







文章目录
内存管理
1.页
- 概述
内核把物理页作为内存管理的基本单位。尽管处理器的最小可寻址单位通常为字(甚至字节),但是,内存管理单元(MMU,管理内存并把虚拟地址转换为物理地址的硬件)通常以页为单位进行处理。正因为如此,MMU以页(page)大小为单位来管理系统中的页表(这也是页表名的来由)。从虚拟内存的角度来看,页就是最小单位。
不同体系结构页的大小也不一样,支持的页种类也不一样,大多数32位体系支持4KB的页,64位支持8KB的页
- 页结构
- flags:该属性的每一位表示一种状态,什么页是不是脏的,是不是被锁定在内存之类的,所以能同时表示出32种不同的状态
- _count:存放页的引用计数,该页被引用了多少次,默认为-1,一般通过page_count函数返回得知(注意该函数返回0表示页空闲);一个页可以由页缓存使用(mapping属性指向关联的对象地址或者private属性指向)
- virtual:页在虚拟内存的地址
struct page {
unsigned long flags;
atomic_t _count ;
atomic_t _mapcount;
unsigned long private;
struct address_space *mapping;
pgoff_t index;
struct list_head lru;
void *virtual;
};
- 总结
内核用这一结构来管理系统中所有的页,因为内核需要知道一个页是否空闲(也就是页有没有被分配)。如果页已经被分配,内核还需要知道谁拥有这个页。拥有者可能是用户空间进程、动态分配的内核数据、静态内核代码或页高速缓存等。
2.区
- 概述
由于硬件的限制,内核并不能对所有的页一视同仁。有些页位于内存中特定的物理地址上,所以不能将其用于一些特定的任务。由于存在这种限制,所以内核把页划分为不同的区(zone)。内核使用区对具有相似特性的页进行分组。Linux必须处理如下两种由于硬件存在缺陷而引起的内存寻址问题:
- 一些硬件只能用某些特定的内存地址来执行DMA(直接内存访问)。
- 一些体系结构的内存的物理寻址范围比虚拟寻址范围大得多。这样,就有一些内存不能永久地映射到内核空间上。
- Linux中的四种区
ZONE_DMA——这个区包含的页能用来执行DMA操作。ZONE_DMA32——和ZOME_DMA类似,该区包含的页面可用来执行DMA操作;而和ZONE_DMA不同之处在于,这些页面只能被32位设备访问。在某些体系结构中,该区将比ZONE_DMA更大。ZONE_NORMAL——这个区包含的都是能正常映射的页。ZONE_HIGHEM一一这个区包含“高端内存”,其中的页并不能永久地映射到内核地址空间。
- 不同体系结构中页的实际使用和分布
例如在x86体系结构上,ISA设备就不能在整个32位9的地址空间中执行DMA,因为ISA 设备只能访问物理内存的前16MB。因此,ZONE_DMA在x86上包含的页都在0-16MB的内存范围里。

- 注意
Linux通过区的划分形成不同的内存池,这样就可以根据用途分配,注意这样的划分是逻辑意义上的划分;
某些特定的分配需要特定的区域,但某些一般用途的分配可以从两个不同的类型的任意一种分配区域(注意不能同时分配两种区的页,即存在区限界),主要目的就是节省DMA的区域页分配
- 区的结构表示
- lock:表示自旋锁,方式该结构被并发访问,但这个锁保护不了这个区的所有页,只单单保护这个结构
- watermark:该数组有本区的最小组、最低和最高水位值,水位被内核设置每个区的内存消耗基准,随空间大小的改变而改变
- name:表示该区的名字,分别为:
“DMA”、“Normal”和“HighMem”。
struct zone {
unsigned long watermark [NR_WMARK] ;
unsigned long lowmem_reserve [MAX_NR__ZONES] ;
