







文章目录
第二章 应用层
一、应用层协议原理
1.网络应用的体系结构
- C/S模式(客户-服务器模式)
- 对等模式:P2P(peer to peer)
- 混合体:上面两种模式的混合体
1.1 客户-服务器(C/S)体系结构
- 服务器
服务器一直在运行,固定的IP和端口号,数据中心进行扩展
- 客户端
主动与服务器进行通信,与互联网有间歇性连接,可以是动态的IP地址,不直接与其他客户端通信
- 缺点
当客户端达到一定数量时,服务器性能出现断崖式下降,因为可扩展性差
1.2 对等体(P2P)体系结构
就记住一点,即每个结点都可以作为客户端或服务器,任意端系统可以通信,扩展性大大增大。例如迅雷、百度云都是此原理
1.3 混合体
使用两种结构分门别类的进行:
对于文件搜索我们可以集中在服务器中进行维护,而对于文件传输就可以依靠各个结点来传输;
又或者对于及时通信,在线监测可以集中在服务器,而两个用户之间聊天就直接可以进行P2P模式来传输
2.进程通信
- 对于本地的进程
在本地的各种进程,是可以通过操作系统提供的管道,共享缓冲区等方式进行通信
- 对于进程处于不同的主机
这时的进程就要靠操作系统提供的网络进行通信,并且要遵循一定的协议才可以
2.1 分布式进程之间的通信
- 注意:在看此节之前,应先阅读第三节关于socket的讲解
分布式进程需要解决的三个问题:
- 进程标示和寻址问题(服务用户)
- 传输层-应用层提供服务是如何(服务)
通过SAP知道位置,然后通过SAP的API(TCP/IP :socket API)确定形式
- 如何使用传输层提供的服务,实现应用进程之间的报文交换,实现应用(用户使用服务)
这时就要定义应用层的协议,报文格式,解释,时序等
2.2 问题一:对进程进行编址(addressing)
一个进程用IP(区别主机)+port(区别进程)标识端结点,本质来说进程之间的交互就是两个端结点构成的
2.3 问题二:传输层提供的服务-需要穿过层间的信息、信息的代表、信息的代码
- 层间接口必须携带的信息
发送数据本体(SDU),发送者即由谁发来的(IP+PORT),接收方即发给谁(IP+PORT)
- 将这些信息通过socket封装起来
如果每次发送这么发要携带除了数据本体还要这么多信息,就十分臃肿了,所以主机会在本地创建一个socket标识(TCP协议下)用于保存:
(源IP,源端口,目标IP,目标端口),简称四元组(是一个整数),这样穿过层间接口的信息量就是最小的了(但注意到传输层依然会把这些信息加上去,我们只是减轻了层间传输的信息量),这个标识是应用层和传输层之间的约定
2.4 问题三:如何使用传输层提供的服务实现应用
- 定义应用层协议:报文格式,解释,时序等
- 编制程序,通过API调用网络基础设施提供通信服务传报文,解析报文,实现应用时序等
3.socket(传输层提供给应用层的服务)
3.1 TCP(面向连接的协议)之上的套接字
对于使用面向连接服务(TCP)的应用而言,套接字是4元组的一个具有本地意义的标示
- 4元组:
(源IP,源port,目标IP,目标port) - 唯一的指定了一个会话(2个进程之间的会话关系)
- 应用使用这个标示,与远程的应用进程通信
- 不必在每一个报文的发送都要指定这4元组
- 就像使用操作系统打开一个文件,OS返回一个文件句柄一样,以后使用这个文件句柄,而不是使用这个文件的目录名、文件名
- 简单,便于管理
3.1.1 操作系统之socket
需要在本地维护如下图所示的一张表


