







目录
范围查询
BETWEEN...AND
IN( 集合)
-- 查询年龄大于等于20 小于等于30
SELECT* FROM student WHERE age >= 20&& age <=30;
SELECT* FROM student WHERE age >= 20ANDage <=30;
SELECT* FROM student WHERE age BETWEEN 20 AND 30;
-- 查询年龄22岁,18岁,25岁的信息
SELECT* FROM student WHERE age = 22ORage = 18ORage = 25
SELECT* FROM student WHERE age IN(22,18,25);in
select id from table where name in('name1','name2')为空
IS NULL 和IS NOT NULL
LIKE
DISTINCT
-- 查询英语成绩不为null
SELECT * FROM student WHERE english IS NOT NULL;模糊查询
like
_:单个任意字符
%:多个任意字符
-- 查询姓马的有哪些? like
SELECT* FROM student WHERE NAME LIKE'马%';-- 查询姓名第二个字是化的人
SELECT* FROM student WHERE NAME LIKE"_化%"; -- 查询姓名是3个字的人
SELECT* FROM student WHERE NAME LIKE'___'; -- 查询姓名中包含德的人
SELECT* FROM student WHERE NAME LIKE'%德%';去重查询
-- 关键词 DISTINCT 用于返回唯一不同的值。
-- 语法:SELECT DISTINCT 列名称 FROM 表名称
SELECT DISTINCT NAME FROM student;AND OR
使用 AND 来显示所有价格为 79 并且Source of sales为 "Shipping" 的记录。
select * from [dbo].[spring05] where Price = 79 and [Source of sales] = 'Shipping'使用 OR 来显示所有价格为 79 或者bp为 0的人。
select * from [dbo].[spring05] where Price = 79 or Bp = 0结合 AND 和 OR 运算符
我们也可以把 AND 和 OR 结合起来(使用圆括号来组成复杂的表达式)。此处我们筛选价格为79或者35,同时BP又等于0的记录。
select * from [dbo].[spring05] where (Price = 79 or Price = 35) and bp = 0如果没有括号,Where后的子句就变为A or B and C,在SQL中and的优先级高于or,所以先计算B and C再用这个计算结果去和A做or结合得出最终结果。
排序查询
语法:orderby 子句
order by 排序字段1 排序方式1 , 排序字段2 排序方式2...注意:如果有多个排序条件,则当前边的条件值一样时,才会判断第二条件。
-- 例子
SELECT * FROM person ORDER BY math; --默认升序
SELECT * FROM person ORDER BY math desc; --降序聚合函数
格式
select MAX(prod_price) from Products作用
将一列数据作为一个整体,进行纵向的计算。
1.count:计算个数
count(1):统计所有的记录(包括null)。
count(*):统计所有的记录(包括null)。
count(字段):统计该"字段"不为null的记录。
count(distinct 字段):统计该"字段"去重且不为null的记录。
2.max:计算最大值
3.min:计算最小值
4.sum:计算和
5.avg:计算平均数
不要看到平均就 觉得一定用avg,复杂的都是两个 count 相除
例如: 统计每个学校各难度的用户平均刷题数_牛客题霸_牛客网 (nowcoder.com)
# 平均刷题数: 答题细节表 的 题目数量 / 答题细节表 的 答题设备数量 count(qpd.question_id) / count(distinct qpd.device_id) avg_answer_cnt
注意
