







juc包下常见的工具类
前言
前面关于多线程的基础知识大概都学过了,锁、定时器啥的也都了解过了,今天就了解一下juc(java.util.concurrent.*)包下常见的工具类。
一、java.util.concurrent.atomic.*
java.util.concurrent.atomic.* 里面包含一系列的原子类,这些类的各种操作都是原子性的。
以 a++ 指令为例,其实可以分解为3个步骤:
- 从主存中读取a的值
- 对 a 进行 ++ 操作
- 把a重新放到主存
这三个步骤在单线程中一点问题都没有,但是到了多线程就出现了问题了。比如说有的线程已经把a进行了加1操作,但是还没来得及重新刷入到主存,其他的线程就重新读取了旧值。因为才造成了错误。如何去解决呢?方法当然很多,之前学了锁,我们可以运用锁机制来保证这个指令的原子性,但是今天学习一个新的方法,利用jcu工具包下的一个原子类 AtomicInteger 。
AtomicInteger类示例:
public class Main {
static int i = 0;
//此时,j已经是个对象了,叫做原子对象
static AtomicInteger j = new AtomicInteger(0);
public static void main(String[] args) {
// 不是原子的,想做到原子,就需要进行加锁操作
// 但加锁这个动作,其实成本是挺高的
i++;
i--;
// JVM 保证了这些操作是原子的,并且实现原子时,没有用到锁
// 整体来讲,性能能好些
// 内存其实通过 CAS + 多次尝试实现
// j = 0 CAS(j, 0, 1),成功了,原子操作成功;失败了,再次尝试 CAS(j, 1, 2)
j.getAndIncrement(); // 先取值,后加 1,视为是 j++
j.getAndDecrement(); // 先取值,后减 1,视为是 j--
j.incrementAndGet(); // ++j
j.getAndAdd(5); // d = j; j = j + 5
}
}
二、util.concurrent.locks.*
1、以接口形式出现的一系列标准
(1)Condition条件变量
包含 await() 和 signal() 方法,类似于与 synchronized 结合在一起使用的 wait() 和 notify() 方法,用于多线程之间的通信。
(2)Lock锁
(3)ReadWriteLock读写锁
这些之前都学过 ,就不再赘述了。
2、锁和条件变量的具体实现
这几个类里面都是具体的实现源码
3、实现锁的工具
(1)底层工具
(2)方便我们实现锁

4、信号量Semaphore
信号量 Semaphore 用来控制同时访问特定资源的线程数量,它跟锁(synchronized、Lock)有点相似,不同的地方是,锁同一时刻只允许一个线程访问某一资源,而 Semaphore 则可以控制同一时刻多个线程访问某一资源。可以简单理解为信号量 Semaphore 是可以被多个线程持有的锁。

public class Demo1 {
public static void main(String[] args) throws InterruptedException {
//允许五个线程请求该信号量
Semaphore semaphore=new Semaphore(5);
semaphore.acquire();
System.out.println("成功请求第一个信号量");
semaphore.acquire();
System.out.println("成功请求第二个信号量");
semaphore.acquire();
System.out.println("成功请求第三个信号量");
semaphore.acquire();
System.out.println("成功请求第四个信号量");
semaphore.acquire();
System.out.println("成功请求第五个信号量");
semaphore.acquire(); // 阻塞