3.2 UDP(无连接的协议)之上的套接字
对于使用无连接服务(UDP)的应用而言,套接字是2元组的一个具有本地意义的标示
- 2元组:
(IP,port (源端指定)) - UDP套接字指定了应用所在的一个端节点(end point)
- 在发送数据报时,采用创建好的本地套接字(标示ID),就不必在发送每个报文中指明自己所采用的ip和port
- 但是在发送报文时,必须要指定对方的ip和UDP port(另外一个段节点),注意没有发自己的端口号哦,这就是个TCP很大的区别了,也就是说UDP只维护了接收结点的会话。
举个生动的例子,就是寄快递我们没有写发货地址,对方也不知道
3.2.1 操作系统之socket

4.协议
运行在不同端系统上的应用进程如何相互交换报文,交换的报文类型:请求和应答报文、各种报文类型的语法:报文中的各个字段及其描述 、字段的语义:即字段取值的含义 、进程何时、如何发送
5.应用需要传输层提供什么样的服务

5.1 常见应用对传输服务的要求

5.2 Internet应用及其应用层协议和传输协议

6.Internet 传输层提供的服务
6.1 TCP服务(对于端系统面向连接的服务)
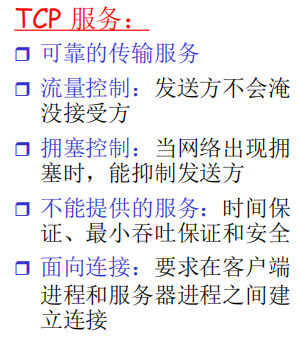
6.2 UDP服务(无连接的服务)

6.2.1 UDP存在的理由
- 能够区分不同的进程,而IP服务不能
在IP提供的主机到主机端到端功能的基础上,区分了主机的应用进程(因为有端口号)
- 无需建立连接,省去了建立连接时间,适合事务性的应用
- 不做可靠性的工作,例如检错重发,适合那些对实时性要求比较高而对正确性要求不高的应用
因为为了实现可靠性(准确性、保序等),必须付出时间代价(检错重发)
- 没有拥塞控制和流量控制,应用能够按照设定的速度发送数据
而在TCP上面的应用,应用发送数据的速度和主机向网络发送的实际速度是不一致的,因为有流量控制和拥塞控制
6.3 TCP&UDP
- 两者的共性
都没有进行加密、明文通过互联网传输,包括密码
- 增加安全性的方式
在TCP之上实现SSL提供加密的TCP连接,应用通过API将明文交给socket,SSL将其加密在互联网上传输,举例当你的网址上面的HTTP是HTTPS时,这个web应用就是跑在被SSL修饰的TCP之上,浏览器和服务器之间的通信就是安全的(读者注意这里的安全与TCP协议的可靠性是两个概念,切勿搞混)
二、Web和HTTP
URL(通用资源定位符)格式:我们通过URL来进行对每个对象的引用访问

1.HTTP概述
1.1 概述
HTTP(超文本传输协议),是Web的应用层协议,基于TCP的传输协议上,采用的传输模式是:客户/服务器模式;
客户:请求、接受和显示Web对象的浏览器
服务器:对请求进行响应,发送对象的Web服务器

1.2 大致连接过程
- 客户发起一个与服务器的TCP连接(建立套接字),端口号为80
- 服务器接受客户的TCP连接
- 在浏览器(HTTP客户端)与Web服务器(HTTP服务器server)交换HTTP报文(应用层协议报文)
在浏览器上接收到响应报文,然后就会解析里面的HTML在页面进行显示
- TCP连接关闭
HTTP是无状态的,服务器并不维护关于客户的任何信息
TCP主机服务器默认维护80端口,并有一个socket作为守护socket等待请求指向本身;如果有新的客户进行请求,则会在服务器上专门在建立一个socket来维护这个连接关系,每一个新的请求亦是同理。服务器维护着请求的资源对象,这些对象通过链接可能又连接着别的服务器的对象,然后通过一系列的请求响应把页面展示出来
2.HTTP连接
2.1 非持久化HTTP(HTTP1.0默认使用)
- 最多只有一个对象在TCP连接上发送
- 下教多个对象需要多个TCP连接
TCP建立连接(往返,返回的是TCP连接建立完成的信息)、HTTP建立连接(往返)、TCP断开连接


