






目录
面试点:为啥重写equals方法的时候需要重写hashCode方法?用HashMap举个例子?
问题又来了,为什么计算扩容后容量要采用位移运算呢,怎么不直接乘以2呢?
treeifyBin(tab, hash) :转变红黑树存储
那是不是意味着Java8就可以把HashMap用在多线程中呢?
简介:
HashMap:作为Map的主要实现类;线程不安全的,效率高;存储null的key和value。
> Map中的key:无序的、不可重复的,使用Set存储所有的key --->key所在的类要重写equals()和hashCode()(以HashMap为例)
> Map中的value:无序的、可重复的,使用Collection存储所有的value --->value所在的类型要重写equals()
> 一个键值对:key-value构成了一个Entry对象。但是一个key一定对应一个value,一般拿着key找value.
> Map中的entry:无序的、不可重复的,使用Set存储所有的entry
子类:LinkedHashMap:保证在遍历map元素时,可以按照添加的顺序实现遍历。
原因:在原有的HashMap底层结构基础上,添加了一对指针,指向前一个和后一个元素。对于频繁的遍历操作,此类执行效率高于HashMap.
HashMap存储结构
JDK1.7:
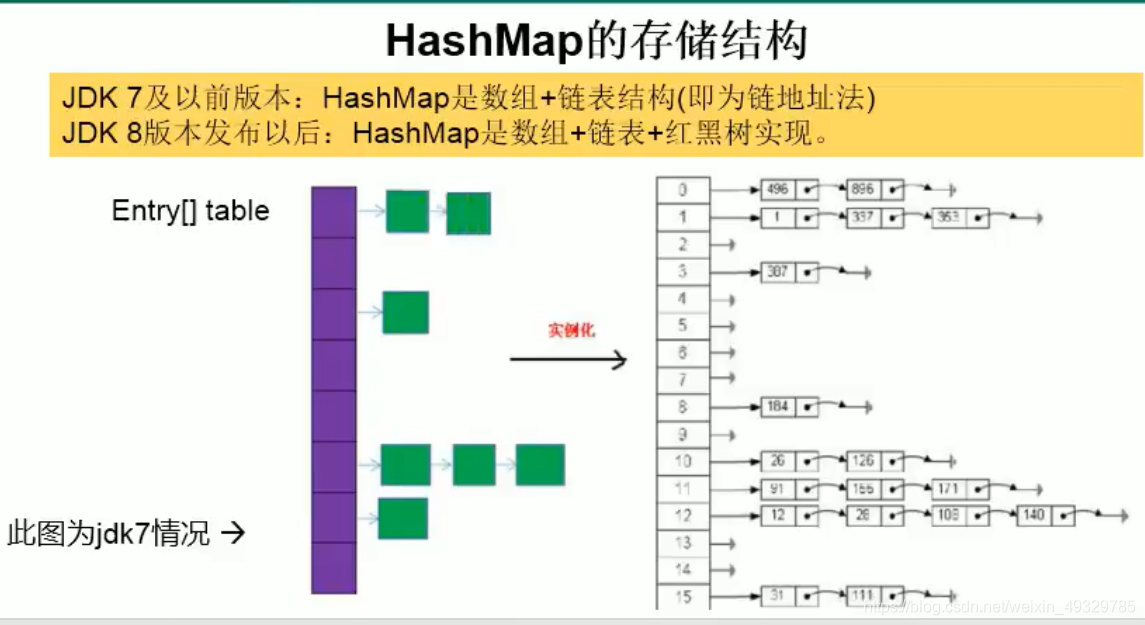

HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。
JDK1.8:
对于1.7版本的hashmap,Hash 冲突严重时,在桶上形成的链表会变的越来越长,这样在查询时的效率就会越来越低;时间复杂度为 O(N)。
而在jdk1.8中,HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值【8】且数组容量超过64时,将链表转换为红黑树,这样大大减少了查找时间。查询效率直接提高到了 O(logn)。
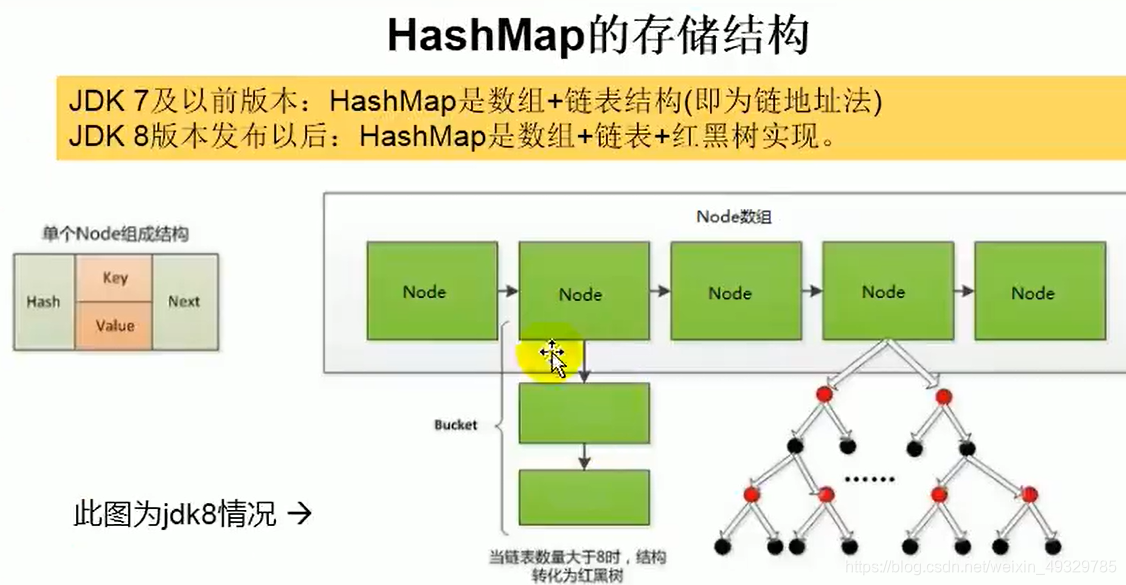
 jdk8相较于jdk7在底层实现方面的不同:
jdk8相较于jdk7在底层实现方面的不同:
1.new HashMap():底层没有创建一个长度为16的数组
2.jdk 8底层的数组是:Node[],而非Entry[]
3.首次调用put()方法时,底层创建长度为16的数组
4.jdk7底层结构只有:数组 + 链表。jdk8中底层结构:数组 + 链表 + 红黑树。
5. 形成链表时,七上八下(jdk7:新的元素指向旧的元素;jdk8:旧的元素指向新的元素)
当数组的某一个索引位置上的元素以链表形式存在的数据个数 > 8 且当前数组的长度 > 64时。
此时此索引位置上的所有数据改为使用红黑树存储。(重要优化:提高查找效率)
面试点:jdk8中HashMap为什么要引入红黑树?
其实主要就是为了解决jdk1.8以前hash冲突所导致的链化严重的问题,因为链表结构的查询效率是非常低的,他不像数组,能通过索引快速找到想要的值,链表只能挨个遍历,当hash冲突非常严重的时候,链表过长的情况下,就会严重影响查询性能,本身散列列表最理想的查询效率为O(1),当时链化后链化特别严重,他就会导致查询退化为O(n)为了解决这个问题所以jdk8中的HashMap添加了红黑树来解决这个问题,当链表长度超过阈值【8】且数组容量超过64时链表就会变成红黑树,红黑树其实就是一颗特殊的二叉排序树嘛,这个时间复杂度要比列表强很多,红黑树的引入巧妙的将原本O(n)的时间复杂度降低到了O(logn)。
若只是链表个数大于8而哈希表元素不超过64,此时只是简单的resize而已,并不会树化。
常用的变量
在 HashMap源码中,比较重要的常用变量,主要有以下这些。还有两个内部类来表示普通链表的节点和红黑树节点。普通链表中每一个节点都会保存自身的hash、key、value、以及下个节点。
