







最近在挣扎数据结构的树部分,看到哈夫曼树的一个引子是先统计字母频数再建立带权路径长度最小的树,希望以后能开辟数据结构的专栏。先整理了一下python里用字典统计字母出现的次数的内容。
1、首先读取一个文本(txt)文件。
path=r"D:\A USTC\lesson\English\presentation\presentation.txt"
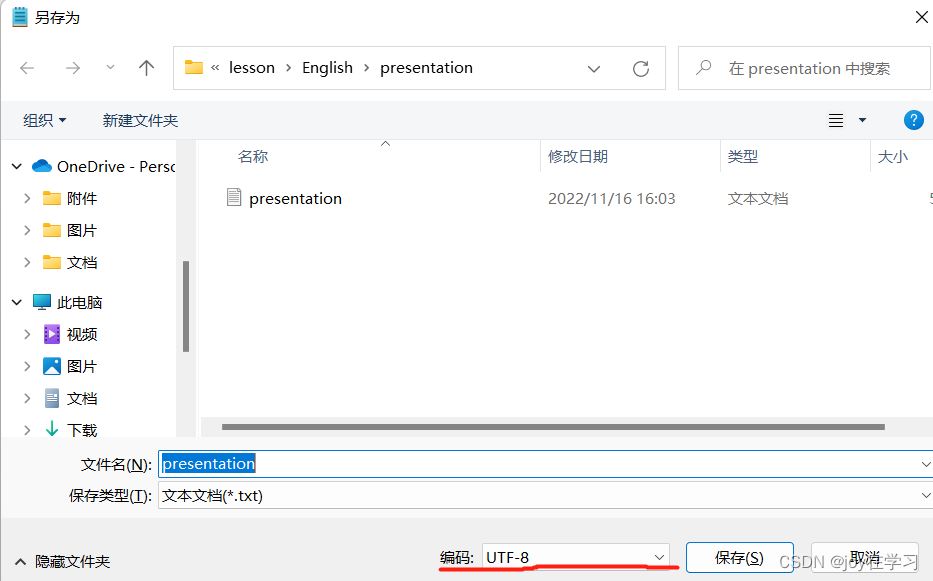
f=open(path,encoding='utf-8')在这里读取的时候出现了‘gbk‘ codec can‘t decode byte 0xbf in position 2: illegal multibyte sequence”报错,为了快速解决这个问题,我直接把原来txt文件另存了一份utf-8编码格式,并用encoding='utf-8'打开,如下图,另存之后重新运行代码即可。
2、读取文本并存为字符串类型,如下:
text_file=f.read()#读取目标文本转化成字符串类型
type(text_file)#查看类型为str3、利用字典的键和值来统计字母出现次数
#利用字典进行统计,v遍历字符串text_file作为键,不断增加值
cnt = {}
for v in text_file:
if v in cnt:#如果遍历到该字符
cnt[v] += 1#则对应位置的值+1
else:
cnt[v] = 1#第一次遍历对应位置时赋值为1
print(cnt)得到结果如下:

为了进一步查看,对字典的cnt.items()按值进行排序,得到一个列表
cnt_sort=sorted(cnt.items(), key=lambda x:x[1],reverse=True)
这里使用匿名函数将字典的值作为key进行排序。
print(cnt_sort)查看排序后的列表结果。
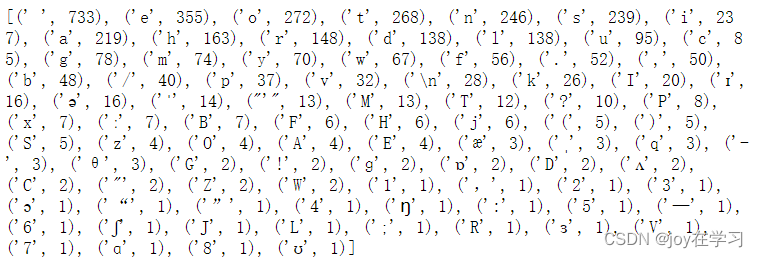
也可以用切片查看字符出现次数排名前十的列表:print(cnt_sort[:10])
![]()















 1662
1662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