2.1.1 缺点
- 每个对象要2个RTT
- 操作系统必须为每个TCP连接分配资源
- 但浏览器通常打开并行TCP连接,以获取引用对象
2.2 持久化HTTP
- 多个对象可以在一个(在客户端和服务器之间的)TCP连接上传输
就是在非持久化HTTP中,当HTTP请求响应完成后不断开TCP连接
2.2.1 非流水式持久化HTTP
- 客户端只能在收到前一个响应后才能发出新的请求
- 每个引用对象花费一个RTT
2.2.2 流水式持久化HTTP(HTTP1.1默认使用)
- 客户端遇到一个引用对象就立即产生一个请求
- 所有引用(小)对象只花费一个RTT是可能的
3.HTTP报文
3.1 概述
- 两种类型
请求、响应
- HTTP请求报文

- HTTP响应报文
这里解释一下
content-length的意思,就是在服务器向TCP协议提交请求所需的对象数据时,可能是进行分段处理的,但在客户端接收时TCP是直接将报文合并起来一起响应给用户(即TCP是无边界的),这时就需要应用层自己去识别分段,信息的边界。
在解释一下last-modified的意思,就是当使用代理服务器缓存了一定数量的对象时,当源服务器中的这些对象更改时,这个标志位就起到了作用,如果你在我请求的时间已经发生更改那么就要在源服务器重发一份数据;如果在请求的时间没有更改那么直接再去代理服务器获取就好

- HTTP通用格式

- 方法类型

3.2 提交表单输入
- Post方式
- 网页通常包括表单输入
- 包含在实体主体(entity body )中的输入被提交到服务器
- URL方式
方法:GET;输入通过请求行的URL字段上载

3.3 HTTP响应状态码
- 一些例子

4.用户-服务器状态: cookies
前面我们提到HTTP是无状态的协议,服务器并不维护关于客户的任何信息。那么技术日新月异,客户的需求也日渐复杂,就会出现很多需要服务器维护用户状态的情况,例如:用户短时间登录不需要二次登录,购物车的信息不会被清空等等;这时我们就引入cookie来解决这个问题,我们可以简单的理解为cookie就是服务器给我们存的一份身份证,来分辨谁是谁
- 例子:

4.1 cookie的组成部分
- 在HTTP响应报文中有一个cookie的首部行
- 在HTTP请求报文含有一个cookie的首部行
- 在用户端系统中保留有一个cookie文件,由用户的浏览器管理
- 在Web站点有一个后端数据库
4.2 cookie的作用
- 用户验证
- 购物车
- 推荐
- 用户状态(Web e-mail)
4.3 简单提一嘴隐私

5.Web缓存(代理服务器)
作用:不访问原始服务器,就满足客户的请求
5.1 概述
- 用户设置浏览器:通过缓存访问Web
- 浏览器将所有的HTTP请求发给缓存
在缓存中的对象:缓存直接返回对象;如对象不在缓存,缓存请求原始服务器,然后再将对象返回给客户端。还是Cache那一套
- 缓存既是客户端又是服务器
- 通常缓存是由工SP安装(大学、公司、居民区工SP)
5.2 为什么要使用web缓存
- 降低客户端的请求响应时间
- 可以大大减少一个机构内部网络与Internent接入链路上的流量
- 互联网大量采用了缓存:可以使较弱的工CP也能够有效提供内容
三、FTP(文件传输协议)
1.概述图

2.连接过程
- FTP客户端与FTP服务器通过端口21联系,并使用TCP为传输协议
- 客户端通过控制连接获得身份确认
- 客户湍通过控制连接发送命令浏览远程目录
- 收到一个文件传输命令时,服务器打开一个到客户端的数据连接
- 一个文件传输完成后,服务器关闭连接
- 服务器打开第二个TCP数据连接用来传输另一个文件,这个连接被我们称为
带内,传数据 - 控制连接:
带外(“ out of band")传送,带外 传指令、控制信息 - FTP服务器维护用户的状态信息:当前路径、用户帐户与控制连接对应
- 有状态协议
3.FTP命令、响应

