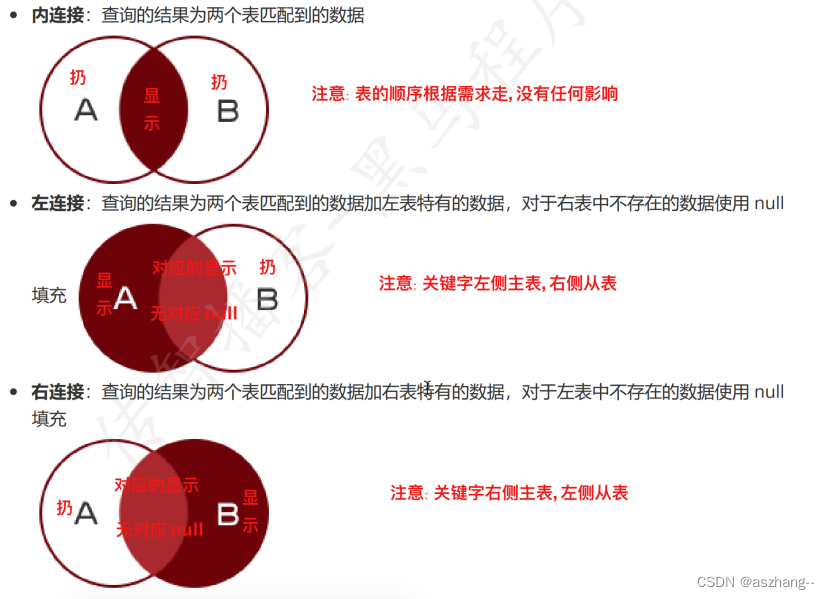
内连接
-- 需求1: 查询所有存在商品分类的商品信息
select * from goods;
select * from category;
-- 内连接: select * from 表1 inner join 表2 on 表1.列=表2.列
-- 显示效果: 两张表中有对应关系的数据都会显示出来, 没有对应关系的数据均不再显示
select * from goods
inner join category on goods.typeId=category.typeId;
-- 扩充: 给表起别名(1> 缩短表名利于编写 2> ⽤别名给表创建副本)
select * from goods go
inner join category ca on go.typeId=ca.typeId;
-- 扩展: 内连接的另⼀种写法(旧式写法)
-- select * from 表1, 表2 where 表1.字段名=表2.字段名;
select * from goods, category where
goods.typeId=category.typeId;
左连接
-- 需求2: 查询所有商品信息,包含商品分类
-- 左连接: select * from 表1 left join 表2 on 表1.列=表2.列
-- 注意: 如果要保证⼀张数据表的全部数据都存在, 则⼀定不能选择内连接,可以选择左连接或右连接
-- 说明:
-- 以 left join 关键字为界, 关键字左侧表为主表(都显示), ⽽关键字右侧
的表为从表(对应内容显示, 不对应为 null)
select * from goods go
left join category ca on go.typeId=ca.typeId;
-- 扩充需求: 以分类为主展示所有内容(以哪张表为主表, 显示结果上是有区别的!)
select * from category ca
left join goods go on ca.typeId=go.typeId;
右连接
-- 需求3: 查询所有商品分类及其对应的商品的信息
-- 右连接: select * from 表1 right join 表2 on 表1.列=表2.列
-- 说明:
-- 以 right join 关键字为界, 关键字右侧表为主表(都显示), ⽽关键字左侧的表为从表(对应内容显示, 不对应为 null)
select * from goods go
right join category ca on go.typeId=ca.typeId;
-- 扩充需求: 查询所有商品信息及其对应分类信息
select * from category ca
right join goods go on ca.typeId=go.typeId;
存在左右连接的必要性
说明: 能够体现左右连接必要性的场景为: ⾄少为三张表进⾏连接查询
注意: 实际⼯作中, 最多也就三张表连接查询
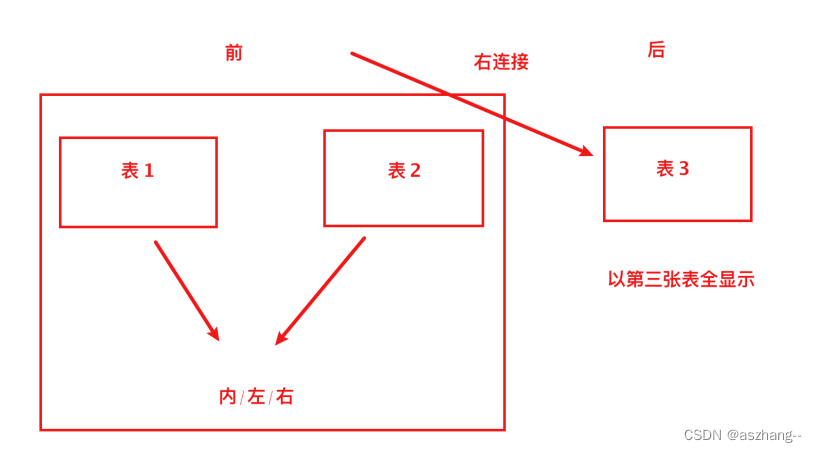
连接查询理解
⾃关联
前提: 1> 数据表只有⼀张 2> 数据表中⾄少有两个字段之间有某种联系
⽅式: 通过给表起别名的形式, 将原本只有⼀张的数据表变为两张, 然后通过对
应字段实现连接查询
查询河南省下所有市的信息
-- 需求4: 查询河南省所有的市
-- 说明: ⽆论是使⽤内连接还是左连接, 都只影响中间数据表的内容多少, 由于最终的过滤条件相同, 因此查询结果⼀致
-- 使⽤内连接
select * from areas a1
inner join areas a2 on a1.aid=a2.pid
where a1.atitle='河南省';
-- 使⽤左连接
select * from areas a1
left join areas a2 on a1.aid=a2.pid
where a1.atitle='河南省';
查询河南省下所有的市和区的信息
-- 需求5: 查询河南省的所有的市和区
-- 说明: 想要实现三级⾏政单位显示, 需要分别处理省和市及市和区(三表连查)
