







常用漏洞库:
佩奇漏洞文库:
https://www.yuque.com/peiqiwiki/peiqi-poc-wiki
http://wiki.peiqi.tech/
白阁漏洞文库:
https://wiki.bylibrary.cn/%E6%BC%8F%E6%B4%9E%E5%BA%93/01-CMS%E6%BC%8F%E6%B4%9E/ActiveMQ/ActiveMQ%E4%BB%BB%E6%84%8F%E6%96%87%E4%BB%B6%E4%B8%8A%E4%BC%A0%E6%BC%8F%E6%B4%9E/
狼组安全团队公开知识库:
https://wiki.wgpsec.org/knowledge/
Morker文库:
https://wiki.96.mk/
风炫漏洞库:
https://evalshell.com/
exploit-db漏洞库:
https://www.exploit-db.com/
批量探测网站存活状态
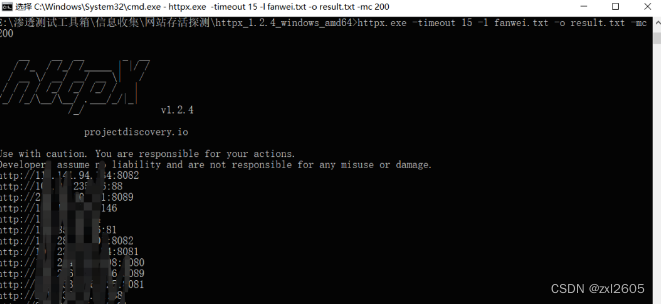
使用工具httpx对上面收集到的url做一个存活验证,首先筛选出存活的url来,然后再进行测试,不然会浪费我们很多时间,这里我们使用httpx把存活的url保存到文件中
httpx.exe -timeout 15 -l fanwei.txt -o result.txt -mc 200
域名和权重和公司的批量检测
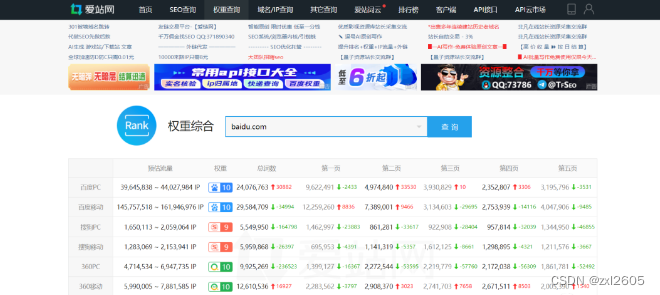
在提交补天或者其他漏洞平台的时候,可以发现平台会有提到这么一个提交漏洞的规则,那就是公益src的漏洞网站的主站权重需要达到指定的权重值才会收录,那么什么是权重值呢,网站权重是指搜索引擎给网站(包括网页)赋予一定的权威值,对网站(含网页)权威的评估评价。一个网站权重越高,在搜索引擎所占的份量越大,在搜索引擎排名就越好。补天的话是要百度移动权重大于等于1或者百度pc权重大于等于1,或者谷歌权重大于等于3,权重信息以爱站检测为准
爱站:https://rank.aizhan.com/
我们需要对上边收集过来的存在漏洞的url列表去做一个根据ip反查域名,然后域名反查权重这样一个功能,python大法好,学python得永生,这里使用python编写一个根据ip反查域名然后域名反查权重的功能。因为有些是ip站,要想查权重,就要查到ip所对应的域名,所以我们需要一个ip反查域名这么功能的ip反查脚本脚本:
#-- coding:UTF-8 --
import re, time
from urllib.parse import urlparse
import requests
from fake_useragent import UserAgent
from tqdm import tqdm
import os
# 爱站
def aizhan_chaxun(ip, ua):
aizhan_headers = {
'Host': 'dns.aizhan.com',
'User-Agent': ua.random,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://dns.aizhan.com/'}
aizhan_url = 'https://dns.aizhan.com/' + str(ip) + '/'
try:
aizhan_r = requests.get(url=aizhan_url, headers=aizhan_headers, timeout=2).text
aizhan_nums = re.findall(r'''<span class="red">(.*?)</span>''', aizhan_r)
if int(aizhan_nums[0]) > 0:
aizhan_domains = re.findall(r'''rel="nofollow" target="_blank">(.*?)</a>''', aizhan_r)
return aizhan_domains
except:
pass
def catch_result(i):
ua_header = UserAgent()
i = i.strip()
if "http://" not in i:
i="http://"+i
try:
ip = urlparse(i).netloc
aizhan_result = aizhan_chaxun(ip, ua_header)
time.sleep(1)
if (aizhan_result != None ):
with open("ip反查结果.txt", 'a') as f:
result = "[url]:" + i + " " + " [aizhan]:" + str(aizhan_result[0])
print(result)
f.write(result + "\n")
else:
with open("反查失败列表.txt", 'a') as f:
f.write(i + "\n")
except:
pass
if __name__ == '__main__':
url_list = open("待ip反查.txt", 'r').readlines()
url_len = len(open("待ip反查.txt", 'r').readlines())
#每次启动时清空两个txt文件
if os.path.exists("反查失败列表.txt"):
f = open("反查失败列表.txt", 'w')
f.truncate()
if os.path.exists("ip反查结果.txt"):
f = open("ip反查结果.txt", 'w')
f.truncate()
for i in tqdm(url_list):
catch_result(i)
将前边收集到的存在漏洞的url存到一个叫待ip反查.txt的文件里,然后运行脚本
运行结果:

然后拿到解析的域名后,继续对域名权重进行检测,这里采用爱站来进行权重检测,这里是一个批量检测权重的脚本
# -- coding:UTF-8 --
import requests
import re
import getopt
import sys
import threadpool
import urllib.parse
import urllib.request
import ssl
from urllib.error import HTTPError,URLError
import time
ssl._create_default_https_context = ssl._create_stdlib_context
headers={
'Host': 'baidurank.aizhan.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36',
'Sec-Fetch-Dest': 'document',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Cookie': ''
}
def google_simple(url, j):
google_pc = "https://pr.aizhan.com/{}/".format(url)
bz = 0
http_or_find = 0
try:
response = requests.get(google_pc, timeout=10).text
http_or_find = 1
result_pc = re.findall(re.compile(r'<span>谷歌PR:</span><a>(.*?)/></a>'), response)[0]
result_num = result_pc.split('alt="')[1].split('"')[0].strip()
if int(result_num) > 0:
bz = 1
result = '[+] 谷歌权重:' + result_num + ' ' + j
return result, bz
except:
if (http_or_find != 0):
result = "[!]格式错误:" + "j"
return result, bz
else:
time.sleep(3)
return google_simple(url, j)
def getPc(domain):
aizhan_pc = 'https://baidurank.aizhan.com/api/br?domain={}&style=text'.format(domain)
try:
req = urllib.request.Request(aizhan_pc, headers=headers)
response = urllib.request.urlopen(req,timeout=10)
b = response.read()
a = b.decode("utf8")
result_pc = re.findall(re.compile(r'>(.*?)</a>'),a)
pc = result_pc[0]
except HTTPError as u:
time.sleep(3)
return getPc(domain)
return pc
def getMobile(domain):
aizhan_pc = 'https://baidurank.aizhan.com/api/mbr?domain={}&style=text'.format(domain)
try:
# b = requests.post(url=post_url,headers=headers, proxies=proxy, timeout = 7)
# res = urllib.request.urlopen(aizhan_pc,timeout=10)
# # res = opener.open(aizhan_pc,timeout=10)
# a = res.read().decode('UTF-8')
req = urllib.request.Request(aizhan_pc, headers=headers)