//默认的初始化容量为16,必须是2的n次幂
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//HashMap最大容量为 2^30
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的加载因子0.75,乘以数组容量得到的值,用来表示元素个数达到多少时,需要扩容。
//为什么设置 0.75 这个值呢,简单来说就是时间和空间的权衡。
//若小于0.75如0.5,则数组长度达到一半大小就需要扩容,空间使用率大大降低,
//若大于0.75如0.8,则会增大hash冲突的概率,影响查询效率。
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//刚才提到了当链表长度过长时,会有一个阈值,超过这个阈值8就会转化为红黑树
static final int TREEIFY_THRESHOLD = 8;
//当红黑树上的元素个数,减少到6个时,就退化为链表
static final int UNTREEIFY_THRESHOLD = 6;
//链表转化为红黑树,除了有阈值的限制,还有另外一个限制,需要数组容量至少达到64,才会树化。
//这是为了避免,数组扩容和树化阈值之间的冲突。
static final int MIN_TREEIFY_CAPACITY = 64;
//存放所有Node节点的数组
transient Node<K,V>[] table;
//存放所有的键值对
transient Set<Map.Entry<K,V>> entrySet;
//map中的实际键值对个数,即数组中元素个数
transient int size;
//每次结构改变时,都会自增,fail-fast机制,这是一种错误检测机制。
//当迭代集合的时候,如果结构发生改变,则会发生 fail-fast,抛出异常。
transient int modCount;
//数组扩容阈值;当实际大小(容量*填充比)超过临界值时,会进行扩容
int threshold;
//加载因子
final float loadFactor;
//普通单向链表节点类
static class Node<K,V> implements Map.Entry<K,V> {
//hash存放的是当前key的hashcode,put和get的时候都需要用到它来确定元素在数组中的位置
final int hash;
final K key;
V value;
//指向单链表的下一个节点
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
//转化为红黑树的节点类
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
//当前节点的父节点
TreeNode<K,V> parent;
//左孩子节点
TreeNode<K,V> left;
//右孩子节点
TreeNode<K,V> right;
//指向前一个节点
TreeNode<K,V> prev; // needed to unlink next upon deletion
//当前节点是红色或者黑色的标识
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
} 面试点:为什么HashMap的默认初始化长度是16?
在JDK1.8的 236 行有1<<4就是16,为啥用位运算呢?直接写16不好么?
 在创建HashMap的时候,阿里巴巴规范插件会提醒我们最好赋初值,而且最好是2的幂。
在创建HashMap的时候,阿里巴巴规范插件会提醒我们最好赋初值,而且最好是2的幂。