struct per_cpu_pageset pageset [NR_CPUS] ;
spinlock_t lock;
struct free_area free_area [MAX_ORDER]
spinlock_t lru_lock ;
struct zone_lru {
struct list_head list;
unsigned longnr_saved_scan;
} lru [NR_LRU_LISTS] ;
struct zone_reclaim_stat reclain_stat;
unsigned long pages_scanned;
unsigned long flags;
atomic_long_t vmn_stat [NR_VM_ZONE_STAT_ITEMS];
int prev_priority;
unsigned int inactive_ratio;
wait_queue_head_t *wait_table;
unsigned long wait_table_hash_nr_entries;
unsigned long wait__table_bits;
struct pglist_data *zone_pgdat;
unsigned long zone_start _pfn;
unsigned long spanned pages;
unsigned long present_pages;
const char *name;
};
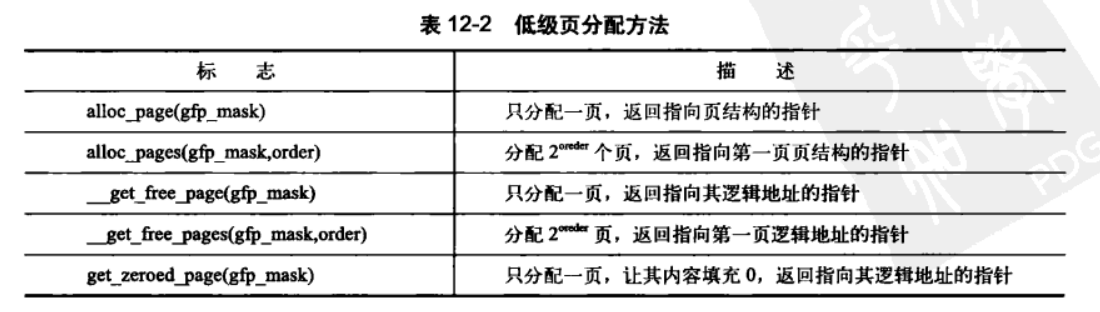
3.获取页
- 概述
获取页分配页最核心的函数为下面:该函数分配2order ( 1<<order)个连续的物理页,并返回一个指针,该指针指向第一个贝的page结构体﹔如果出错,就返回NULL。
//获取页
struct page * alloc_pages(gfp_t gfp_mask, unsigned int order)
//以用下面这个函数把给定的页转换成它的逻辑地址
void * page_address(struct page *page)
//下面函数直接返回所请求第一个页的逻辑地址
unsigned long _get_free_pages(gfp_t gfp_mask,unsigned int order)
- 相关获取页的函数总结
3.1 释放页
- 概述
我们直接看一个例子
unsigned long page;
page = __get_free pages (GFP_KERNEL,3);
if (!page) {
/*没有足够的内存:你必须处理这种错误!*/
return -ENOMEM ;
}
/*“page”现在指向8个连续页中第1个页的地址...*/
//在此,我们使用完这8个页之后释放它们:
free_pages(page,3) ;
/*
页现在已经被释放了,我们不应该再访问存放在“page”中的地址了
*/
4.kmalloc()
- 概述
kmalloc()函数与用户空间的malloc()一族函数非常类似,只不过它多了一个flags参数。kmalloc()函数是一个简单的接口,用它可以获得以字节为单位的一块内核内存。如果你需要整个页,那么,前面讨论的页分配接口可能是更好的选择。但是,对于大多数内核分配来说,kmalloc()接口用得更多。
- 函数
这个函数返回一个指向内存块的指针,其内存块至少要有
size大小。所分配的内存区在物理上是连续的。在出错时,它返回NULL。除非没有足够的内存可用,否则内核总能分配成功。在对kmalloc()调用之后,你必须检查返回的是不是NULL,如果是,要适当地处理错误
//第二个参数就是分配器标志
void * kmalloc(size_t size,gfp_t flags);
4.1 gfp_mask标志
- 概述
在前面几个例子中我们都发现了不同分配函数中,都用到了分配器标志,GFP_KERNEL就是一个分配器标志
- 分类
我们可以把该标志大致分为三类:
- 行为修饰符:内核应当如何分配所需的内存