System.out.println("成功请求第六个信号量");
}
}
先定义一个允许5个线程同时请求的信号量,那么当第六个线程去请求时就会阻塞,看看结果:
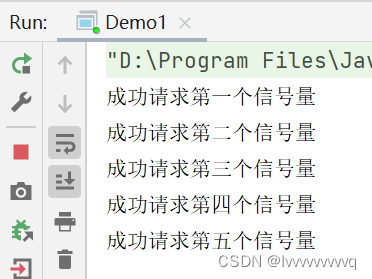
第六个并没有申请成功,程序阻塞。
需要注意的是:信号量的申请和释放不区分线程
- 一个线程可以请求多个信号量
- 只要有信号量的释放就有信号量的请求
- 没有申请过信号量的线程也可以释放信号量
看一段代码:
public class Demo2 {
//允许五个线程请求该信号量
private static Semaphore semaphore=new Semaphore(5);
//定义一个线程,让该线程释放一个信号量
static class MyThread extends Thread{
@Override
public void run() {
Scanner scanner = new Scanner(System.in);
scanner.nextLine();
semaphore.release(); // 释放一个信号量
}
}
public static void main(String[] args) throws InterruptedException {
MyThread t = new MyThread();
t.start();
semaphore.acquire();
System.out.println("成功请求第一个信号量");
semaphore.acquire();
System.out.println("成功请求第二个信号量");
semaphore.acquire();
System.out.println("成功请求第三个信号量");
semaphore.acquire();
System.out.println("成功请求第四个信号量");
semaphore.acquire();
System.out.println("成功请求第五个信号量");
semaphore.acquire();
System.out.println("成功请求第六个信号量");
}
}
跟上面的代码类似,我们先定义一个允许5个线程同时申请的信号量,然后在主线程中申请6个,在线程中释放 1 个,那么第 6 个申请就能成功,看看结果吧👇👇👇
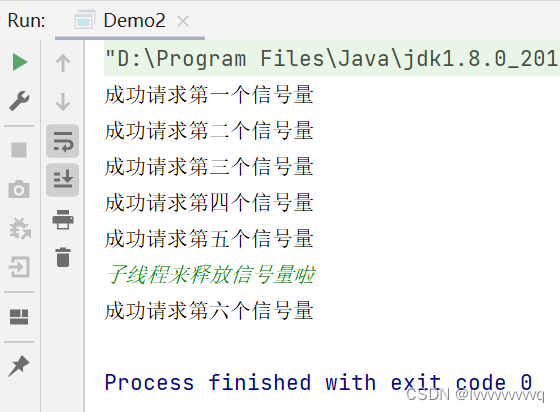
椰丝椰丝,第六次申请确实成功了,因为子线程释放了一个信号量(即使子线程没有申请过信号量,也不影响它对信号量的释放)
5、CountDownLatch
(1)什么是CountDownLatch
CountDownLatch 允许一个或者多个线程去等待其他线程完成操作。类似于 Thread.join() 方法,但比 join() 方法灵活。

(2)用法
public class Main {
// count: 计数器为 3 个,只有投 3 个金币,才能开始抓娃娃
static CountDownLatch countDownLatch = new CountDownLatch(3);
static class MyThread extends Thread {
@Override
public void run() {
countDownLatch.countDown();
countDownLatch.countDown();
countDownLatch.countDown();
}
}
public static void main(String[] args) throws InterruptedException {
MyThread t = new MyThread();
t.start();
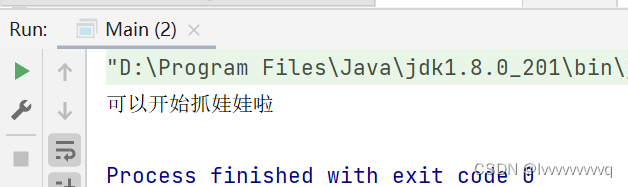
countDownLatch.await();
System.out.println("可以开始抓娃娃啦");
}
}
把 CountDownLatch 比作一个抓娃娃机器,规定投三个币才能开始抓,所以只有三个币都投了才能开始。
(3)CountDownLatch 和 join