这样是为了位运算的方便,位与运算比算数计算的效率高了很多,之所以选择16,是为了服务将Key映射到index的算法。
所有的key我们都会拿到他的hash,但是为了得到一个均匀分布的hash;通过Key的HashCode值去做位运算。
例如:key的某个元素的十进制为766132那二进制就是 10111011000010110100
index的计算公式:int index =key.hashCode()&(length-1);
15的的二进制是1111,那10111011000010110100 &1111 十进制就是4;这样也能保证计算后的index既可以是奇数也可以是偶数,并且只要传进来的key足够分散,均匀那么按位于的时候获得的index就会减少重复,这样也就减少了hash的碰撞以及hashMap的查询效率。
那为啥用16不用别的呢?
因为在使用不是2的幂的数字的时候,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。这是为了实现均匀分布。
那么到了这里你也许会问? 那么就然16可以,是不是只要是2的整数次幂就可以呢?
答案是肯定的。那为什么不是8,4呢? 因为是8或者4的话很容易导致map扩容影响性能,如果分配的太大的话又会浪费资源,所以就使用16作为初始大小。
面试题:负载因子的大小,对HashMap有什么影响?
>> 负载因子的大小决定了HashMap的数据密度。
>> 负载因子越大密度越大,发生碰撞的几率越高,数组中的链表越容易长,造成查询或插入时的比较次数增多,性能会下降。
>> 负载因子越小,就越容易触发扩容,数据密度也越小,意味着发生碰撞的几率越小,数组中的链表也就越短,查询和插入时比较的次数也越小,性能会更高。但是会浪费一定的内容空间。而且经常扩容也会影响性能,建议初始化预设大一点的空间。
>> 按照其他语言的参考及研究经验,会考虑将负载因子设置为07~0.75,此时平均检索长度接近于常数。
看源码大致的意思是0.75的时候,空间利用率比较高,而且避免了相当多的Hash冲突,使得底层的链表或者是红黑树的高度比较低,提升了空间效率。
modCount的注意点:
用于记录HashMap的修改次数, 在HashMap的put(),remove(),Interator()等方法中,使用了该属性
由于HashMap不是线程安全的,所以在迭代的时候,会将modCount赋值到迭代器的expectedModCount属性中,然后进行迭代, 如果在迭代的过程中HashMap被其他线程修改了,modCount的数值就会发生变化, 这个时候expectedModCount和ModCount不相等, 迭代器就会抛出ConcurrentModificationException()异常
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if ((next = e.next) == null) {
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
current = e;
return e;
}HashMap构造函数
HashMap有四个构造函数可供使用:
//默认无参构造,指定一个默认的加载因子
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
//可指定容量的有参构造,但是需要注意当前指定的容量并不一定就是实际的容量,下面会说
public HashMap(int initialCapacity) {
//同样使用默认加载因子
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
//把指定的容量改为一个大于它的的最小的2次幂值,如传过来的容量是14,则返回16
//注意这里,按理说返回的值应该赋值给 capacity,即保证数组容量总是2的n次幂,为什么这里赋值给了 threshold 呢?