- 区修饰符:表示内存区从哪分配内存
- 类型:该标志就是行为修饰符和区修饰符的不同组合,上面的GFP_KERNEL就是一个类型标志
行为修饰符:


- 例子
说明页分配器(最终调用alloc_pages())在分配时可以阻塞(睡眠)、执行IO,在必要时还可以执行文件系统操作。这就让内核有很大的自由度,以便它尽可能找到空闲的内存来满足分配请求。
ptr = kmalloc(size, _GFP_WAIT |_GFP_IO | _GFP_FS);
区修饰符:
内核优先从NORMAL开始分配,确保其他区有需要时有足够的空闲页可供使用

类型标识符
类型标志指定所需的行为和区描述符以完成特殊类型的处理。正因为这一点,内核代码趋向于使用正确的标志
-
类型标识符一览

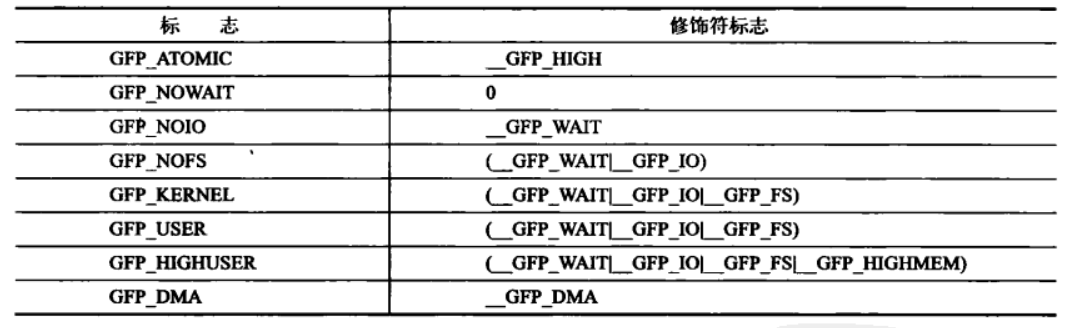
-
在每种类型标志后隐含的修饰符列表
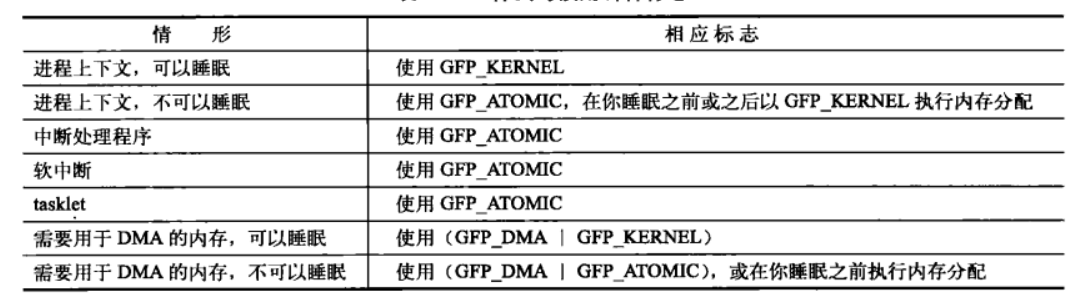
-
不同场景下使用什么类型
4.2 kfree()
- 概述
有分配就有释放,该函数就是对应kmalloc分配出来的内存块的释放工作,不能释放不是由kmalloc所分配的内存块,即需要注意配对使用
char *buf ;
buf = kmalloc (BUF_SIZE,GFP_ATOMIC) ;if ( ! buf)
/*内存分配出错!*/
//之后,当我们不再需要这个内存时,别忘了释放它:
kfree (buf) ;
5.vmalloc()
- 概述
vmalloc()函数的工作方式类似于kmalloc(),只不过前者分配的内存虚拟地址是连续的而物理地址则无须连续。这也是用户空间分配函数的工作方式:由malloc()返回的页在进程的虚拟地址空间内是连续的,但是,这并不保证它们在物理RAM中也是连续的。kmalloc()函数确保页在物理地址上是连续的(虚拟地址自然也是连续的)。
vmalloc()函数只确保页在虚拟地址空间内是连续的。它通过分配非连续的物理内存块,再“修正”页表,把内存映射到逻辑地址空间的连续区域中,就能做到这点。
尽管只有某些设备需要物理连续,但是内核还是一般都是会使用kmalloc,主要是为了提高性能,很明显物理上不连续我们就要建立物理和虚拟的表项,vmalloc需要一个一个建立映射,这会导致比直接内存分配大得多的TLB抖动(就是缓存切换频繁),所以在不得已是才会使用vmalloc,例如大内存的分配
- 物理连续和虚拟空间连续的不同需求
大多数情况下,只有硬件设备需要得到物理地址连续的内存。
- 在很多体系结构上,硬件设存在于内存管理单元以外,它根本不理解什么是虚拟地址。因此,硬件设备用到的任何内存区都必须是物理上连续的块,而不仅仅是虚拟地址连续上的块。
- 而仅供软件使用的内存块(例如与进程相关的缓冲区〉就可以使用只有虚拟地址连续的内存块。但在你的编程中,根本察觉不到这种
- 相关函数
两者对应使用
//函数会睡眠,不能在中断上下文使用,也不能在不允许阻止的情况下使用
void vmalloc(unsigned long size)
//同理也会睡眠
void vfree(const void *addr)
6.slab层
- 空闲链表
所谓空闲链表在很多的地方都出现过,为了就是应对频繁的分配和回收,链表中存放预先设置好的数据结构,需要就抓取一个,不用分配内存,不需要就回收而不是释放;所以你可以看作是一个缓存
- Linux中的空闲链表
在内核中,空闲链表面临的挑战就是不能全局控制,当可用内存紧缺时,内核无法通知每个链表,让其收缩缓存的大小来补充一些内存出来,所以Linux内核提供slab层(slab分配器),扮演着通用数据结构缓存层的角色
- slab需要满足的基本原则
- 频繁分配和释放的数据结构应当缓存
- 频繁分配和释放会造成内存碎片,随意空闲链表的缓存会连续存放防止缓存
- 回收的对象可以立即投入下一次分配,空闲链表提高性能
- 分配器知道对象大小、页大小和缓存的大小可以做出更明确的选择