两个功能相似,都是线程等待,但 CountDownLatch 比 join 灵活。
举个例子,线程A 在等待 线程T1 和 T2 ,但是 T1 和 T2 都要做大量的工作,耗时很长,而其中只要中间某一步完成后,其实就可以唤醒 线程A 继续执行,而不需要等待 线程T1 和 T2 所有任务执行完毕再执行主线程。
-
使用join(),线程A 必须等待 线程T1 和 T2 全部运行结束即使这两个线程会耗费大量时间。
-
使用CountDownLatch ,就可以更加细粒度的进行任务控制,没有必要等到 线程A和B 全部执行完。
6、Callable接口
Callable接口:发布任务,委托其他线程执行。
Callable接口也可以用来创建线程,跟Runnable创建线程类似,但有区别:
- Callable规定的方法是call(),Runnable规定的方法是run();
- Callable的任务执行后可以有返回值,而Runnable的任务不能有返回值;
- call方法可以抛出异常,run方法不可以;
- 运行Callable任务可以拿到一个Future对象,表示异步计算的结果。它提供了检查计算是否完成的方法,以等待计算的完成,并检索计算的结果。通过Future对象可以了解任务执行情况,可取消任务的执行,还可获取执行结果。
以计算斐波那契额数列为例:
public class Main {
static class FibCalc implements Callable<Long> {
private final int n;
FibCalc(int n) {
this.n = n;
}
private long fib(int n) {
if (n == 0 || n == 1) {
return 1;
}
return fib(n - 1) + fib(n - 2);
}
@Override
public Long call() throws Exception {
return fib(n);
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
//V1:使用线程池提交任务
ExecutorService service = Executors.newSingleThreadExecutor();
FibCalc task = new FibCalc(40);
//必须用 submit 提交任务
Future<Long> future = service.submit(task);
Long r = future.get(); // 这一步实际上是在等任务计算完成,所以,时间可能需要很久
System.out.println(r);
//V2:使用 FutureTask 类提交任务
// FutureTask task1=new FutureTask<>(new FibCalc(40));
// new Thread(task1).start();
// Long ret= (Long) task1.get();
// System.out.println(ret);
}
}
注意事项:
- 使用Callable接口创建线程,需要FutureTask实现类的支持,用于接收运算结果( FutureTask 是 RunnableFuture 接口的实现类,RunnableFuture 接口又继承 Runnable, Future 接口)。或者使用线程池提交任务。
- 如果使用线程池提交任务,则必须使用 submit 方式提交。
既然都到这儿了,那就再说一下线程池中execute 和 submit 的区别:
| execute | submit | |
|---|---|---|
| 提交任务的类型 | 只能提交Runnable类型的任务 | 既能提交Runnable类型任务也能提交Callable类型任务 |
| 对异常的处理 | 直接抛出任务执行时的异常,可以用try、catch来捕获,和普通线程的处理方式完全一致 | 吃掉异常,可通过Future的get方法将任务执行时的异常重新抛出 |