//先卖个关子,等到 resize 的时候再说
this.threshold = tableSizeFor(initialCapacity);
}
//可传入一个已有的map
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
//把传入的map里边的元素都加载到当前map
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
//put方法的具体实现,后边讲
putVal(hash(key), key, value, false, evict);
}
}
}
tableSizeFor()
上边的第三个构造函数中,调用了 tableSizeFor 方法
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
以传入参数为14 来举例,计算这个过程。
首先,14传进去之后先减1,n此时为13。然后是一系列的无符号右移运算。
//13的二进制
0000 0000 0000 0000 0000 0000 0000 1101
//无右移1位,高位补0
0000 0000 0000 0000 0000 0000 0000 0110
//然后把它和原来的13做或运算得到,此时的n值
0000 0000 0000 0000 0000 0000 0000 1111
//再以上边的值,右移2位
0000 0000 0000 0000 0000 0000 0000 0011
//然后和第一次或运算之后的 n 值再做或运算,此时得到的n值
0000 0000 0000 0000 0000 0000 0000 1111
...
//发现,再执行右移 4,8,16位,同样n的值不变
//当n小于0时,返回1,否则判断是否大于最大容量,是的话返回最大容量,否则返回 n+1
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
//很明显我们这里返回的是 n+1 的值,
0000 0000 0000 0000 0000 0000 0000 1111
+ 1
0000 0000 0000 0000 0000 0000 0001 0000
将它转为十进制,就是 2^4 = 16 。发现一个规律,以上的右移运算,最终会把最低位的值都转化为 1111 这样的结构,然后再加1,就是1 0000 这样的结构,它一定是 2的n次幂。因此,这个方法返回的就是大于当前传入值的最小(最接近当前值)的一个2的n次幂的值。
HashMap的最大容量保证为2^n,但是若传入一个不为2^n的初始化容量怎么办?
this.threshold = tableSizeFor(initialCapacity);面试点:put()方法
//put方法,会先调用一个hash()方法,得到当前key的一个hash值,
//用于确定当前key应该存放在数组的哪个下标位置
//这里的 hash方法,姑且先认为是key.hashCode(),其实不是的,下面会细讲
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//把hash值和当前的key,value传入进来
//这里onlyIfAbsent如果为true,表明不能修改已经存在的值,因此传入false
//evict只有在方法 afterNodeInsertion(boolean evict) { }用到,可以看到它是一个空实现,因此不用关注这个参数
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断table是否为空,如果空的话,会先调用resize扩容(resize中会判断是否进行初始化)
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//根据当前key的hash值找到它在数组中的下标,判断当前下标位置是否已经存在元素,
//若没有,则把key、value包装成Node节点,直接添加到此位置。
// i =(n - 1) & hash是计算下标位置的
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
//如果当前位置已经有元素了,分为三种情况。
Node<K,V> e; K k;
//1.当前位置元素的hash值等于传过来的hash,并且他们的key值也相等,
//则把p赋值给e,跳转到①处,后续需要做值的覆盖处理
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//2.如果当前是红黑树结构,则把它加入到红黑树
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//3.说明此位置已存在元素,并且是普通链表结构,则采用尾插法,把新节点加入到链表尾部
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//如果头结点的下一个节点为空,则插入新节点
p.next = newNode(hash, key, value, null);
//如果在插入的过程中,链表长度超过了8,则转化为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
//插入成功之后,跳出循环,跳转到①处
break;
}
//若在链表中找到了相同key的话,直接退出循环,跳转到①处
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//①
//说明发生了碰撞,e代表的是旧值,因此节点位置不变,但是需要替换为新值
if (e != null) { // existing mapping for key
V oldValue = e.value;
//用新值替换旧值,并返回旧值。
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//看方法名字即可知,这是在node被访问之后需要做的操作。其实此处是一个空实现,
