






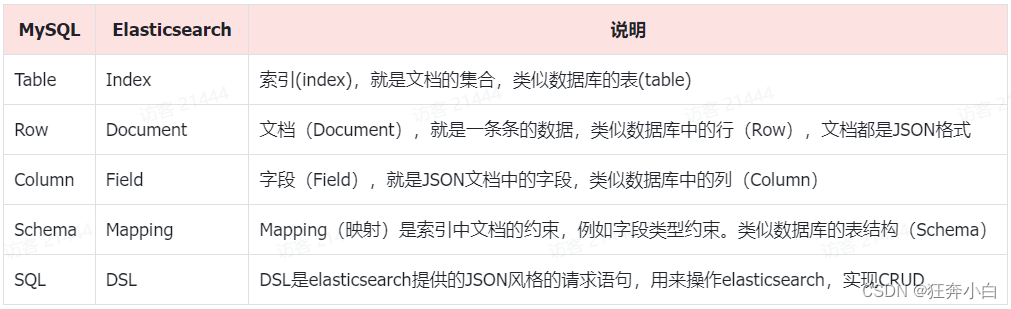
基本概念
对比mysql数据库来理解
导入依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>对索引库进行增删查操作(可以理解为创建数据库的表)
!!!
注意:
一定要查看引入依赖的版本问题,springboot默认的是7.17.10记得改成自己所使用的版本
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://IP:PORT")
));
// 就是说创建一张表
// =========================创建索引=================================
// 创建request对象
CreateIndexRequest request = new CreateIndexRequest("indexName");
// 准备请求参数
request.source("datasource",XContentType.JSON);
// 发送请求
client.indices().create(request,RequestOptions.DEFAULT);
// =========================删除索引=================================
// 1.创建Request对象
DeleteIndexRequest request = new DeleteIndexRequest("indexName");
// 2.发送请求
client.indices().delete(request, RequestOptions.DEFAULT);
// =========================判断索引是否存在=================================
// 1.创建Request对象
GetIndexRequest request = new GetIndexRequest("indexName");
// 2.发送请求
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
// 3.输出
System.err.println(exists ? "索引库已经存在!" : "索引库不存在!");// 上面创建索引库用到的数据源
String datasource="{
"mappings": {
"properties": {
"字段名1":{
"type": "text", // 类型
"analyzer": "ik_smart" // 分词器
},
"字段名2":{
"type": "keyword",
"index": "false" //是否加入索引(默认加入)
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
}
}
}
}"索引库操作的基本步骤:
-
初始化
RestHighLevelClient -
创建XXXIndexRequest。XXX是
Create、Get、Delete -
准备请求参数(
Create时需要,其它是无参,可以省略) -
发送请求。调用
RestHighLevelClient.indices().xxx()方法,xxx是create、exists、delete
对文档进行增删改(可以理解为操作表数据)
//=======================新增文档================================
// 1.准备Request对象
IndexRequest request = new IndexRequest("索引库名字").id("文档的id");
// 2.准备Json文档
request.source("文档数据(json格式)", XContentType.JSON);
// 3.发送请求
client.index(request, RequestOptions.DEFAULT);
//=======================查询文档================================
// 1.准备Request对象
GetRequest request = new GetRequest("索引库名字").id("文档的id");
// 2.发送请求
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 3.获取响应结果中的source
String json = response.getSourceAsString();
//=======================删除文档================================
// 1.准备Request,两个参数,第一个是索引库名,第二个是文档id
DeleteRequest request = new DeleteRequest("索引库名字", "文档的id");
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
//=======================修改文档================================
// 1.准备Request
UpdateRequest request = new UpdateRequest("索引库名字", "文档的id");
// 2.准备请求参数
request.doc(
"key1", value1,
"key2", value2
);
// 3.发送请求
client.update(request, RequestOptions.DEFAULT);
//=======================批量操作文档数据================================
// 1.创建Request
BulkRequest request = new BulkRequest();
// 2.准备请求参数
request.add(new IndexRequest("索引库名字").id("文档的id").source("json doc1", XContentType.JSON));
request.add(new IndexRequest("索引库名字").id("文档的id").source("json doc2", XContentType.JSON));
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
文档操作的基本步骤:
-
初始化
RestHighLevelClient -
创建XXXRequest。 XXX是
Index、Get、Update、Delete、Bulk -
准备参数(
Index、Update、Bulk时需要) -
发送请求。调用
RestHighLevelClient#.xxx()方法,xxx是index、get、update、delete、bulk -
解析结果(
Get时需要)
DSL查询 (Domain Specific Language)
叶子查询
// 叶子查询
- 全文检索查询(Full Text Queries):利用分词器对用户输入搜索条件先分词,得到词条,然后再利用倒排索引搜索词条。例如:
- match:
- multi_match
- 精确查询(Term-level queries):不对用户输入搜索条件分词,根据字段内容精确值匹配。但只能查找keyword、数值、日期、boolean类型的字段。例如:
- ids
- term
- range
- 地理坐标查询:用于搜索地理位置,搜索方式很多,例如:
- geo_bounding_box:按矩形搜索
- geo_distance:按点和半径搜索
// 代码示例
// 1.创建Request
SearchRequest request = new SearchRequest("索引库");
// 2.构建查询条件
// 2.1 match查询:
request.source().query(QueryBuilders.matchQuery("字段名", "查询参数"));
// 2.2 multi_match查询:
request.source().query(QueryBuilders.multiMatchQuery("查询参数", "字段名1", "字段名2"));
// 2.3 range查询:
request.source().query(QueryBuilders.rangeQuery("字段名").gte(10000).lte(30000));
// 2.3 term查询:
request.source().query(QueryBuilders.termQuery("字段名", "查询参数"));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);复合查询
// 复合查询
//- 第一类:基于逻辑运算组合叶子查询,实现组合条件,例如
//- bool
//- 第二类:基于某种算法修改查询时的文档相关性算分,从而改变文档排名。例如:
//- function_score
//- dis_max
// 1.创建Request
SearchRequest request = new SearchRequest("items");
// 2.组织请求参数
// 2.1.准备bool查询
BoolQueryBuilder bool = QueryBuilders.boolQuery();
// 2.2.关键字搜索
bool.must(QueryBuilders.matchQuery("字段名", "查询关键词"));
// 2.3.过滤
bool.filter(QueryBuilders.termQuery("字段名", "过滤关键词"));
// 2.4.过滤
bool.filter(QueryBuilders.rangeQuery("字段名").lte(30000));
request.source().query(bool);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
排序和分页
//排序和分页
int pageNo = 1, pageSize = 5;
// 1.创建Request
SearchRequest request = new SearchRequest("索引库");
// 2.组织请求参数
// 2.1.搜索条件参数
request.source().query(QueryBuilders.matchQuery("字段名", "查询关键词"));
// 2.2.排序参数
request.source().sort("字段名", SortOrder.ASC);
// 2.3.分页参数
request.source().from((pageNo - 1) * pageSize).size(pageSize);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);高亮显示
// 字段高亮显示
// 1.创建Request
SearchRequest request = new SearchRequest("索引库");
// 2.组织请求参数
// 2.1.query条件
request.source().query(QueryBuilders.matchQuery("字段名", "查询关键字"));
// 2.2.高亮条件
request.source().highlighter(
SearchSourceBuilder.highlight()
.field("字段名")
.preTags("<em>")
.postTags("</em>")
);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
SearchHits searchHits = response.getHits();
// 1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
// 2.遍历结果数组
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
// 3.得到_source,也就是原始json文档
String source = hit.getSourceAsString();
// 4.反序列化(换成你自己的实体类)
ItemDoc item = JSONUtil.toBean(source, ItemDoc.class);
// 5.获取高亮结果
Map<String, HighlightField> hfs = hit.getHighlightFields();
if (CollUtils.isNotEmpty(hfs)) {
StringBuilder sb=new StringBuilder();
// 5.1.有高亮结果,获取name的高亮结果
HighlightField hf = hfs.get("字段名");
if (hf != null) {
Text[] texts = hf.getFragments();
// 5.2.获取第一个高亮结果片段,就是商品名称的高亮值
for (int i = 0; i < texts.length; i++) {
sb.append(texts[i].string());
}
item.setName(sb.toString());
}
}
System.out.println(item);
}聚合函数
聚合常见的有三类:
-
桶(
Bucket)聚合:用来对文档做分组-
TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组 -
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
-
度量(
Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等-
Avg:求平均值 -
Max:求最大值 -
Min:求最小值 -
Stats:同时求max、min、avg、sum等
-
-
管道(
pipeline)聚合:其它聚合的结果为基础做进一步运算
注意:参加聚合的字段必须是keyword、日期、数值、布尔类型
代码示例:
//聚合函数
// 1.创建Request
SearchRequest request = new SearchRequest("索引库");
// 2.准备请求参数
BoolQueryBuilder bool = QueryBuilders.boolQuery()
.filter(QueryBuilders.termQuery("字段名", "查询关键字"))
.filter(QueryBuilders.rangeQuery("字段名").gte(范围值));
// size(0)不返回查询到的文档,只返回聚合结果
request.source().query(bool).size(0);
// 3.聚合参数
request.source().aggregation(
//terms表示聚合类型
AggregationBuilders.terms("聚合名称(自定义)").field("字段名").size(5)
);
// 4.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 5.解析聚合结果
Aggregations aggregations = response.getAggregations();
// 5.1.获取品牌聚合
// 根据所需的聚合分类进行接收,这里是Terms
Terms brandTerms = aggregations.get("聚合名称(自定义)");
// 5.2.获取聚合中的桶
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
// 5.3.遍历桶内数据
for (Terms.Bucket bucket : buckets) {
// 5.4.获取桶内key
String brand = bucket.getKeyAsString();
System.out.print("brand = " + brand);
long count = bucket.getDocCount();
System.out.println("; count = " + count);
}
}面对海量数据搜索,或者是一些复杂的搜索需求的时候,使用搜索引擎技术Elasticsearch可以大大提升搜索性能(现在用不上不代表以后用不上,梦想总是要有的 ( ̄︶ ̄))
完结:至此CRUD大法已成!
❀❀❀















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









