







目录
1. 启动redis
切换目录到redis目录下,在当前目录打开一个CMD窗口, 输入以下命令
# 启动redis
redis-server.exe redis.windows.conf
切换目录到redis目录下,在当前目录再打开一个CMD窗口,输入以下命令
redis-cli.exe -h 127.0.0.1 -p 6379
# 检测连接
ping
2. 背景信息
1. redis一共16个数据库
2. 为什么选择6379这个端口号?
6379对应手机按键MERZ,是一个意大利舞女;REDIS作者早年看电视觉得MERZ在节目中的一些话可笑愚蠢。为REDIS选为一个数字作为默认端口号时,REDIS作者就拿MERZ对应手机按键的号码6379来当作这个端口号了。
3. Springboot2.XX后,原来使用的jedis被替换成了lettuce
jedis: 采用的直连,多线程的话是不安全的,如果想要安全,需要使用jedis pool连接池。BIO模式
lettuce:采用netty,实例可以在多个线程内共享,不存在线程不安全的情况。更像是NIO的模式。
3. 五大基本数据类型+三大特殊类型
3.1 String
#清空数据库
FLUSHDB
#清空全部数据库内容
FLUSHALL
#增加1
INCR views
#减少1
DECR views
#增加10
INCRBY views 10
#减少10
DECRBY views 10
#截取key对应的value的 0-3位字符串
GETRANGE key 0 3
#截取key对应的value
GETRANGE key 0 -1
#替换key对应的value 第1位的字符串开始替换成nihao,比如“helloworld”变成“hnihaoorld”
SETRANGE key 1 nihao
#20秒后过期, set with expire
SETEX key 20
# 如果没有值,则插入, set if not exist
SETNEX
# 如果不存在,则返回nil,如果存在之
# 如果存在值 ,获取原来的值,并设置新的值
GETSET
使用场景:
计数器,统计多单位的数量,粉丝数,对象缓存存储
3.2 List 列表
所有list命令都是以L开头的
#将一个值从列表的头部(左)边插入
LPUSH list one
#将一个值从列表的头部(左)边移除
LPOP
#将一个值从列表的尾部(右)边插入
RPUSH list one
#将一个值从列表的尾部(右)边移除
RPOP
# 获取list的下标为1的值
LINDEX list 1
# 获取list的长度
LLEN list
# 移除列表指定个数的value
# 移除列表里2个为“three”的值
LREM list 2 three
# 截取指定的长度
# [1,2,3,4] -> [2,3]
LTRIM list 1 2
# 移动值:list右边弹出一个值,左边插入newlist
# list: [1,2,3,4] -> list: [1,2,3]
# newlist: [] -> newlist: [4]
RPOPLPUSH list newlist
#在某个值前面插入
LINSERT list BEFORE"world" “hello”
#在某个值后面插入
LINSERT list AFTER"world" “~”
使用场景:消息排队,消息队列(LPUSH,RPOP), 栈(LPUSH,LPOP)
3.3 Set 集合
# 将一个值从set中插入
SADD set "hello"
# 查看set中所有值
SMEMBERS set
# 查看set中某个值是否存在
SISMEMBERS set "hello"
# 查看set值的个数
SCARD set
# 将一个值从set中移除
SREM set "hello"
# 随机抽选出指定的值
SRANDMEMBER
# 随机删除set中一个元素
SPOP
#将指定的值,移动到另一个set
#将set中“nihao”这个值,移动到另一个set2
SMOVE set set2 "nihao"
#差集
SDIFF s1 s2
#交集
SINTER s1 s2
#并集
SUNION s1 s2
使用场景:微博B站,共同关注,共同爱好
差集交集并集
3.4 Hash 哈希
# 形式:key:[key:value]
# 给key为hash的值里插入[name:yangjiling]这个hashmap
HSET hash name yangjiling
# 查询key为hash值里的 hashmap 查询key为name的值
HGET hash name
# 获取hash里的所有键值对
HGETALL hash
# 获取hash里的键值个数
HLEN hash3.5 Zset 有序集合
#给有序的set加1
ZADD set 1 one
# 从最小到最大排序
# ZRANGEBYSCORE key min max
ZRANGEBYSCORE salary -inf +inf
# 移除有序集合中的元素
ZREM salary xiaohong
# 获取有序集合中的个数
ZCARD salary
# 获取指定区间的成员数量
ZCOUNT salary 1 2使用场景:
set排序,统计全班成绩,工资表排序,带权重进行判断,排行榜应用,top N测试
3.6 Geospatial 地理空间
# 添加地理位置
# 规则添加,两级无法添加,
GEOADD key longitude latitude member
# 两点间的距离
GEODIST key member1 member2 使用场景:附近的人
3.7 Hyperloglog
hyperloglog是基数(不重复的元素个数)统计的算法,优点:占用的内存是固定的,2^64不同元素的基数,只需要废12k的内存!缺点:0.81%的错误率。
# 添加
PFADD key a b c d
# 查看key里当前的个数
PFCOUNT key
# 将key1和key2合并为mergeKey
PFMERGE mergeKey key1 key2
使用场景:页面的UA,页面访问量,一个人放问页面多次,还是算作一个人
传统:set保存用户的id,set中元素的数量就是基数;缺点:如果id比较长,保存大量的id,会浪费内存,重点是计数,不是保存id
3.8 BitMap 位存储
使用场景:疫情感染人数,统计用户信息(统计活跃用户/非活跃用户| 登录/非登录用户),查看打卡天数(365天打卡),两种状态就可以使用位图,操作二进制进行操作。
365天=365bit,1字节=8bit, 大概365/8约等于46字节左右
# 打卡7天 SET key [代表周一-周天] [0:未打卡;1:打卡]
SETBIT sign 0 1
SETBIT sign 1 0
SETBIT sign 2 1
SETBIT sign 3 0
SETBIT sign 4 1
SETBIT sign 5 1
SETBIT sign 6 1
#查看某一天是否打卡: 查看周四是否打卡
GETBIT sign 3
# 查看多少个1
# 统计一周打卡记录
BITCOUNT sign4. 基本事务
【不保证事物的原子性】redis单条命令是保证原子性的,事务是不保证原子性的。
【无事务隔离级别】没有事务隔离级别的概念
【一次性】如果把命令放在队列里执行,执行错误的就会被去除,继续下一个执行。
【顺序性】一个事务中的所有命令都会被序列化,会按照顺序执行。
【排他性】
MULTI # 多个命令放入队列
set key1 value1
set key2 value2
get key2
set key3 value3
EXEC # 执行
DISCARD # 放弃事务
# 监视
WATCH key
# 取消监视
UNWATCH key编译型异常:(例如:执行一个redis不存在的命令)执行事务也是报错的,所有的命令都不会被执行
运行时异常:(例如:给一个不存在的值加1),虽然一条命令失败,其他的还是可以正常执行
锁
4.1 乐观锁
乐观锁的执行:更新数据的时候判断一下,在此期间有没有人修改过这个数据。
1. 获取version
2. 更新的时候比较version, 如果和第一步的version不一样了,事务执行失败
多线程修改值后,redis的watch可以当作乐观锁的操作。
监视money, 正常执行结束
127.0.0.1:6379> SET money 100
OK
127.0.0.1:6379> get key *
(error) ERR wrong number of arguments for 'get' command
127.0.0.1:6379> get keys
(nil)
127.0.0.1:6379> keys
(error) ERR wrong number of arguments for 'keys' command
127.0.0.1:6379> keys *
1) "money"
127.0.0.1:6379> set out 0
OK
127.0.0.1:6379> watch money
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> decrby money 20
QUEUED
127.0.0.1:6379> incrby out 20
QUEUED
127.0.0.1:6379> exec
1) (integer) 80
2) (integer) 20监视money, 非正常执行结束返回(nil)
线程1,在线程2还没进行exec执行操作的时候,更改了money的值
127.0.0.1:6379> get money
"80"
127.0.0.1:6379> set money 1000
OK线程2,最后执行exec执行操作的时候,不会成功,只返回了(nil)
127.0.0.1:6379> watch money #监视线程
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> decrby money 10
QUEUED
127.0.0.1:6379> incrby out 10
QUEUED
127.0.0.1:6379> exec #执行之前,另外一个线程修改了值,那么就会导致事务的失败
(nil)如果事务执行失败,就解锁(unwatch),再获取最新的值再次进行监视(watch key),在最后exec的时候,监视值是否发生变化,没有变化就执行成功,如果没有变化就继续解锁,监视...