聚合函数本身不支持直接使用除号进行除法运算,但你可以通过子查询、派生表或使用 CASE 表达式等方法来在聚合函数的结果上进行除法操作。
例如:统计每个学校的答过题的用户的平均答题数_牛客题霸_牛客网 (nowcoder.com)
select university, count(question_id) / count(distinct qpd.device_id) as avg_answer_cnt from question_practice_detail as qpd, user_profile as up where qpd.device_id = up.device_id group by university
分组查询 group by
语法:groupby 分组字段;
注意
- 分组之后查询的字段:分组字段、聚合函数
- 可以搭配 HAVING使用
-- 按照性别分组。分别查询男、女同学的平均分
SELECT sex , AVG(math) FROM student GROUP BY sex;-- 按照性别分组。分别查询男、女同学的平均分,人数
SELECT sex ,AVG(math),COUNT(id) FROM student GROUP BY sex;-- 按照性别分组。分别查询男、女同学的平均分,人数要求:分数低于70分的人,不参与分组
SELECT sex , AVG(math),COUNT(id)FROM student WHERE math> 70 GROUP BY sex;-- 按照性别分组。分别查询男、女同学的平均分,人数 要求:分数低于70分的人,不参与分组,分组之后。人数要大于2个人
SELECT sex , AVG(math),COUNT(id) FROM student WHERE math> 70 GROUPBY sex HAVING COUNT(id) > 2;
SELECT sex , AVG(math),COUNT(id) 人数 FROM student WHERE math > 70 GROUPBY sex HAVING 人数 > 2;也可以按照两个字段分组
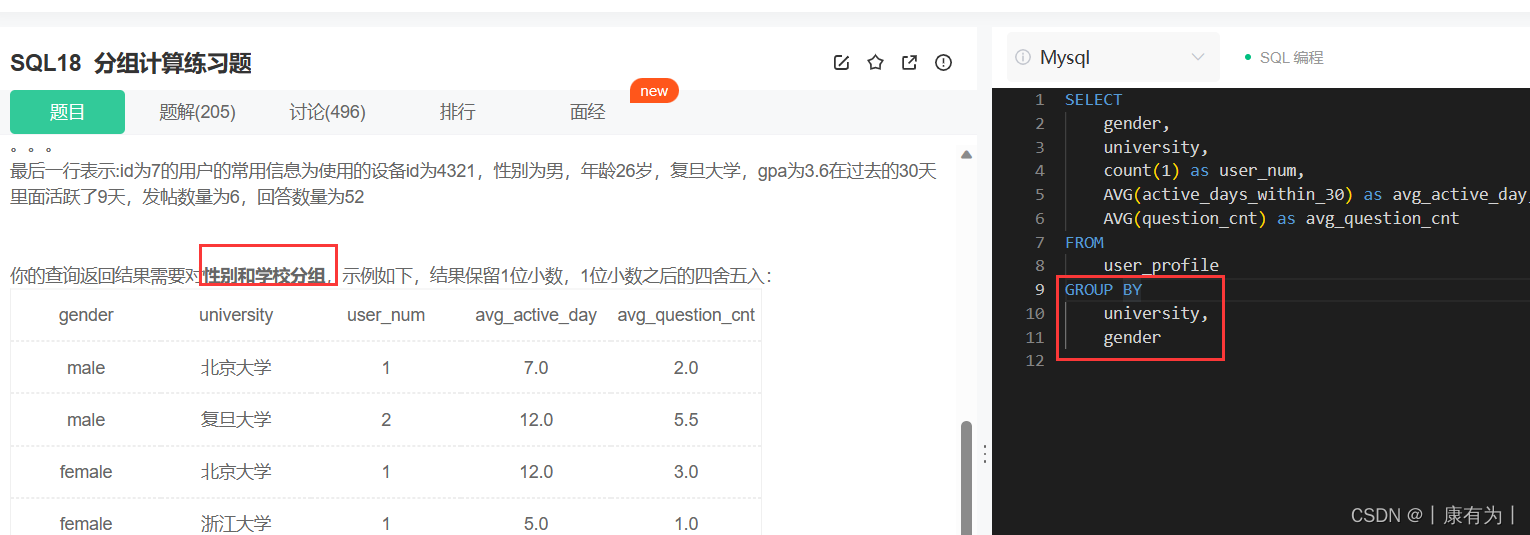
分组后过滤:HAVING
作用
HAVING子句用于对分组后的结果再进行过滤,
它的功能有点像WHERE子句,但它用于组而不是单个记录。
注意
- 在HAVING子句中可以使用统计函数,但在WHERE子句中则不能。
- HAVING通常与GROUP BY子句一起使用。
- HAVING 要 写到GROUP BY 后面
例36.查询学生表中人数大于等于3的班号和人数。
SELECT 班号, COUNT(*) 人数
FROM 学生表
GROUP BY 班号
HAVING COUNT(*) >= 3例37.查询平均成绩大于等于80的学生的学号、选课门数和平均成绩。
SELECT 学号, COUNT(*) 选课门数,
AVG(成绩) 平均成绩 FROM 成绩表
GROUP BY 学号
HAVING AVG(成绩) >= 80分组过滤练习题_牛客题霸_牛客网 (nowcoder.com)
保留小数
MySQL查询的时候,需要保留两位小数,常用的几个函数,如下
round:数据四舍五入
ROUND(x,n) 数据四舍五入
SELECT ROUND(1234.567,2)
输出结果为1234.57
SELECT ROUND(1234.567)
输出结果为1234
SELECT ROUND(1234.567,-3)
输出结果为1000format:格式化数据
FORMAT(x,n) 格式化数据,强制保留n位小数(四舍五入),需要注意的是,返回的结果为string类型
SELECT FORMAT(1234.567,2)
输出结果为1,234.57
SELECT FORMAT(1234,2)
输出结果为1,234.00truncate:返回小数点后n位的数据
TRUNCATE(x,n)返回小数点后n位的数据
SELECT TRUNCATE(1234.567,2)
输出结果为1234.56convert:类型转换
CONVERT(value,type) 类型转换,CONVERT()函数会对小数部分进行四舍五入操作