//只有在 LinkedHashMap才会实现,用于实现根据访问先后顺序对元素进行排序,hashmap不提供排序功能
// Callbacks to allow LinkedHashMap post-actions
//void afterNodeAccess(Node<K,V> p) { }
afterNodeAccess(e);
return oldValue;
}
}
//fail-fast机制
++modCount;
//判断是否需要进行扩容
if (++size > threshold)
resize();
//同样的空实现
afterNodeInsertion(evict);
return null;
}
map.put(key1,value1):
首先,调用key1所在类的hashCode()计算key1哈希值,此哈希值经过某种算法计算以后,得到在Entry数组中的存放位置。
1. 如果此位置上的数据为空,此时的key1-value1添加成功。----情况1
2. 如果此位置上的数据不为空,(意味着此位置上存在一个或多个数据(以链表形式存在)),比较key1和已经存在的一个或多个数据的哈希值:
2.1 如果key1的哈希值与已经存在的数据的哈希值都不相同,此时key-value1添加成功。----情况2
2.2 如果key1的哈希值和已经存在的某一个数据(key-value2)的哈希值相同,继续比较:调用key1所在类的equals(key2)方法
2.2.1 如果equals()返回false:此时key1-value1添加成功。----情况3
2.2.2 如果equals()返回true:使用value1替换value2.(修改作用的体现)
补充:关于情况2和情况3:此时key1-value1和原来的数据以链表的方式存储。
面试点:hash()计算原理
前面 put 方法中说到,需要先把当前key进行哈希处理,我们看下这个方法是怎么实现的。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
先判断key是否为空,若为空则返回0。这也说明了hashMap是支持key传 null 的。若非空,则先计算key的hashCode值,赋值给h,然后把h右移16位,并与原来的h进行异或处理。为什么要这样做,这样做有什么好处呢?
hashCode()方法继承自父类Object,它返回的是一个 int 类型的数值,可以保证同一个应用单次执行的每次调用,返回结果都是相同的(说明可以在hashCode源码上找到),这就保证了hash的确定性。在此基础上,再进行某些固定的运算,肯定结果也是可以确定的。
随便运行一段程序,把它的 hashCode的二进制打印出来,如下:
public static void main(String[] args) {
Object o = new Object();
int hash = o.hashCode();
System.out.println(hash);
System.out.println(Integer.toBinaryString(hash));
}
//1836019240
//1101101011011110110111000101000然后,进行 (h = key.hashCode()) ^ (h >>> 16) 这一段运算。
//h原来的值
0110 1101 0110 1111 0110 1110 0010 1000
//无符号右移16位,其实相当于把低位16位舍去,只保留高16位
0000 0000 0000 0000 0110 1101 0110 1111
//然后高16位和原 h进行异或运算
0110 1101 0110 1111 0110 1110 0010 1000
^
0000 0000 0000 0000 0110 1101 0110 1111
=
0110 1101 0110 1111 0000 0011 0100 0111可以看到,其实相当于,把高16位值和当前h的低16位进行了混合,这样可以尽量保留高16位的特征(往往高16位是比较有价值的信息),从而降低哈希碰撞的概率。
注意:得到的下面的结果仍不是最终的索引,只是得到了一个比较均匀的hash后的整数
(h = key.hashCode()) ^ (h >>> 16)
为什么这样做,就可以降低哈希碰撞的概率呢?
需要结合 i = (n - 1) & hash 这一段运算来理解。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)//最终的索引在这
tab[i] = newNode(hash, key, value, null);(n-1) & hash 作用:
//②
//这是 put 方法中用来根据hash()值寻找在数组中的下标的逻辑,
//n为数组长度, hash为调用 hash()方法混合处理之后的hash值。
i = (n - 1) & hash给定某个数值,去找它在某个数组中的下标位置时,直接用模运算就可以了(假设数组值从0开始递增)。如,找 14 在数组长度为16的数组中的下标,即为 14 % 16,等于14 。 18的位置即为 18%16,等于2。
而②中,就是取模运算的位运算形式。以18%16为例
//18的二进制
0001 0010
//16 -1 即 15的二进制
0000 1111
//与运算之后的结果为
0000 0010
// 可以看到,上边的结果转化为十进制就是 2 。
//其实会发现一个规律,因为n是2的n次幂,因此它的二进制表现形式肯定是类似于
0001 0000
//这样的形式,只有一个位是1,其他位都是0。而它减 1 之后的形式就是类似于
0000 1111
//这样的形式,高位都是0,低位都是1,因此它和任意值进行与运算,结果值肯定在这个区间内
0000 0000 ~ 0000 1111
//也就是0到15之间,(以n为16为例)
//因此,这个运算就可以实现取模运算,而且位运算还有个好处,就是速度比较快。为什么高低位异或运算可以减少哈希碰撞
假如用 key 原来的hashCode值,直接和 (n-1) 进行与运算来求数组下标,而不进行高低位混合运算,会产生什么样的结果?