四、Email
- 简述一下发送邮件和收取邮件的过程
用户通过用户代理发送给响应邮件服务器,邮件服务器用过地址选取对应目标邮件服务器,这个过程是SMTP支持的,称为推
用户收取别人发送的邮件,用户代理通过HTTP查看对应邮件服务器是否有用户的邮件

1.三大组成部分
- 用户代理
- 邮件服务器
- 简单邮件传输协议:SMTP
1.1 用户代理
可以类比成你在HTTP的代理是浏览器,你在FTP的代理是FTP客户端软件
- 又名 “ 邮件阅读器 ”
- 撰写、编辑和阅读邮件
- 如Outlook、Foxmail
- 输出和输入邮件保存在服务器上
1.2 邮件服务器
- 邮箱中管理和维护发送给用户的邮件
- 输出报文队列保持待发送邮件报文
- 邮件服务器之间的SMTP协议:发送email报文
客户:发送方邮件服务器
服务器:接收端邮件服务器
1.3 SMTP
从图中可以看到就是原始SMTP协议只允许发送ASCII编码,那如果我们需要发送的媒体格式十分多样怎么办,这时我们就可以对这个协议进行扩展,即多媒体扩展(我们要发送中文就要使用Base64来对ASCII进行扩展,将若干个不在ASCII范围内的字节表达成更长一点在ASCII范围内的字符)

2.过程例子

3.邮件访问协议

五、DNS(Domain Name System:域名解析系统)
缓存是为了性能,删除是为了一致性,DNS的安全性可靠
1.DNS的必要性
-
IP地址标识主机、路由器,但IP地址不好记忆,不便人类使用(没有意义)
-
人类一般倾向于使用一些有意义的字符串来标识工nternet上的设备
列如:qzheng@ustc.edu.cn所在的邮件服务器
www.ustc.edu.cn所在的web服务器 -
存在着“字符串”—IP地址的转换的必要性
-
人类用户提供要访问机器的“字符串”名称
-
由DNS负责转换成为二进制的网络地址
根据必要性我们提出了DNS必须解决的三个问题
- 如何命名设备
用有意义的字符串:好记,便于人类用使用;解决一个平面命名的重名问题:层次化命名
- 如何完成名字到IP地址的转换
分布式的数据库维护和响应名字查询
- 如何维护:增加或者删除一个域,需要在域名系统中做哪些工作
2.DNS的思路和目的
2.1 主要思路
- 分层的、基于域的命名机制
- 若干分布式的数据库完成名字到IP地址的转换
- 运行在UDP之上端口号为53的应用服务
- 核心的Internet功能,但以应用层协议实现
在网络边缘处理复杂性
2.2 目的
- 实现主机名-IP地址的转换(name/IP translate)
- 其它目的
- 主机别名到规范名字的转换:Host aliasing
- 邮件服务器别名到邮件服务器的正规名字的转换: Mail server aliasing
- 负载均衡:Load Distriblution
3.DNS的命名空间
!!注意当我们再说域名的层次结构,是从前往后说,并且前面的是所属于后面的域名之下,可以理解为倒着生长的一棵树,一个根域下面有很多子域,子域下面有很多的域名,一级域名、二级域名等;例如:
中国教育网的域名为:edu.cn;中国的域名为:cn

3.1 名字结构
- 一个层面命名设备会有很多重名
- DNS采用层次树状结构的命名方法
- Internet根被划为几百个顶级域(top lever domains)
- 通用的(generic)
.com; .edu ; .gov ; .int ; .mil ; .net ;.org; .firm ; .hsop ; .web ; .arts ;.rec ;
- 国家的(countries)
.cn ; .us ;.nl ; .jp
- 每个(子)域下面可划分为若干子域(subdomains)
- 树叶是主机
3.2 根的分布(中国一个都没有)