SELECT CONVERT(1234.567,DECIMAL(10,2))
输出结果为 1234.57多表查询
内连接查询:
1. 从哪些表中查询数据
2.条件是什么
3. 查询哪些字段
1.隐式内连接:使用where条件消除无用数据
-- 查询员工表的名称,性别。部门表的名称
SELECT emp.name,emp.gender,dept.name FROM emp,dept WHERE emp.`dept_id` = dept.`id`;
SELECT
t1.name, -- 员工表的姓名
t1.gender,-- 员工表的性别
t2.name -- 部门表的名称
FROM
emp t1,
dept t2
WHERE
t1.`dept_id` = t2.`id`;2.显式内连接: inner join on
-- 语法:
select 字段列表 from 表名1 [inner] join 表名2 on 条件
-- 例如:
SELECT * FROM emp INNER JOIN dept ON emp.`dept_id` = dept.`id`;
SELECT * FROM emp JOIN dept ON emp.`dept_id` = dept.`id`; 例如
假设我们有两个表:一个是 "顾客表(Customers)",另一个是 "订单表(Orders)",它们都有一个共同的字段 "顾客ID(customer_id)"。现在我们想要通过 "INNER JOIN" 来获取每个顾客的订单信息。
SELECT Customers.customer_id, Customers.name, Orders.order_id, Orders.order_date FROM Customers INNER JOIN Orders ON Customers.customer_id = Orders.customer_id;使用where 语句也是能达到上面的效果,但是用inner join更清晰
SELECT Customers.customer_id, Customers.name, Orders.order_id, Orders.order_date FROM Customers, Orders WHERE Customers.customer_id = Orders.customer_id;
外连接查询
join、inner join、left join、right join、outer join的区别_inner join和join的区别_CoderYJ的博客-CSDN博客
1.左外连接 -- 查询的是左表所有数据以及其交集部分。
-- 语法:select 字段列表 from 表1 left [outer] join 表2 on 条件;
-- 例子:
-- 查询所有员工信息,如果员工有部门,则查询部门名称,没有部门,则不显示部门名称
SELECT t1.*,t2.`name`
FROM emp t1
LEFT JOIN dept t2
ON t1.`dept_id` = t2.`id`;2.右外连接 -- 查询的是右表所有数据以及其交集部分。
-- 语法:
select 字段列表 from 表1 right [outer] join 表2 on 条件;
-- 例子:
SELECT * FROM dept t2 RIGHT JOIN emp t1 ON t1.`dept_id` = t2.`id`;子查询(嵌套查询)
嵌套查询是指在一个查询中嵌入另一个查询,内部查询返回的结果作为外部查询的条件之一或用于进一步筛选数据。
嵌套查询可以出现在SELECT语句的WHERE子句、FROM子句或HAVING子句中,也可以用于UPDATE和DELETE语句中。
例子
在WHERE子句中使用嵌套查询:
假设有两个表:customers(包含顾客信息)和orders(包含订单信息),我们想要找出所有在2023年下单的顾客。
SELECT *
FROM customers
WHERE
customer_id IN (SELECT customer_id FROM orders WHERE order_date BETWEEN '2023-01-01' AND '2023-12-31');
在FROM子句中使用嵌套查询:
假设有两个表:products(包含产品信息)和categories(包含产品分类信息),我们想要找出每个分类下的产品数量。
