







1、Base_Line_V2_Nor
这是练习时常24307.5s的增加了归一化处理的加深一点点CNN练习生
2、条件预设
A、数据使用情况
1、完全使用labeled的数据集,没有采用unlabeled的数据集,数据量为train_set:3080,valid_set:660
2、 添加了Augment策略,增加图片的多样性
# It is important to do data augmentation in training.
train_tfm = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomChoice(
[transforms.AutoAugment(),
transforms.AutoAugment(transforms.AutoAugmentPolicy.CIFAR10),
transforms.AutoAugment(transforms.AutoAugmentPolicy.SVHN)]
),
# 随机水平翻转
transforms.RandomHorizontalFlip(p=0.5),
# 对图像执行随机仿射变换。
transforms.RandomAffine(degrees=20, translate=(0.2, 0.2), scale=(0.7, 1.3)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
# We don't need augmentations in testing and validation.
# All we need here is to resize the PIL image and transform it into Tensor.
test_tfm = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
B、模型架构
1、三个卷积层
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# The arguments for commonly used modules:
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
# input image size: [3, 128, 128]
self.cnn_layers = nn.Sequential(
# 3 * 224 * 224 -> 64 * 111 * 111
nn.Conv2d(3, 32, 3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 64, 3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
# 64 * 111 * 111 -> 128 * 54 * 54
nn.Conv2d(64, 128, 3),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
