






1、遇到的问题:使用爬虫在爬取数据的时候,如果爬取的频率过快,或者是一些其它的原因,被对方网站识别出来是爬虫程序,这个时候我们的IP就会被面临封杀的危险,一旦IP被封了之后,我们的爬虫程序就无法去爬取该网站资源了。
2、如何解决?
使用代理IP
免费的ip网站 :推荐豌豆代理 ,每天20个免费的(但不一定都能用)
付费的ip网站:推荐快代理,价格便宜一些。
3、关于2个ip的说明
(1)内网ip:即我们在cmd里输入ipconfig 得到:
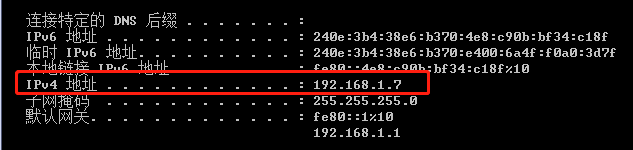
(2)外网ip:我们可以在网站http://httpbin.org/ip查看到:
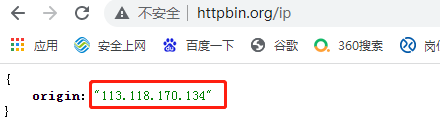
4、我们所说的是外网ip可能被封。

一、ip反爬
1、免费的代理ip


在上图中就有20个免费的代理ip,一个一个的试:

结果20个都不行。
2、付费的代理IP(https://www.kuaidaili.com/pricing/)

独享代理和私密代理需要该网站的登录用户名和密码
语法:proxies = {‘协议’:‘协议://用户名:密码@ip:端口号’}

(1)独享代理

结果:

(2)开放代理:


代码:

import requests
class Proxy:
def __init__(self):
self.proxy_url = 'http://dev.kdlapi.com/api/getproxy/?orderid=992520441312817&num=20&protocol=2&method=1&an_ha=1&sep=2'
self.test_url = 'https://www.baidu.com/'
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36'}
def get_proxy(self):
html = requests.get(url=self.proxy_url,headers=self.headers).text
proxy_list = html.split('\n')
for proxy in proxy_list:
self.text_proxy(proxy)
def text_proxy(self,proxy): # 测试开放代理是否可用
proxies = {
'http': '{}'.format(proxy),
'https': '{}'.format(proxy)}
try:
res = requests.get(url=self.test_url,proxies=proxies,headers=self.headers,timeout=2)
if res.status_code == 200:
print(proxy,'能用')
except Exception as e:
print(proxy,'不能用')
def main(self):
self.get_proxy()
if __name__ == '__main__':
spider = Proxy()
spider.main()
结果:

(3)私密代理:



import requests
class Proxy:
def __init__(self):
self.proxy_url = 'http://dps.kdlapi.com/api/getdps/?orderid=982520462433055&num=20&pt=1&sep=2'
self.test_url = 'https://www.baidu.com/'
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36'}
def get_proxy(self):
html = requests.get(url=self.proxy_url,headers=self.headers).text
proxy_list = html.split('\n')
for proxy in proxy_list:
self.text_proxy(proxy)
def text_proxy(self,proxy): # 测试开放代理
# 'http':'http://192149641:1ts5t50q@47.108.189.170:16816',账户名和密码
proxies = {
'http': 'http://192149641:1ts5t50q@{}'.format(proxy),
'https': 'https://192149641:1ts5t50q@{}'.format(proxy)}
try:
res = requests.get(url=self.test_url,proxies=proxies,headers=self.headers,timeout=2)
if res.status_code == 200:
print(proxy,'能用')
except Exception as e:
print(proxy,'不能用')
def main(self):
self.get_proxy()
if __name__ == '__main__':
spider = Proxy()
spider.main()
结果:















 219
219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