//例如有另外一个h2,和原来的 h相比较,高16位有很大的不同,但是低16位相似度很高,甚至相同的话。
//原h值
0110 1101 0110 1111 0110 1110 0010 1000
//另外一个h2值
0100 0101 1110 1011 0110 0110 0010 1000
// n -1 ,即 15 的二进制
0000 0000 0000 0000 0000 0000 0000 1111
//可以发现 h2 和 h 的高位不相同,但是低位相似度非常高。
//分别和 n -1 进行与运算时,得到的结果却是相同的。(此处n假设为16)
//因为 n-1 的高16位都是0,不管 h 的高 16 位是什么,与运算之后,都不影响最终结果,高位一定全是 0
//因此,哈希碰撞的概率就大大增加了,并且 h 的高16 位特征全都丢失了。进行高低16位混合运算,是可以的,这样可以保证尽量减少高区位的特征。那么,为什么选择用异或运算呢,用与、或、非运算不行吗?
这是有一定的道理的。看下面表格,就能明白了。

可以看到两个值进行与运算,结果会趋向于0;或运算,结果会趋向于1;而只有异或运算,0和1的比例可以达到1:1的平衡状态。
所以,异或运算之后,可以让结果的随机性更大,而随机性大了之后,哈希碰撞的概率当然就更小了。
以上,就是为什么要对一个hash值进行高低位混合,并且选择异或运算来混合的原因。
面试点:关于映射关系的key是否可以修改?
answer:不要修改!
映射关系存储到HashMap中会存储key的hash值,这样就不用在每次查找时重新计算每一个Entry或Node(TreeNode)的Hash值了,因此如果已经put到Map中的映射关系,再修改key的属性,而这个属性又参与了hashcode值的计算,那么会导致匹配不上。
面试点:为啥重写equals方法的时候需要重写hashCode方法?用HashMap举个例子?
因为在java中,所有的对象都是继承于Object类。Ojbect类中有两个方法equals、hashCode,这两个方法都是用来比较两个对象是否相等的。
在未重写equals方法时,是继承了object的equals方法,那里的equals是比较两个对象的内存地址,显然new的2个对象内存地址肯定不一样
对于值对象,==比较的是两个对象的值
对于引用对象,比较的是两个对象的地址
HashMap是通过key的hashCode去寻找index的,那index一样就形成链表了,也就是说”zx“和”xz“的index都可能是2,在一个链表上的。
get的时候,是根据key去hash然后计算出index,找到2,怎么找到具体的”zx“还是”xz“呢?
equals!如果对equals方法进行了重写,建议一定要对hashCode方法重写,以保证相同的对象返回相同的hash值,不同的对象返回不同的hash值。
不然一个链表的对象,哪知道要找的是哪个,要是hashCode都一样,就不符合逻辑了。
面试点:resize()方法详解
Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。建议能提前预估 HashMap 的大小最好,尽量的减少扩容带来的性能损耗。
在上边 put 方法中发现,调用resize()的场景有两个:
>> 当数组为空的时候,会调用 resize 方法,
>> 组容量是有限的,数据多次插入的,到达一定的数量就会进行扩容;也会调用 resize方法。
什么时候resize呢?
有两个因素:
- Capacity:HashMap当前长度。
- LoadFactor:负载因子,默认值0.75f。
怎么理解呢,就比如当前的容量大小为100,当存进第76个的时候,判断发现需要进行resize了,那就进行扩容,但是HashMap的扩容也不是简单的扩大点容量这么简单的。
扩容?它是怎么扩容的呢?
分为两步:
- 扩容:创建一个新的Entry空数组,长度是原数组的2倍。
- ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
为什么要重新Hash呢,直接复制过去不行么?
是因为长度扩大以后,Hash的规则也随之改变。
Hash的公式---> index = HashCode(Key) & (Length - 1)
原来长度(Length)是8你位运算出来的值是2 ,新的长度是16你位运算出来的值明显不一样了。
扩容前:

扩容后:

扩容的规则是这样的,因为table数组长度必须是2的次方数,扩容其实每次都是按照上一次tableSize位运算得到的就是做一次左移1位运算,假设当前tableSize是16的话16转为二进制再向左移一位就得到了32 即 16 << 1 == 32 即扩容后的容量,也就是说扩容后的容量是当前容量的两倍,但记住HashMap的扩容是采用当前容量向左位移一位(newtableSize = tableSize << 1),得到的扩容后容量,而不是当前容量x2
问题又来了,为什么计算扩容后容量要采用位移运算呢,怎么不直接乘以2呢?