SELECT category_name, (
SELECT COUNT(*)
FROM products
WHERE products.category_id = categories.category_id
) AS product_count
FROM categories;
在HAVING子句中使用嵌套查询:
假设有一个表:
employees(包含员工信息)和
departments(包含部门信息),我们想要找出员工数量大于平均员工数量的部门。
SELECT
department_name,
COUNT( * ) AS employee_count
FROM
employees
INNER JOIN departments ON employees.department_id = departments.department_id
GROUP BY
department_name
HAVING
COUNT( * ) > ( SELECT AVG( employee_count ) FROM ( SELECT COUNT( * ) AS employee_count FROM employees GROUP BY department_id ) AS avg_count );子查询
-- 查询工资最高的员工信息
-- 1 查询最高的工资是多少 9000
SELECT MAX(salary) FROM emp;
-- 2 查询员工信息,并且工资等于9000的
SELECT * FROM emp WHERE emp.`salary` = 9000;
-- 一条sql就完成这个操作。这就是子查询
SELECT * FROM emp WHERE emp.`salary` = (SELECT MAX(salary) FROM emp);子查询的结果是单行单列的
子查询可以作为条件,使用运算符去判断。 运算符: > >= <
-- 查询员工工资小于平均工资的人
SELECT * FROM emp WHERE emp.salary < (SELECT AVG(salary) FROM emp);子查询的结果是多行单列的:
子查询可以作为条件,使用运算符in来判断
-- 查询'财务部'和'市场部'所有的员工信息
SELECT id FROM dept WHERE NAME = '财务部' OR NAME = '市场部';
SELECT * FROM emp WHERE dept_id = 3 OR dept_id = 2;
-- 子查询
SELECT * FROM emp WHERE dept_id IN (SELECT id FROM dept WHERE NAME = '财务部' OR NAME = '市场部');子查询的结果是多行多列的:
子查询可以作为一张虚拟表参与查询
-- 查询员工入职日期是2011-11-11日之后的员工信息和部门信息
-- 子查询
SELECT
*
FROM
dept t1,
( SELECT * FROM emp WHERE emp.`join_date` > '2011-11-11' ) t2
WHERE
t1.id = t2.dept_id;
-- 普通内连接
SELECT
*
FROM
emp t1,
dept t2
WHERE
t1.`dept_id` = t2.`id`
AND t1.`join_date` > '2011-11-11'集合查询
语法
Select <列名1>,<列名2>,<列名3>... from <表名>
union -- 或者其他 intersect、except、union all等)
Select <列名1>,<列名2>,<列名3>... from <表名>注意
- union 并集、INTERSECT 交集、EXCEPT 差集
- 任何执行Union、 INTERSECT、EXCEPT的语句,都要注意,该关键字前后的Select 语句中选择的列的数量要一致,不一致会提示错误
- Union vs Union All 的区别:Union 操作,自动去重复,即两个或多个数据表中相同的行只吃出现一次;若想要所有表中的对应的数据都显示的话,则需要用到Union all
其他的常用函数
CASE:替代多个if语句的情况
通用
CASE函数语法:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