3.3 域名的管理
-
一个域管理其下的子域
.jp被划分为ac.jp co.jp
.cn被划分为edu.cn com.cn -
创建一个新的域,必须征得它所属域的同意
3.4 域与物理网络无关
- 域遵从组织界限,而不是物理网络
一个域的主机可以不在一个网络
一个网络的主机不一定在一个域 - 域的划分是逻辑的,而不是物理的
4.域名到实际IP的解析问题-名字服务器
用户上网所需的四大信息
- IP地址:你主机的ID
- 默认网关(Default Gateway):当你想要访问别的子网的资源,需要向那个地方走
- 名字服务器(Local name server;DNS):当你访问别人的域名实际上是访问这个域名所属的IP,这个映射关系谁处理
- 子网掩码:你所在子网的ID
4.1 一个名字服务器的问题
即全部的域名解析工作都交给一个名字服务器来完成,这样就会造成下面的问题,而解决问题我们会采用划分区域的方式,每个区域都有一个负责的名字服务器来解析域名
- 可靠性问题:单点故障
- 扩展性问题:通信容量
- 维护问题:远距离的集中式数据库
4.2 名字空间划分为若干区域:Zone

4.2.1 区域名字服务器维护资源记录
- 资源记录
作用:维护域名-IP地址(其它)的映射关系
位置:Name Server的分布式数据库中
- RR格式
- Domain_name:域名
- ttl:time to live:生存时间(权威,缓冲记录),即这个映射关系是一个权威记录则是无限大的值,若为一个缓冲记录则是一个有限值,缓冲是为了加快查询效率,而到时间删除是为了一致性
- Class类别:对于Internet,值为IN
- Value值:可以是数字,域名或ASCII串,域名对应的IP地址
- Type类别:资源记录的类型一见下节

4.2.2 RR中的Type字段

4.3 本地名字服务器(Local Name Server)
- 并不严格属于层次结构
- 每个工ISP(居民区的工SP、公司、大学)都有一个本地DNS服务器
也称为“默认名字服务器”
- 当一个主机发起一个DNS查询时,查询被送到其本地DNS服务器
起着代理的作用,将查询转发到层次结构中!!!
4.4 DNS大致工作过程
- 应用调用解析器(resolver)
- 解析器作为客户向Name Server发出查询报文(封装在UDP段中)
- Name Server返回响应报文(name/ip)

4.5 名字服务器(Name Server)
名字解析过程:
- 目标名字在Local Name Server中
- 情况1:查询的名字在该区域内部
- 情况2:缓存(cashing)
- 当与本地名字服务器不能解析名字时,联系根名字服务器顺着根-TLD一直找到权威名字服务器
4.6 解析的方法(查询工作流程)
- 三种类型DNS服务器
- 根服务器:由十三个世界各地的不同组织管理
- 顶级域(TLD)服务器:该服务器提供权威DNS服务器的IP地址
- 权威服务器:记录主机的名字映射为IP地址
- 本地服务器:缓存代理
解析即查询映射关系那么自然就有查询算法,这里简单提两种
4.6.1 递归查询

4.6.2 迭代查询

4.DNS协议、报文
DNS协议:查询和响应报文的报文格式相同


5.如何维护一个新增的域
- 在上级域的名字服务器中增加两条记录,指向这个新增的子域的域名和域名服务器的地址
- 在新增子域的名字服务器上运行名字服务器,负责本域的名字解析:名字->IP地址
例子:在com域中建立一个“Network Utopia”
到注册登记机构注册域名networkutopia.com
- 需要向该机构提供权威DNS服务器(基本的、和辅助的)的名字和IP地址
- 登记机构在com TLD服务器中插入两条RR记录:
(networkutopia.com,dns1 子域的名字.networkutopia.com,NS 子域的名字服务器的名字);(dns1.networkutopia.com 这个名字服务器对应的IP地址,212.212.212.1,A)
在networkutopia.com的权威服务器中确保有
- 用于Web服务器的www.networkuptopia.com的类型为A的记录
- 用于邮件服务器mailnetworkutopia.com的类型为MX的记录
六、P2P应用(下面讲的P2P都是非结构化的,结构化的可自行了解)
0.顺带一提:在P2P模式下文件上传需要的信息
-
文件本体
-
文件描述
文件的描述就比如一首歌有很多不同的版本,但名字都是一样的,这时就需要描述起作用了,查询的关键字就是与描述相匹配的
-
文件的哈希值
该文件唯一的ID标识
-
节点信息
每个节点即使服务器也是用户,那么自然就维护着自己拥有的文件和为拥有的文件,那么怎么提高查询效率呢,可以在维护一个十分小的
BitMap表,分段来用1或0表示某个文件有或没有
1.纯P2P架构
- 没有(或极少)一直运行的服务器
- 任意端系统都可以直接通信
- 利用peer的服务能力
- Peer节点间歇上网,每次IP地址都有可能变化
1.1 用处
- 文件分发(BitTorrent)
- 流媒体(KanKan)
- VoIP (Skype)
2.文件分发:C/S vs P2P