# 128 * 54 * 54 -> 256 * 26 * 26
nn.Conv2d(128, 256, 3),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
# 256 * 26 * 26 -> 256 * 12 * 12
nn.Conv2d(256, 256, 3),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
# 256 * 12 * 12 -> 512 * 5 * 5
nn.Conv2d(256, 512, 3),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
)
self.fc_layers = nn.Sequential(
nn.Linear(512 * 5 * 5, 512),
nn.ReLU(),
nn.BatchNorm1d(512),
nn.Dropout(0.5),
nn.Linear(512, 11),
)
def forward(self, x):
# input (x): [batch_size, 3, 128, 128]
# output: [batch_size, 11]
# Extract features by convolutional layers.
x = self.cnn_layers(x)
# The extracted feature map must be flatten before going to fully-connected layers.
x = x.flatten(1)
# The features are transformed by fully-connected layers to obtain the final logits.
x = self.fc_layers(x)
return x
C、训练参数设置
Batch_size_Data = 32
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0003, weight_decay=1e-5)
3、总结
1、第101轮
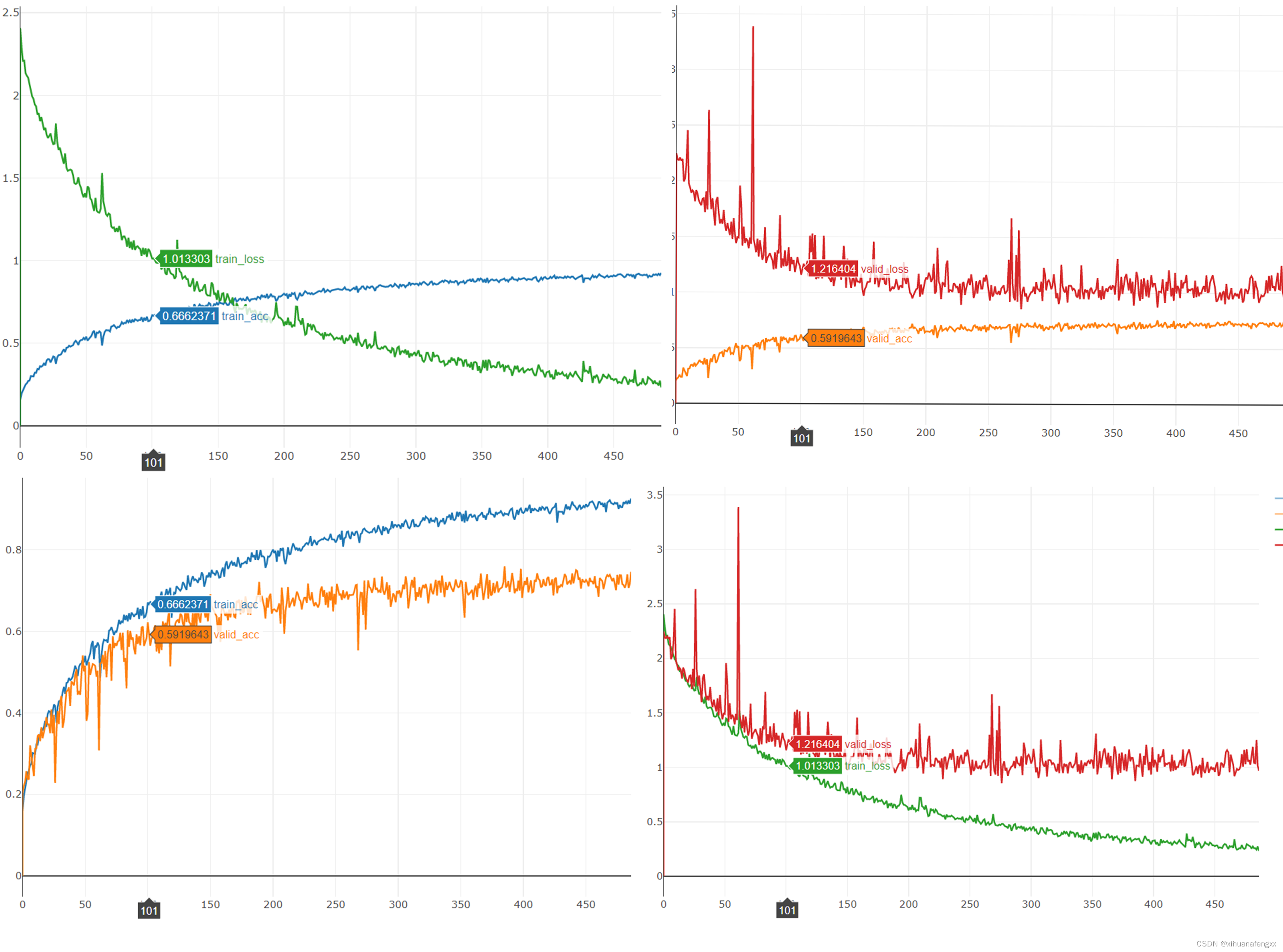

5060.8s 202 [ Train | 101/1000 ] loss = 1.01228, acc = 0.67043
5069.5s 203 [ Valid | 101/1000 ] loss = 1.15767, acc = 0.62173
模型训练正常,好像对数据进行归一化处理,也没有让这些训练的尖刺消失,暂时不知道是什么东西。
2、第190轮
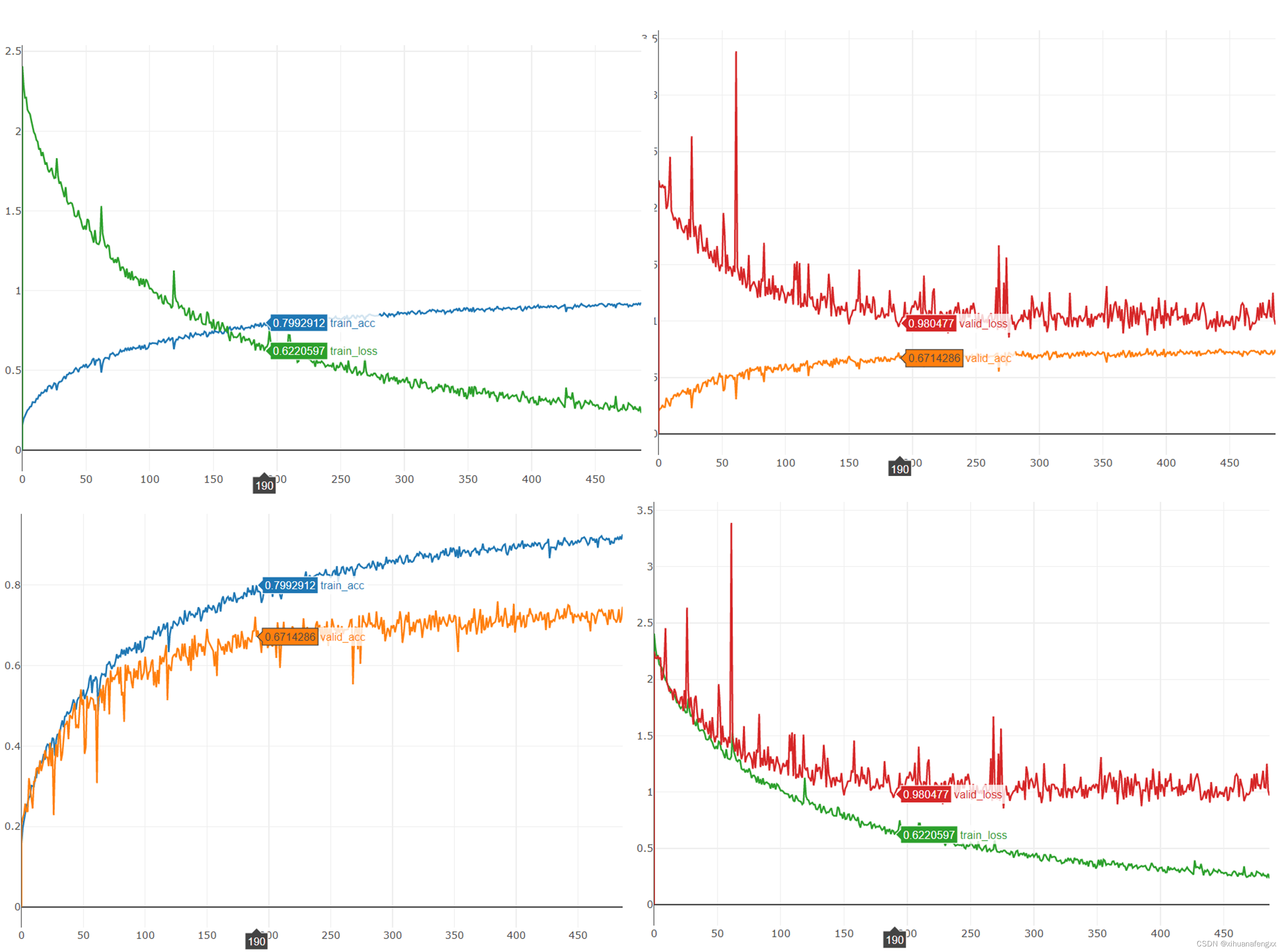

9493.2s 389 [ Train | 190/1000 ] loss = 0.65504, acc = 0.78157
9501.7s 390 [ Valid | 190/1000 ] loss = 0.94915, acc = 0.72083
感觉还行,效果相当于没有加的时候的第210多轮,加快了拟合速度
3、第307轮
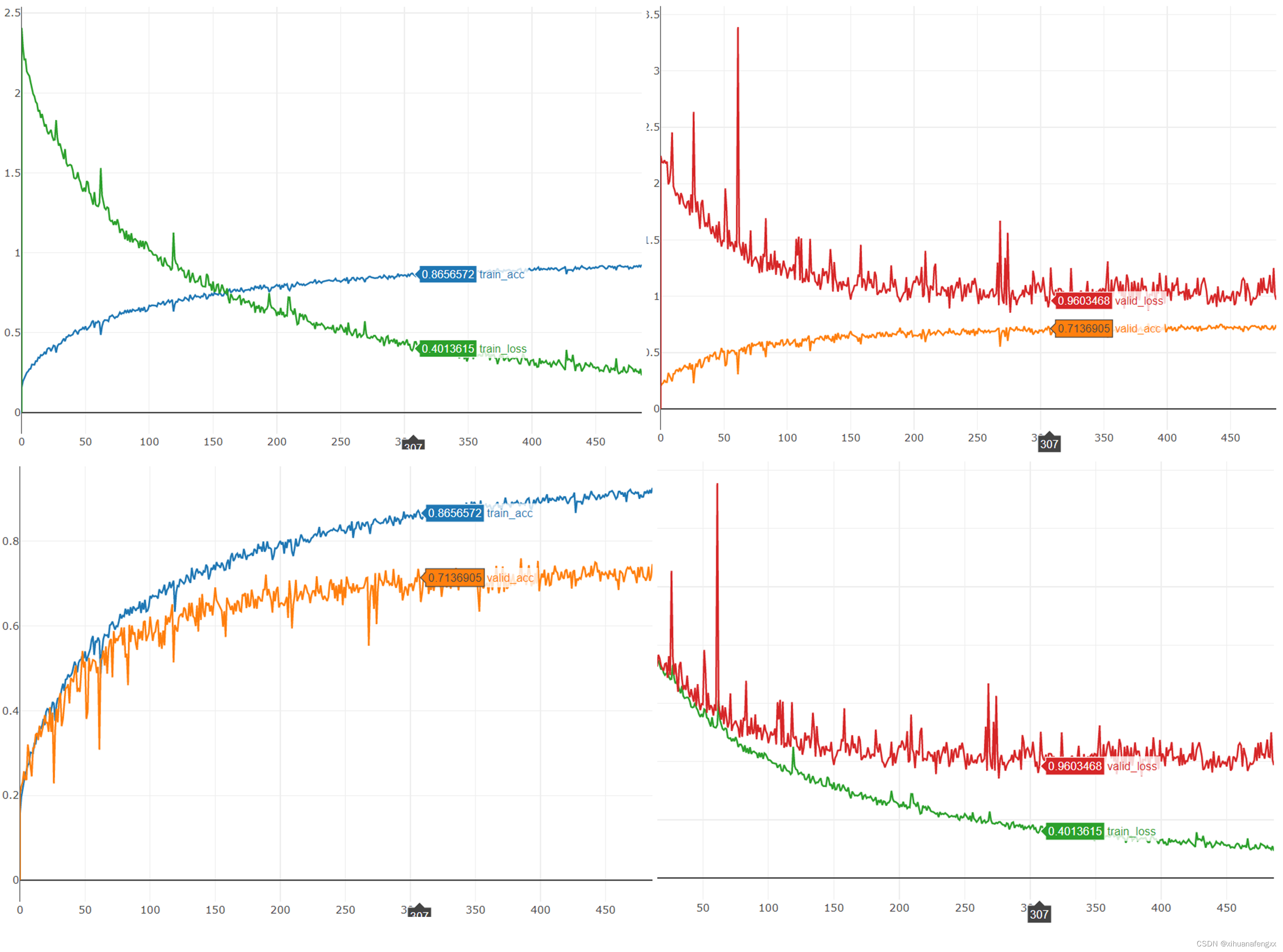