WHEN conditionN THEN resultN
ELSE default_result
END
上面的语法中,CASE根据条件逐一检查,如果满足条件1,则返回结果1,否则继续检查条件2,依此类推。如果没有任何条件满足,则返回ELSE后面指定的default_result。
例题1
下面是一个简单的例子,假设我们有一个students表,其中包含学生的姓名和分数。我们想根据分数判断学生的等级:
SELECT student_name, score, CASE WHEN score >= 90 THEN 'A' WHEN score >= 80 THEN 'B' WHEN score >= 70 THEN 'C' WHEN score >= 60 THEN 'D' ELSE 'F' END AS grade FROM students;在上面的例子中,
CASE函数根据分数的不同范围返回不同的等级,如果分数高于等于90,则返回'A',如果在80到89之间,则返回'B',依此类推。
例题2
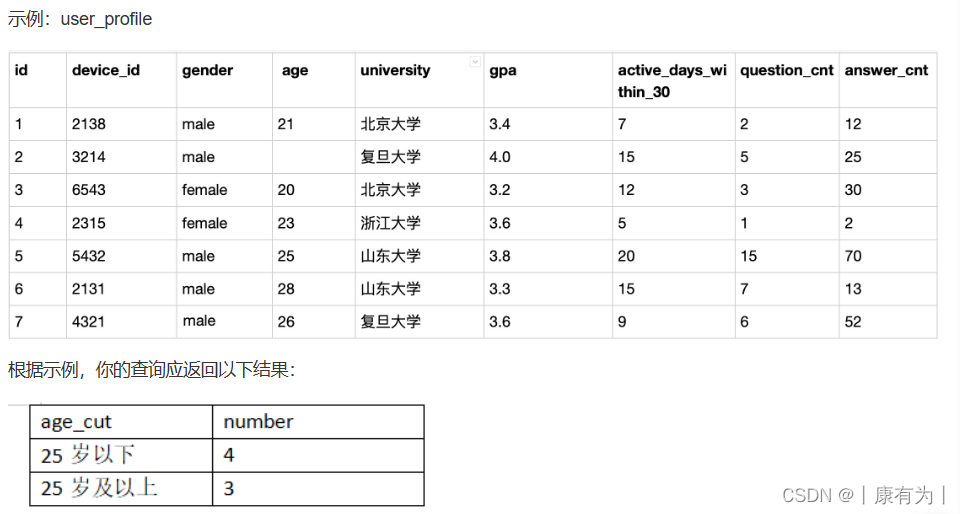
计算25岁以上和以下的用户数量_牛客题霸_牛客网 (nowcoder.com)
题目:现在运营想要将用户划分为25岁以下和25岁及以上两个年龄段,分别查看这两个年龄段用户数量
SELECT CASE WHEN age < 25 OR age IS NULL THEN '25岁以下' WHEN age >= 25 THEN '25岁及以上' END age_cut,COUNT(*)number FROM user_profile GROUP BY age_cut
日期时间函数
-- NOW(): 返回当前日期和时间。
SELECT NOW();
-- CURDATE(): 返回当前日期(去掉时间部分)。
SELECT CURDATE();
-- CURTIME(): 返回当前时间(去掉日期部分)。
SELECT CURTIME();
-- DATE()、TIME()、MONTH()、DAY()、HOUR()、MINUTE()、SECOND():提取日期、时间、月、天、小时、分钟、秒 部分。
SELECT DATE(datetime_column) FROM table_name;
SELECT MINUTE(time_column) FROM table_name;
-- DATEDIFF(): 计算两个日期之间的天数差。
SELECT DATEDIFF(end_date, start_date) FROM table_name;
-- DATE_ADD(): 在日期上添加时间间隔。
SELECT DATE_ADD(date_column, INTERVAL 1 DAY) FROM table_name;
-- DATE_SUB(): 在日期上减去时间间隔。
SELECT DATE_SUB(date_column, INTERVAL 1 MONTH) FROM table_name;
例题 计算用户8月每天的练题数量_牛客题霸_牛客网 (nowcoder.com)
描述
题目:现在运营想要计算出2021年8月每天用户练习题目的数量,请取出相应数据。
示例:question_practice_detail
id
device_id
question_id
result
date
1
2138
111
wrong
2021-05-03
2
3214
112
wrong
2021-05-09
3
3214
113
wrong
2021-06-15
4
6543
111
right
2021-08-13
5
2315
115
right
2021-08-13
6
2315
116
right
2021-08-14
7
2315
117
wrong
2021-08-15
……
根据示例,你的查询应返回以下结果:
day
question_cnt
13
5
14
2
15
3
16
1
18
1
select day (date) as day, count(question_id) question_cnt from question_practice_detail where year (date) = 2021 and month (date) = 8 group by day
文本函数
SUBSTRING_INDEX