2.1 C/S模式
在C/S模式中用户的上载能力是可以忽略不计的,因为每个用户都只跟同一台服务器打交道,只需要下载。当你用户达不到服务器上载的带宽时,这时瓶颈时用户的数量,但只要用户(N)一多即
US/N这个公式中的N无限增大,那么服务器分给每个用户的服务上载带宽就十分捉襟见肘了,所以这个下载的速度将会出现断崖式的减慢

2.2 P2P模式

2.3 两者速率下限比较
可以很明显的看到C/S模式当用户数量很多的时候,他的最小下载时间呈线性增长,而P2P则会很稳定的逐步上涨并逐渐无限接近于一个值

3.P2P文件共享的两大问题及解决方法

两大问题:
- 如何定位资源
- 如何处理对等待方的加入与离开
3.1 P2P:集中式目录
从图中可以看出对于定位资源的问题,在初代P2P模型中是用一个集中式的服务器来存储这个文件目录,当用户节点上线时都要向服务器提交一份自己的IP以及这个IP具有那些资源,所以这些信息在服务器中都是最新的

3.1.1 集中式目录的缺点
- 单点故障
- 性能瓶颈
- 侵犯版权
文件传输是分散的,而定位内容则是高度集中的
3.2 完全分布式:Gnutella(查询泛洪)
- 全分布式:没有中心服务器
- 开放文件共享协议
- 许多Gnutella客户端实现了Gnutella协议:类似HTTP有许多的浏览器
3.2.1 如何构建
- 覆盖网络:图
- 如果×和Y之间有一个TCP连接,则二者之间存在一条边
- 所有活动的对等方和边就是覆盖网络
- 边并不是物理链路
- 给定一个对等方,通常所连接的节点少于10个
3.2.2 查询过程
根据泛洪的字面意思就是将想要查询的请求发送到可触及之内的所有节点(邻居),然后可触及到的节点又会向自身可触及到的节点继续发送查询请求,这样很快就能遍及全网,然后等待节点返回命中响应,这样就知道那些节点有所需的节点了,(当然肯定有结束查询请求的时候不能一直没完没了的请求啊!!)

3.2.3 新节点的加入
- 对等方X必须首先发现某些已经在覆盖网络中的其他对等方:使用可用对等方列表
自己维持一张对等方列表(经常开机的对等方的IP)联系维持列表的Gnutella站点
- X接着试图与该列表上的对等方建立TCP连接,直到与某个对等方Y建立莲接
- X向Y发送一个Ping报文,Y转发该Ping报文
- 所有收到Ping报文的对等方以Pong报文响应IP地址、共享文件的数量及总字节数
- X收到许多Pong报文,然后它能建立其他TCP连接
- 注意:退出某个节点时,会将退出的位置使用网络中的某个节点进行填充,依次来保持整个图的度
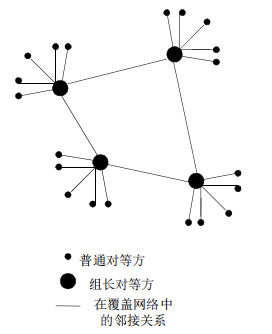
3.3 混合体:KaZaA(利用不匀称性)
- 每个对等方要么是一个组长,要么隶属于一个组长
对等方与其组长之间有TCP连接;组长对之间有TCP连接
- 组长跟踪其所有的孩子的内容
- 组长与其他组长联系
转发查询到其他组长;获得其他组长的数据拷贝
所以后下图可知当请求的资源在组内有无时:对于组内的节点时集中式的,对于组外的节点时分布式的
4.P2P下载分发过程:BitTorrent
对于十分稀缺的文件块会优先得到分发,同时对于优质的节点也会有资源传输时的优先级以及速率的提升,还就那个人人为我,我为人人!