- 如果部分缓存只属于某个单处理器则不需要加锁
- 若分配器是基于非统一内存访问(NUMA:在NUMA下,处理器访问它自己的本地存储器的速度比非本地存储器(存储器的地方到另一个处理器之间共享的处理器或存储器)快一些),可以从相同的内存节点进行分配
- 对存放在缓存中的对象进行标记,防止将多个对象映射到同一个缓存行中
6.1 slab层的设计
- 概述
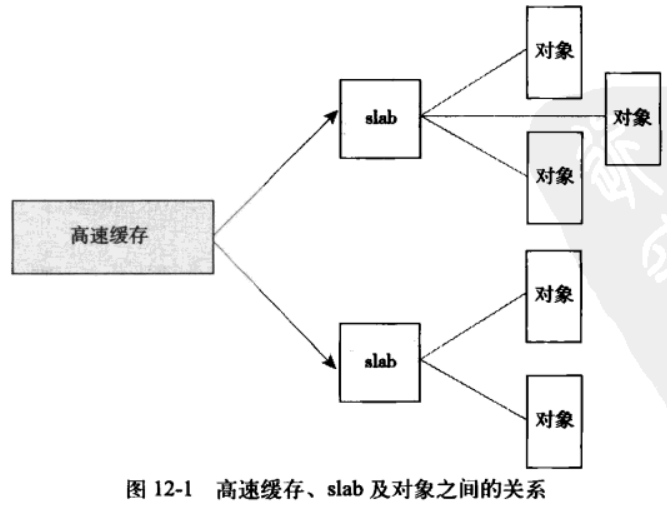
slab层把不同的对象划分为所谓高速缓存组,其中每个高速缓存组都存放不同类型的对象。每种对象类型对应一个高速缓存。例如,一个高速缓存用于存放进程描述符(task_struct结构的一个空闲链表),而另一个高速缓存存放索引节点对象(struct inode)。
- slab
每个缓存又被划分为多个slab,slab由一个或多个物理上连续的页组成(一般由一个页组成),每个slab都包含一些被缓存的数据结构等,有三种状态分别是:满、部分满或空,当内核分配时先从部分满开始寻找,如果没有则再去空的slab,如果没有创建空的则创建一个
- slab的结构
缓存由kmen_cache所表示,里面包含上面提到的三种链表满、部分满和空,链表包含缓存中的所有slab
struct slab {
struct list_head list; /*满、部分满或空链表*/
unsigned long co1ouroff ; /*slab着色的偏移量*/
void s_mem; /*在slab中的第一个对象*/
unsigned int inuse; /*slab中已分配的对象数*/
kmem_bufctl_t free; /*第一个空闲对象(如果有的话)*/
} ;
- 创建新的slab函数
通过get_free_pages()低级内核页分配器进行的:
static inline void * kmem_getpages(struct kmem_cache *cachep,gfp_t flags){
void *addr;
flags l= cachep->gfpflags;
addr = (void*) _get_free_pages(flags,cachep->gfporder) ;
return addr;
}
6.2 slab分配器的接口
- 概述
一个新的缓存由下面函数创建:
- 第一个参数是一个字符串,存放着高速缓存的名字﹔
- 第二个参数是高速缓存中每个元素的大小﹔
- 第三个参数是slab内第一个对象的偏移,它用来确保在页内进行特定的对齐。通常情况下,0就可以满足要求,也就是标准对齐。flags参数是可选的设置项,用来控制高速缓存的行为。它可以为0,表示没有特殊的行为,或者与以下标志中的一个或多个进行“或”运算:
两个函数都有可能被阻塞,所以不能在中断上下文中调用
//创建缓存
struct kmem_cache * kmem_cache_create (const char *name,
size_t size,
size_t align,
unsigned long flags,
void (*ctor)(void *) ) ;
//撤销缓存
int kmem_cache_destroy(struct kmem_cache *cachep)
从缓存中分配对象
一般在进程执行fork函数时,一定会创建一个新的进程描述符,这是在duptask_sturct()中完成的,而下面函数会被do_fork()调用:
//创建高速缓存之后,就可以通过下列函数获取对象:返回指向对象的指针
void * kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags)
//最后释放一个对象,并把它返回给原先的slab,可以使用下面这个函数:
void kmem_cache_free(struct kmem_cache *cachep,void *objp)
7.在栈上的静态分配
- 概述