select * from areas a1
left join areas a2 on a1.aid=a2.pid
left join areas a3 on a2.aid=a3.pid
where a1.atitle='河南省';
⼦查询: 查询语句中包含另⼀个查询语句
⼦查询: 在⼀个 select 语句中,嵌⼊了另外⼀个 select 语句,那么嵌⼊的
select 语句称之为⼦查询语句
作⽤: ⼦查询是辅助主查询的,要么充当[条件],要么充当[数据源]
⼦查询语句充当条件
-- 需求6: 查询价格⾼于平均价的商品信息
-- ⼦查询语句充当条件:
-- 求取平均价
select avg(price) from goods;
-- 说明: 充当⼦查询的语句需要使⽤括号括起来(运算优先级括号最⾼!)否则报
错
select * from goods where price > (select avg(price) from
goods);
⼦查询语句充当数据源
-- 需求7: 查询所有来⾃并夕夕的商品信息, 包含商品分类
-- ⼦查询语句充当数据源:
-- select * from goods go
-- left join category ca on go.typeId=ca.typeId;
-- select * from (select * from goods go left join category ca
on go.typeId=ca.typeId) new
-- where new.company='并夕夕';
-- 问题: 连接查询的结果中, 表和表之间的字段名不能出现重复, 否则⽆法直
接使⽤
-- 解决: 将重复字段使⽤别名加以区分(表名.* : 当前表的所有字段)
select * from (select go.*
, ca.id cid, ca.typeId ctid,
ca.cateName from goods go left join category ca on
go.typeId=ca.typeId) new
where new.company='并夕夕';
数据库⾼级: 数据库 ER 模型/外键/索引
ER 模型
E 表示 entry,实体: 描述具有相同特征事物的抽象[数据表]
属性: 每个实体的具有的各种特征称为属性[数据(表内的字段)]
R 表示 relationship,联系: 实体之间存在各种关系,关系的类型包括包括⼀
对⼀、⼀对多、多对
多[表和表之间的联系]
外键
说明: 通过外部数据表的字段, 来控制当前数据表的数据内容变更, 以避免单⽅
⾯移除数据, 导致关联表数据产⽣垃圾数据的⼀种⽅法
注意: 如果⼤量增加外键设置, 会严重影响除数据查询操作以外的其他操作(增/
删/改)的操作效率, 因此在实际项⽬中很少会被采⽤, 但是在⾯试中容易被问
到.
索引
说明: 可以⼤幅度提⾼查询语句的执⾏效率
注意: 如果⼤量增加索引设置, 会严重影响除数据查询操作以外的其他操作(增/删/改)的操作效率, 不⽅便过多添加.
验证索引效果案例实现步骤
说明: 提供的示例⽂件可以使⽤在数据库中使⽤运⾏ SQL ⽂件⽅式导⼊!
-- 开启运⾏时间监测
set profiling=1;
-- 查找第⼀万条数据 10000
select * from test_index where num='10000';
-- 查看执⾏的时间
show profiles;
-- 为表 text_index 的 num 列创建索引
create index test_index on test_index(num);
-- 执⾏查询语句
select * from test_index where num='10000';
-- 再次查看执⾏的时间
show profiles;
实际项⽬中数据库中表的样式

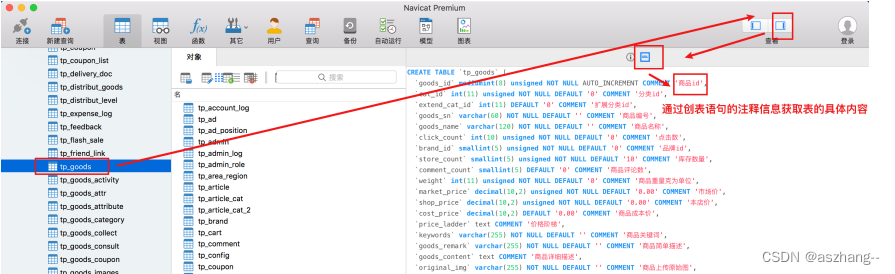
查看创表语句中的字段注释















 135
135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