15292.4s 628 [ Train | 307/1000 ] loss = 0.38810, acc = 0.87178
15301.2s 629 [ Valid | 307/1000 ] loss = 0.90180, acc = 0.73452
到这里同样已经开始产生较为严重的过拟合了,但是还没有触发早停机制,效果和没加之前,有一点点轻微的提升
4、第386轮
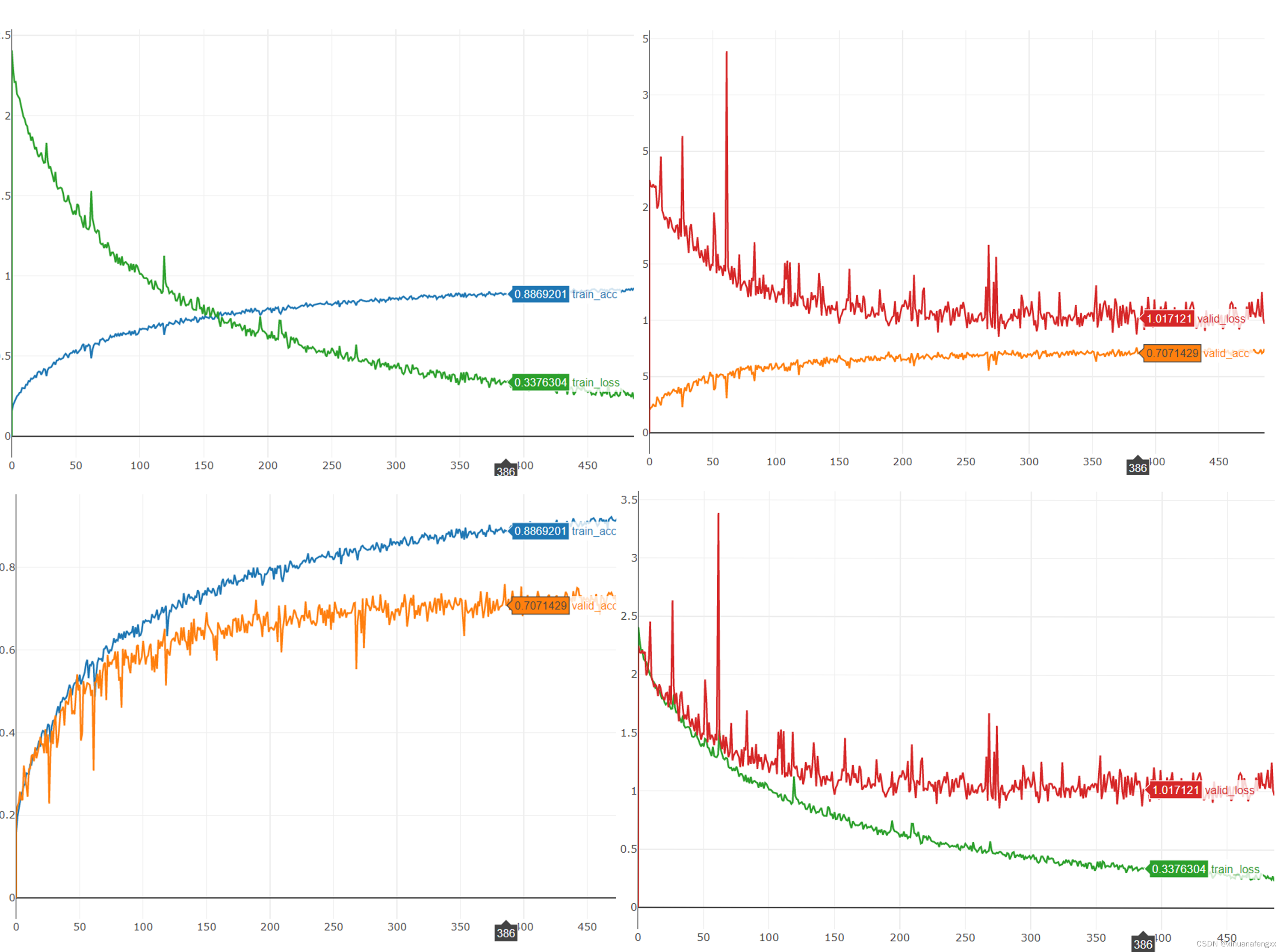

19218.7s 789 [ Train | 386/1000 ] loss = 0.34434, acc = 0.88918
19227.1s 790 [ Valid | 386/1000 ] loss = 0.87424, acc = 0.75923
最接近Strongbase line的一次,也是触发早停的最后一次记录,效果还不错,添加了对数据的正则化,确实带来了不错的提升,也确实加快了模型的收敛。可惜的是忘记保存最后一轮的模型了,整整多训练了100个epoch,尽管已经嘎嘎过拟合了,但是我还是挺期待那个效果的。呜呜呜!!!
24299.1s 992 [ Train | 487/1000 ] loss = 0.23309, acc = 0.92558
24307.5s 993 [ Valid | 487/1000 ] loss = 0.96833, acc = 0.74583
















 1438
1438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