| 返回值 | execute()没有返回值 | submit有返回值,所以需要返回值的时候必须使用submit |
三、线程安全的一些数据结构
1、关于HashMap
HashMap 不是线程安全的,juc 包中提供了 ConcurrentHashMap ,属于线程安全版本的 HashMap。
之前提到过,在多线程环境中,如果多个线程之间存在共享数据,且至少有一个线程对该共享数据有写操作时,就会出现线程不安全现象。但是如果这些线程对该共享数据都是读操作时,就不用过多的考虑线程安全的问题。所以 HashMap 的 get() 操作是线程安全的,但 put() 操作一定不是线程安全的,所以在多线程环境中一定不要使用 HashMap。
2、HashMap 的 put() 过程
复习一下 HashMap 的 put() 过程吧:
- 使用 key ,获取 hash 值;
int h = key . hashCode() ; - 使用 hash 值,得到合法下标;
int index = h % array.length();
int index = h % (array.length()-1) 前提:array.length()一定是2的n次方; - 通过 index ,从数组中得到一条链表(可能是空链表),实际上实现中得到的是链表的头节点的引用(得到空链表时就是null);
- 遍历链表,利用循环+ equals(key) 操作确定 key 是否已经存在(前提:hash 设计的合理&&扩容的及时->足够均匀,链表长度<8);
- 如果 key 存在,就进行更新操作;如果不存在,就是添加操作(给链表添加一个节点);
- 如果发生了添加新节点,就要判断是否需要扩容;
因为HashMap在多线程环境下不是线程安全的,官方为了避免一些程序员在多线程环境下错误的使用HashMap,所以在put()操作向链表中插入新的key值时,使用了尾插的方式。因为在多线程环境下,头插可能会使链表成为一个环,链表的遍历就成了一个死循环,map.get()和map.put()操作永远不可能有返回值,CPU使用率100%,程序啥也干不了。
3、HashMap 如何保证线程安全
(1)锁机制
一把锁解决所有的线程不安全问题,但是性能不好。
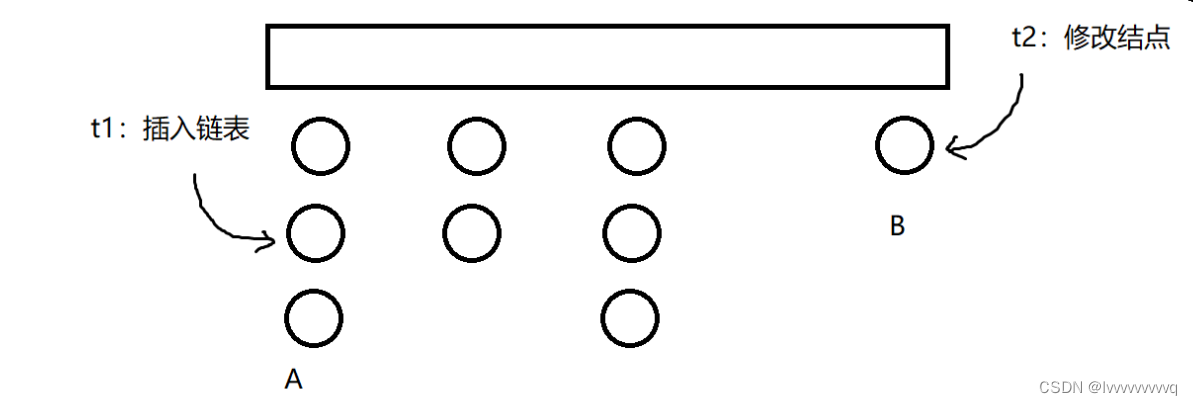
如图所示,t1 线程 和 t2线程 是对不同的链表进行操作的,所以完全没必要互斥,那么这种直接用锁的方法明显性能比较差了。
(2)使用ConcurrentHashMap
ConcurrentHashMap是juc包下的线程安全版本的 HashMap 。
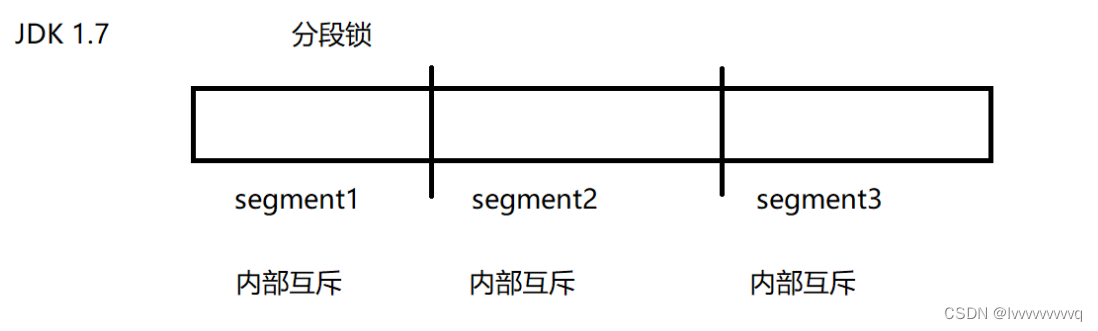
JDK1.7中,采用分段锁的方法保证线程安全。将 HashMap 分为n 段 segment,每段 segment 具有独立的同步锁,通过这种增加锁的方式,就相当于设置了 n 个并行处理的方法。
JDK1.8中,HashMap在JDK1.8版本中引入了红黑树的结构,在JDK1.8版本的ConcurrentHashMap中也引入了红黑树的结构。当冲突链表个数增大到 8 个时,就会将链表转化为红黑树结构,以提高查询效率。当红黑树节点个数小于 6 个时,就会将红黑树转化回链表的结构。为了保证线程安全,JDK1.8的ConcurrentHashMap中,只对某个链表做互斥,不是同一个链表,不需要做互斥。当前存在需要扩容的线程,该线程就创建一个新的扩后的空链表,然后搬移一个元素,剩下的线程也参与到元素搬移过程中,搬移最后一个元素的线程再负责删除旧的链表,这样的话也就意味着在扩容期间,新的链表和旧的链表是同时存在的,而且在搬移元素期间,别的线程也参与了进来,属于是众人拾柴火焰高,提高效率。
总结
就学了juc包下常见的工具类,有需要的时候要知道,有这些工具可以使用。重要的是HashMap的实现过程,还有CountDownLatch 和 join()的区别,以及 如何使用 Callable 创建线程。















 662
662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