这个问题就比较简单了,因为cpu毕竟它不支持乘法运算,所有的乘法运算它最终都是再指令层面转化为了加法实现的,这样效率很低,如果用位运算的话对cpu来说就非常的简洁高效。
final Node<K,V>[] resize() {
//旧数组
Node<K,V>[] oldTab = table;
//旧数组的容量
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//旧数组的扩容阈值,注意,这里取的是当前对象的threshold值,下边的第2种情况会用到。
int oldThr = threshold;
//初始化新数组的容量和阈值,分三种情况讨论。
int newCap, newThr = 0;
//1.当旧数组的容量大于0时,说明在这之前肯定调用过resize扩容过一次,才会导致旧容量不为0。
//需要注意的是,它返回的值是赋给了threshold,而不是capacity。
//在这之前,没有在任何地方看到过,给capacity赋初始值。
if (oldCap > 0) {
//容量达到了最大值
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//新数组的容量和阈值都扩大原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//2.到这里,说明oldCap <=0,并且oldThr(threshold) > 0,这就是map初始化的时候,第一次调用
resize的情况
//而oldThr的值等于threshold,此时的threshold是通过tableSizeFor方法得到的一个2的n次幂的值
(我们以16为例)。
//因此,需要把oldThr的值,也就是threshold,赋值给新数组的容量newCap,以保证数组的容量是2的n次
幂。
//得出结论,当map第一次put元素时,就会走到这个分支,把数组的容量设置为正确的值(2的n次幂)
//但是,此时 threshold 的值也是2的n次幂,这不对啊,它应该是数组的容量乘以加载因子才对。别
急,这个会在③处理。
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
//3.到这里,说明oldCap和oldThr都是小于等于0的。也说明map是通过默认无参构造来创建的,
//于是,数组的容量和阈值都取默认值就可以了,即 16 和 12。
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//③ 这里就是处理第2种情况,因为只有这种情况 newThr 才为0,
//因此计算 newThr(用 newCap即16 乘以加载因子 0.75,得到 12) ,并把它赋值给 threshold
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//赋予threshold正确的值,表示数组下次需要扩容的阈值(此时就把原来的16修正为12)。
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
//可以发现,在构造函数时,并没有创建数组,在第一次调用put方法,导致resize的时候,才会把
数组创建出来。这是为了延迟加载,提高效率。
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//如果原来的数组不为空,那么就需要把原来数组中的元素重新分配到新的数组中
//如果是第2种情况,由于是第一次调用resize,此时数组肯定是空的,因此也就不需要重新分配元素。
if (oldTab != null) {
//遍历旧数组
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//取到当前下标的第一个元素,如果存在,则分三种情况重新分配位置
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
//1.如果当前元素的下一个元素为空,则说明此处只有一个元素
//则直接用它的hash()值和新数组的容量取模就可以了,得到新的下标位置。
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//2.如果是红黑树结构,则拆分红黑树,必要时有可能退化为链表
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
//3.到这里说明,这是一个长度大于 1 的普通链表,则需要计算并
//判断当前位置的链表是否需要移动到新的位置
else { // preserve order
// loHead 和 loTail 分别代表链表旧位置的头尾节点
Node<K,V> loHead = null, loTail = null;
// hiHead 和 hiTail 分别代表链表移动到新位置的头尾节点
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
//如果当前元素的hash值和oldCap做与运算为0,则原位置不变
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
//否则,需要移动到新的位置
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//原位置不变的一条链表,数组下标不变
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//移动到新位置的一条链表,数组下标为原下标加上旧数组的容量
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}扩容后的新table数组,那老数组中的这个数据怎么迁移呢?