5. SpringBoot使用Redis
1. 导入依赖,在pom.xml的dependencies里导入
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
</dependencies>2. 配置文件,在application.properties下配置
spring.redis.host= 127.0.0.1
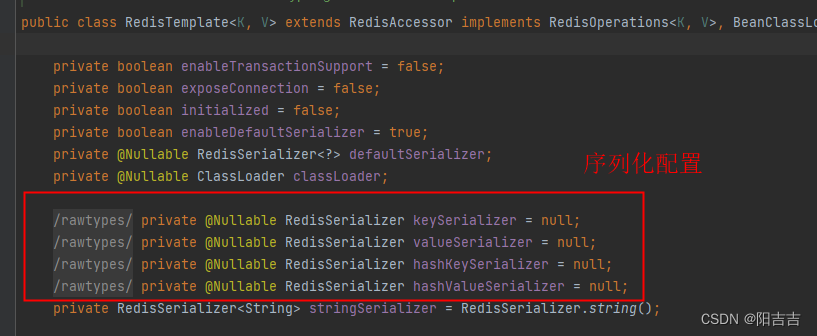
spring.redis.port= 63793. 序列化配置:
pojo都要序列化
中文的乱码:默认的序列化方式是JDK序列化
6. Redis.confg文件
1. 单位,对大小写不敏感,可以配置多个配置文件

配置讲解
bind 127.0.0.1 #绑定的ip
protected-mode yes #保护是,默认开
port 6379 #端口号
#通用配置
daemonize yes #以守护线程的方式运行,默认,自己设置为yes
# 如果以后台方式运行,就需要指定一个pid(进程)文件
pidfile /var/run/redis.pid
# 900秒内,如果至少有1个key修改过,就可以进行持久化操作
save 900 1
save 300 10
save 60 10000
# 持久化出错,是否继续工作
stop-writes-on-bgsave-error yes
# 是否压缩rdb文件,需要消耗性能
rdbcompression yes
# 保存rdb文件,进行错误的检查校验
rdbchecksum yes
# 是都需要密码
requirepass
maxclients 10000 #连接客户端的最大数量
maxmemory <bytes> #配置的最大容量
maxmemory-policy noeviction #内存达到上线的处理策略
# APPEND ONLY 模式 aof配置
appendonly no # 默认不开启aof模式的,默认是rdb方式持久化的,在大部分的情况下,rdb完全够用
appendfilename "appendonly.aof" # 持久化的文件的名字
# appendfsync everysec 每次修改都会sync,消耗性能
appendfsync everysec #每秒执行一次sync,可能会丢失这1s的数据
# appendfsync no 不执行sync,操作系统自己同步数据,速度最快
6. 持久化

dump.rdb触发规则:
1. save规则满足的情况下,会自动触发规则
2. 执行flushall命令,也会触发rdb规则
3. 推出redis, 也会生成rdb文件
如何恢复rdb文件?
只需要将rdb文件放在redis启动目录即可,redis启动的时候会自动检查dump。rdb恢复其中的数据。
优点:
1. 适合大规模数据的回复,dump.rdb
2. 如果对数据的完整性不高
缺点:
1. 需要一定的个时间间隔进程操作,如果redis意外宕机了,最后一次修改数据就没有了
2. fork进程时,会占用一定的空间
AOF Append only file 将我们的所有命令都记录下来,history,恢复的时候一起恢复
默认是不开启的,需要手动开启,将appendonly 改成yes
如果aof配置文件错误,redis是启动不起来的,就需要使用redis-check-aof进行修复。
7. 扩展
7.1 redis是单线程的,为什么还那么快?
核心:redis的数据全部反正该内存中的,所以说单线程去操作效率就是最高的。多线程(CPU会上线文进行切换,耗时) ,对于内存系统用来说,如果没有上下文切换效率就是最高的。
redis是基于内存操作的,redis的瓶颈是根据机器的内存和网络带宽。
7.2 缓存穿透,缓存击穿,缓存雪崩的区别
缓存穿透:一直查询缓存redis里面没有的值,就只能去数据库mysql查询一个值。大量的请求,因为在缓存redis里查询不到,全部砸向数据库mysql,导致持久层的数据库很大的压力。解决方案:1. 布隆过滤器,2. 给缓存里查询不到的值->数据库查->数据库查询不到就在缓存里设置当前值为空值,这样下次在查询这个值的时候,缓存就会有对应的空值,不会再去数据库查询了。
缓存击穿:指的是一个key非常的热点,在不停的抗着大并发,并发集中对这一个点进行访问。解决方案:设置热点数据永不过其,加互斥锁(多个线程查询,只有一个线程能够获取到这个资源)。
缓存雪崩:指的是某一个时间段,缓存集中过期失效,redis宕机。全部的请求全部砸到数据库。
















 403
403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