在用户空间,我们以前所讨论到的那些分配的例子,有不少都可以在栈上发生。因为我们毕竟可以事先知道所分配空间的大小。用户空间能够奢侈地负担起非常大的栈,而且栈空间还可以动态增长,相反,内核却不能这么奢侈-—内核栈小而且固定。当给每个进程分配一个固定大小的小栈后,不但可以减少内存的消耗,而且内核也无须负担太重的栈管理任务。一般在32位和64位的页大小分别是4和8KB,所以栈的大小分别是8KB和16KB
7.1 单页内核栈
- 概述
在2.6版本早期,当激活单页内核栈时,每个进程的内核栈只有一页那么多,根据32位或64位会不同;这样做可以让进程减少内存的消耗;并且如果不这么做,随着时间的推移找到两个未分配且连续的页会越来越难,给进程分配虚拟内部的压力也在增大
并且还有个更复杂的原因,就是中断处理程序同样会使用被中断进程的内核栈,那么给这个可怜的内核栈会加上更多复杂的限制条件,为此后来中断处理程序就不放在进程的内核栈中了
- 中断栈
书接上文,内核更新了一个新功能:中断栈,中断栈为每个进程提供一个用于中断处理程序的栈,对每个进程也就多消耗一页而已,
7.2 在栈上光明长大的工作
- 概述
在任意一个函数中,我们都尽量节省资源,只需要在具体的函数让所有局部变量所占空间之和不要超过几百字节,如果在栈上进行大量静态分配,实则跟内核或用户空间分配内存一样了,所以我们要避免;因此进程动态分配也是很明智的一种选择
8.高端内存的映射
- 概述
所谓高端内存就是高于某个大小的物理内存不会永久的或自动的映射到内核空间去的这部分;例如在X86上,高于896MB的物理内存都为高端内存
永久映射
允许永久映射的数量是有限的,并且会被阻塞,所以只能在进程上下文
//映射
void *kmap(struct page *page)
//解除映射
void kunmap(struct page *page)
临时映射
当必须创建一个映射而当前的上下文又不能睡眠时,内核提供了临时映射(也就是所谓的原子映射)。有一组保留的映射,它们可以存放新创建的临时映射。内核可以原子地把高端内存中的一个页映射到某个保留的映射中。因此,临时映射可以用在不能睡眠的地方,比如中断处理程序中,因为获取映射时绝不会阻塞。
//建立映射
void *kmap_atomic(struct page *page,enum km_type type)
//解除映射
void kunmap_atomic(void *kvaddr,enum km_type type)
9.使用每个CPU数据的原因
- 每个CPU的分配
支持SMP的现代操作系统使用每个CPU上的数据,对于给定的处理器其数据是唯一的。般来说,每个CPU的数据存放在一个数组中。数组中的每一项对应着系统上一个存在的处理器。按当前处理器号确定这个数组的当前元素
看到代码并没有进行加锁,这时因为操作的数据对于当前的处理器是唯一的不存在并发问题;那么我们将视角转换到内核抢占上,由于触发内核抢占后,你的代码被其他处理器重新调度,但是CPU变量就会变得无效因为指向的处理器不对应了;如果是其他任务将你抢占,那么有可能就会发生同步问题了,但是可以看到下面的代码是禁止内核抢占的,之后再去激活
int cpu;
cpu = get_cpu ( ) ; /*获得当前处理器,并禁止内核抢占*/
my _percpu [cpu]++; /*...或者无论什么*/
printk ( "my_percpu on cpu=%d is %lu(n",cpu,my_percpu[cpu] ) ;
put_cpu ( ); /*激活内核抢占*/
使用每个CPU数据的原因如下
- 减少并发带来的性能消耗,减少数据锁定
- 使用每个CPU数据可以大大减少缓存失效(抖动)的现象:你就想象处理器处理某个数据,但是此数据又放在其他处理器缓存中,那你就要不停的更新自己的缓存了,命中率下降















 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