response = urllib.request.urlopen(req,timeout=10)
b = response.read()
a = b.decode("utf8")
result_m = re.findall(re.compile(r'>(.*?)</a>'),a)
mobile = result_m[0]
except HTTPError as u:
time.sleep(3)
return getMobile(domain)
return mobile
# 权重查询
def seo(name,url):
try:
result_pc = getPc(name)
result_mobile = getMobile(name)
except Exception as u:
# print(u)
result_pc = '0'
result_mobile = '0'
print('[- 目标{}获取权重失败,自动设为0'.format(url))
# print('运行正常')
print('[+ 百度权重:'+result_pc+' 移动权重:'+result_mobile+' Url:'+url)
with open('vul.txt','a',encoding='utf-8') as y:
y.write('[百度权重:'+result_pc+','+"移动权重:"+result_mobile+','+url+']'+'\n')
return True
def exp(name1):
# opts, args = getopt.getopt(sys.argv[1:], '-u:-r:', ['url', 'read'])
# print(name1)
try:
name = name1[name1.rfind('/'):].strip('/')
# print(name)
rew = seo(name,name1)
except Exception as u:
# except:
print(u)
print('[- 目标{}检测失败,已写入fail.txt等待重新检测'.format(name1))
# file_fail.write(name1+'\n')
with open('fail.txt',mode='a',encoding='utf-8') as o:
o.write(name1+'\n')
def multithreading(funcname, params=[], filename="ip.txt", pools=15):
works = []
with open(filename, "r") as f:
for i in f:
func_params = [i.rstrip("\n")] + params
works.append((func_params, None))
pool = threadpool.ThreadPool(pools)
reqs = threadpool.makeRequests(funcname, works)
[pool.putRequest(req) for req in reqs]
pool.wait()
def main():
multithreading(exp, [], "存在漏洞的url.txt", 15) # 默认15线程
print("全部check完毕,请查看当前目录下的vul.txt")
if __name__ == "__main__":
# st = False
# main(st)
main()
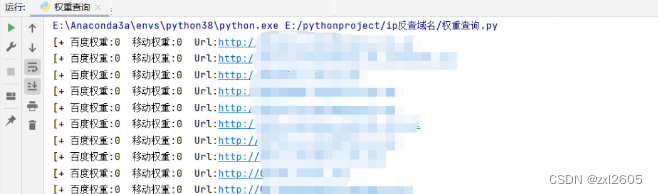
结果:

然后拿着有权重的站,批量根据域名反查备案名称,这里推荐使用一个工具叫ip2domain,该工具可用于对跑到的ip批量查询域名及百度权重、备案信息,快速确定ip所属企业,方便提交漏洞。
工具链接:https://github.com/Sma11New/ip2domain
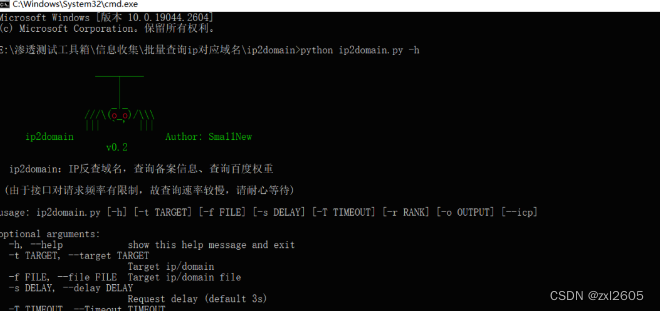
然后批量查询域名的备案公司
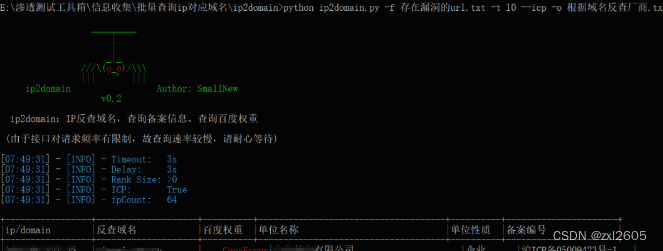
python ip2domain.py -f 存在漏洞的url.txt -t 10 --icp -o 根据域名反查厂商.txt
参数解析:-f 是指定批量查询的文件 -o是查询后的结果保存的文件名 -t是超时时间 --icp是查询网站对应的备案公司名
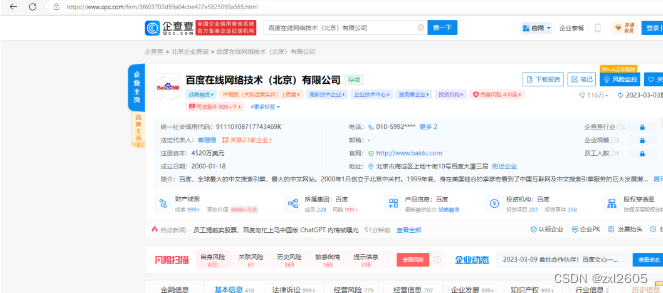
企查查:
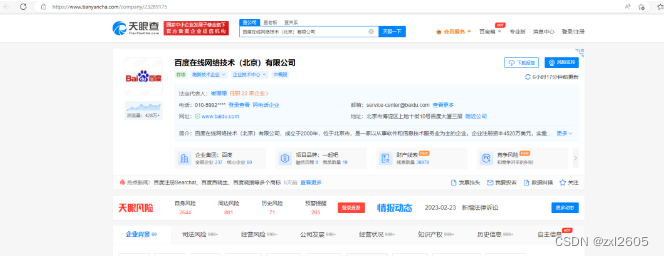
天眼查:


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