SUBSTRING_INDEX()函数用于从一个字符串中获取子串,并且可以指定一个分隔符来确定获取的子串的位置。这个函数可以很方便地从字符串中提取特定位置的子串,特别适用于处理包含分隔符的数据。
-- 截取有关
SUBSTRING_INDEX(str, delimiter, count)参数解释:
- str:要进行处理的原始字符串。
- delimiter:分隔符,用于确定子串的位置。
- count:指定要获取的子串在原始字符串中的位置。如果count为正数,则从左边开始查找;如果为负数,则从右边开始查找。
如果想获取中间的字符串需要进行两次切割将其进行嵌套使用
示例:
假设有一个包含姓名和邮箱的字符串,格式如下:"John Doe:johndoe@example.com"。
获取姓名(冒号为分隔符,从左边开始获取):
sqlCopy codeSELECT SUBSTRING_INDEX("John Doe:johndoe@example.com", ":", 1); -- 输出:John Doe
文本 其他方法
-- 示例1:使用CONCAT函数连接字符串
SELECT CONCAT(first_name, ' ', last_name) AS full_name FROM customers;
-- 示例2:使用LENGTH函数获取字符串长度
SELECT LENGTH('Hello, World!') AS str_length;
-- 示例3:使用UPPER函数将字符串转换为大写
SELECT UPPER('hello') AS upper_case;
-- 示例4:使用LOWER函数将字符串转换为小写
SELECT LOWER('WORLD') AS lower_case;
-- 示例5:使用SUBSTRING函数提取字符串的子串(注意这里下标是从1开始,前闭后闭)
SELECT SUBSTRING('Hello, World!', 1, 5) AS sub_str; -- Output: "Hello"
-- 示例6:使用TRIM函数去除字符串两端的空格或指定字符
SELECT TRIM(' Hello ') AS trimmed_str; -- Output: "Hello"
-- 示例7:使用REPLACE函数替换字符串中的子串
SELECT REPLACE('Hello, World!', 'World', 'Universe') AS replaced_str; -- Output: "Hello, Universe!"
-- 示例8:使用INSTR函数返回子串在字符串中第一次出现的位置
SELECT INSTR('Hello, World!', 'World') AS position; -- Output: 8
-- 示例9:使用LEFT函数返回字符串左边的指定字符数
SELECT LEFT('Hello, World!', 5) AS left_str; -- Output: "Hello"
-- 示例10:使用RIGHT函数返回字符串右边的指定字符数
SELECT RIGHT('Hello, World!', 6) AS right_str; -- Output: "World!"
-- 示例11:使用FORMAT函数格式化数字,并设置千位分隔符
SELECT FORMAT(1234567.89, 2) AS formatted_num; -- Output: "1,234,567.89"
-- 示例12:使用CONVERT函数将一个表达式转换为指定的字符集或数据类型
SELECT CONVERT('42', UNSIGNED) AS number; -- Output: 42
例题:统计每种性别的人数_牛客题霸_牛客网 (nowcoder.com)
select distinct SUBSTRING(profile,15,LENGTH(profile)) as gender, count(SUBSTRING(profile,15,LENGTH(profile))) as number from user_submit group by gender
推荐新手刷的sql题
牛客网在线编程_SQL篇_非技术快速入门 (nowcoder.com)
帮到你的话,点个赞吧
















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









