



in 后面是跟具体的值
exists 在后面的子查询中 只返回true or false 即查询到数据返回true 没有查询到数据返回false 因此这里的select 可以是任何字段 1 或者 a z或者 。。。。。 select null 是等于true
在效率上 in 比 exists 要快 in 更高效
在执行顺序上,In 和 exists 不一样
in后面的子查询先产生结果集,然后主查询再去结果集里面去找符合要求的字段,符合要求的输出。
select *
from stu
where sex='男'
and age in (select age
from stu
where sex='女')
not in :主查询时表大,子查询中的表小 用not In 。执行顺序 是表中一条一条记录的去匹配,不走索引。
not exists 的执行顺序 在表中查询是根据索引去查询,找到就返回true ,不会每条记录都去查询
not exists查询效率比not In 高很多
查询哪些班级没有学生
select *
from class
where cid not in (select
distinct cid
from stu
)
当表中cid存在Null值时,not in 不对其进行处理
优化:
select *
from class
where cid not in (select
distinct cid
from stu
where cid is not null
)
查询哪些班级中没有学生
select *
from class2
where not exists (select
*
from stu1
where stu1.cid= class2.cid)
not exists的执行顺序 在表中查询是根据索引去查询,找到就返回true ,不会每条记录都去查询
not exists查询效率比not In 高很多
转载
https://www.cnblogs.com/qlqwjy/p/8598091.html
实例 1
实例 2
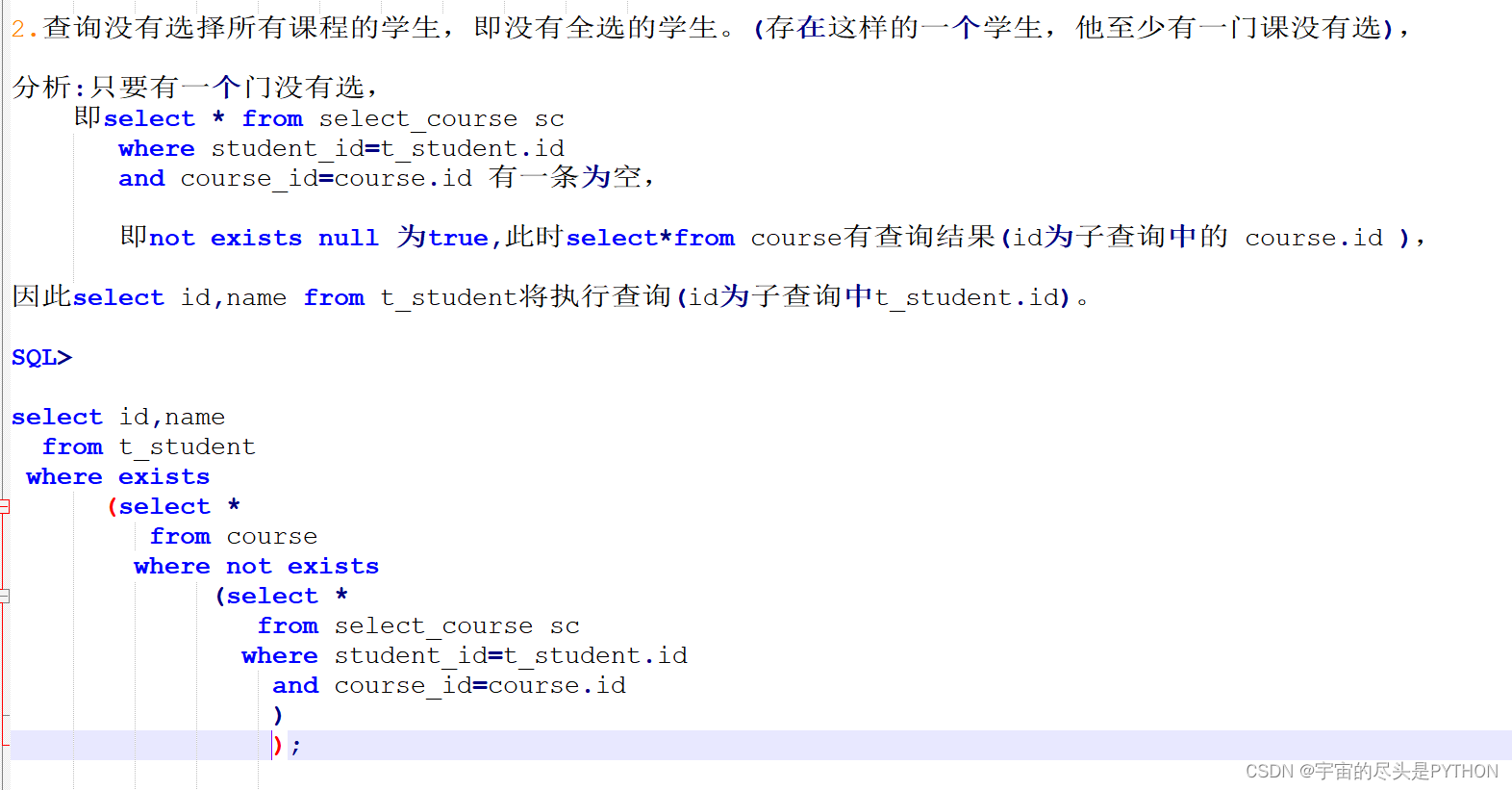
实例 3
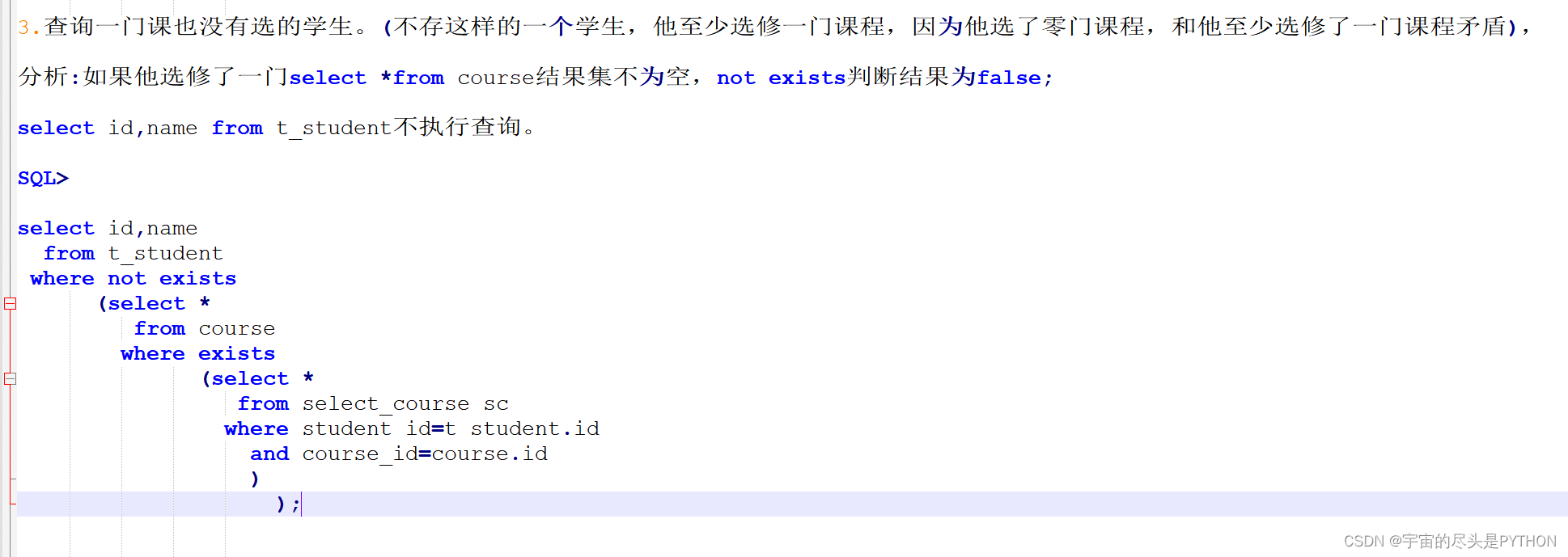
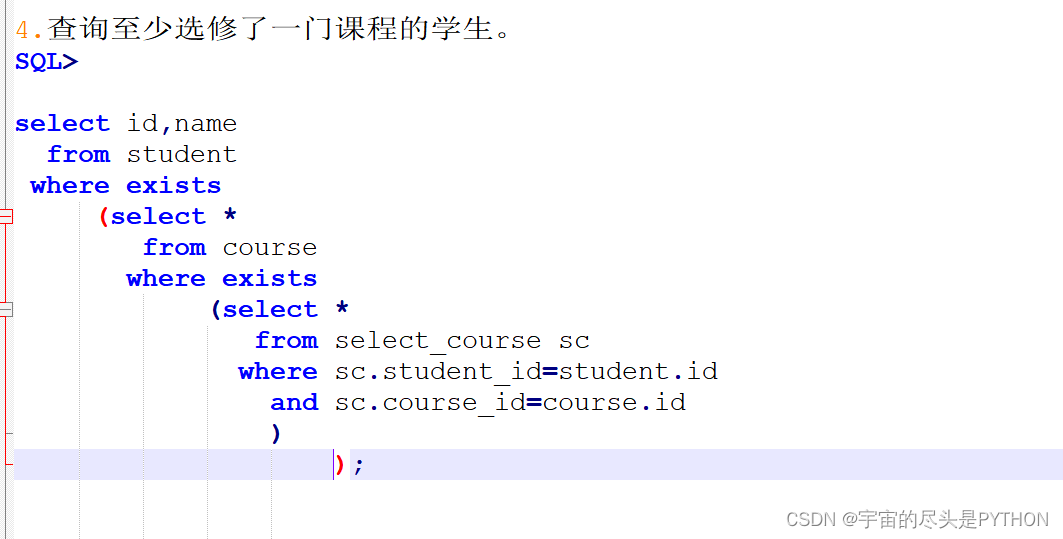
口诀
1 全部选了 用双重否定表示肯定 not exists not exists
2 没有全部选,先exists, 后 not exists
3 什么都没选 先not exists , 后exists
4 至少选择了一个 ,两个exists
参考文献
https://blog.csdn.net/daobuxinzi/article/details/124617622

















 1170
1170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