七、视频流化服务和CDN
1.为什么需要CDN( 分布式的,应用层面的基础设施)
-
视频流量:占据着互联网大部分的带宽
-
规模性-如何服务者 ~1B 用户
单个超级服务器无法提供服务
-
异构性
不同的播放设备或是不同人对于清晰度的感知等等
2.多媒体: 视频
编码:使用图像内和图像间的冗余来降低编码的比特数
-
空间冗余(图像内)
空间编码例子:不是发送N个相同的颜色(全部是紫色)值,仅仅发送2各值:颜色(紫色)和重复的个数(N)
-
时间冗余(相邻的图像间)
时间编码例子:不是发送第i+1帧的全部编码,而仅仅发送和帧i差别的地方

3.多媒体流化服务
可以简单粗暴的理解为边下边播
3.1 DASH(Dynamic, Adaptive Streaming over HTTP)
3.1.1 对于服务器拿到一个视频文件的处理流程
- 将单个视频分成不同的清晰度版本
- 将视频文件(每个版本)分割成多个块
- 每个块独立存储,编码于不同码率(8-10种),即对应着不同的版本
- 告示文件
(man ifest file):提供存储不同块的URL(URL就是对应着不同块的位置信息)
3.1.2 对于客户端点开想看的视频的处理流程
- 先获取告示文件
- 周期性地测量服务器到客户端的带宽
- 查询告示文件,在一个时刻请求一个块,HTTP头部指定字节范围
如果带宽足够,选择最大码率的视频块
会话中的不同时刻,可以切换请求不同的编码块(取决于当时的可用带宽)
3.1.3 智能化的自适应客户端
- 什么时候去请求块(不至于缓存挨饿,或者溢出)
- 请求什么编码速率的视频块(当带宽够用时,请求高质量的视频块)
- 哪里去请求块(可以向离自己近的服务器发送URL,或者向高可用带宽的服务器请求)
3.2 遗留的问题
服务器如何通过网络向上百万用户同时流化视频内容 (上百万视频内容)?
- 单个的、大的超级服务中心“megaserver”,这个在日益分布式的思想出现后是绝对不会采用的
- 通过CDN,全网部署缓存节点,存储服务内容,就近为用户提供服务,提高用户体验
4.CDN(Content distribution networks:即内容加速服务)
CDN在互联网扮演的是一个提供代理缓冲的代理商即CDN运营商,通常ISP需要购买CDN的服务来实现用户的传输质量的提升,读者注意,DASH服务和CDN服务是能够同时进行的,不是一个东西的两种实现方式!!!
4.1 实现思路
- 全网部署
缓存节点,存储服务内容,就近为用户提供服务,提高用户体验 - 在CDN节点中存储内容的多个拷贝
- 用户从CDN中请求内容
- 重定向(这个重定向算法当然是运营商所实现提供的)到最近的拷贝,请求内容
- 如果网络路径拥塞,可能选择不同的拷贝
4.2 CDN节点部署策略
-
enter deep:将CDN服务器深入到许多接入网更接近用户,数量多,离用户近,管理困难,例如采用此策略的运营商:Akamai
-
bring home:部署在少数(10个左右)关键位置,如将服务器簇安装于POP附近(离若干1st lSP POP较近)采用租用线路将服务器簇连接起来,采用此策略的运营商:Limelight















 820
820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