迁移其实就是挨个桶位推进迁移,就是一个桶位一个桶位的处理,主要还是看当前处理桶位的数据状态把,这里也是分了大概四种状态:
这四种的迁移规则都不太一样
(1)第一种就是数组下标下内容为空:
这种情况下就没什么可说的,不用做什么处理。
( 2)第二种情况就是数组下标下内容不为空,但它引用的node还没有链化:
当slot它不为空,但它引用的node还没有链化的时候,说明这个槽位它没有发生过hash冲突,直接迁移就好了,根据新表的tableSize计算出他在新表的位置,然后存放进去就好了。
( 3)第三种就是slot内储存了一个链化的node:
当node中next字段它不为空,说明槽位发生过hash冲突,这个时候需要把当前槽位中保存的这个链表拆分成两个链表,分别是高位链和低位链
(4)第四种就是该槽位储存了一个红黑树的根节点TreeNode对象:
这个就很复杂了!
treeifyBin(tab, hash) :转变红黑树存储
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//判断当前hashMap的长度,如果不足64,只进行resize(),扩容table
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
//如果达到64,那么将冲突的存储结构为红黑树
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}面试点:get()方法
public V get(Object key) {
Node<K,V> e;
//如果节点为空,则返回null,否则返回节点的value。说明,hashMap是支持value为null的。
//因此,就明白了,为什么hashMap支持Key和value都为null
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//首先要确保数组不能为空,然后取到当前hash值计算出来的下标位置的第一个元素
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//若hash值和key都相等,则说明要找的就是第一个元素,直接返回
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//如果不是的话,就遍历当前链表(或红黑树)
if ((e = first.next) != null) {
//如果是红黑树结构,则找到当前key所在的节点位置
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//如果是普通链表,则向后遍历查找,直到找到或者遍历到链表末尾为止。
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
//否则,说明没有找到,返回null
return null;
}面试点:新的Entry节点,是怎么插入链表的?
java7及之前是头插法,新来的值会取代原有的值,原有的值就顺推到链表中去。但是,在java8之后,都是用尾部插入了。
为啥改为尾部插入呢?
在java1.7时是这样的,举个例子,往一个容量大小为2的put两个值,负载因子是0.75,是不是在put第二个的时候就会进行resize?
2*0.75 = 1 所以插入第二个就要resize了。
现在要在容量为2的容器里面用不同线程插入A,B,C,假如在resize之前打个短点,那意味着数据都插入了但是还没resize;那扩容前可能是这样的。
可以看到链表的指向A->B->C
Tip:A的下一个指针是指向B的

因为resize的赋值方式,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置,在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
就可能出现下面的情况:B的下一个指针指向了A

一旦几个线程都调整完成,就可能出现环形链表

如果这个时候去取值,悲剧就出现了——Infinite Loop。
头插是JDK1.7的那1.8的尾插是怎么样的呢?
使用头插会改变链表的上的顺序,但是如果使用尾插,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
就是说原本是A->B,在扩容后那个链表还是A->B

Java7在多线程操作HashMap时可能引起死循环,原因是扩容转移后前后链表顺序倒置,在转移过程中修改了原来链表中节点的引用关系。
Java8在同样的前提下并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系。
那是不是意味着Java8就可以把HashMap用在多线程中呢?
我认为即使不会出现死循环,但是通过源码看到put/get方法都没有加同步锁,多线程情况最容易出现的就是:无法保证上一秒put的值,下一秒get的时候还是原值,所以线程安全还是无法保证。
HashMap的线程不安全主要体现在两个方面:
- 1.在JDK1.7中,当并发执行扩容操作时会造成环形链和数据丢失的情况。
- 2.在JDK1.8中,在并发执行put操作时会发生数据覆盖的情况。
https://blog.csdn.net/qq_35958391/article/details/125015642
面试点:哈希冲突
概念:
对于两个数据元素的关键字 和 (i != j),有 != ,但有:Hash( ) == Hash( ),即:不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
冲突避免:
冲突解决:
面试点:为什么HashMap链表会形成死循环
准确的讲应该是 JDK1.7 的 HashMap 链表会有死循环的可能,因为JDK1.7是采用的头插法,在多线程环境下有可能会使链表形成环状,从而导致死循环。JDK1.8做了改进,用的是尾插法,不会产生死循环。
那么,链表是怎么形成环状的呢?
从 put()方法开始,最终找到线程不安全的那个方法。这里省略中间不重要的过程,只把方法的跳转流程贴出来:
//添加元素方法 -> 添加新节点方法 -> 扩容方法 -> 把原数组元素重新分配到新数组中
put() --> addEntry() --> resize() --> transfer()问题就发生在 transfer 这个方法中。

假设,原数组容量只有2,其中一条链表上有两个元素 A,B,如下图

现在,有两个线程都执行 transfer 方法。每个线程都会在它们自己的工作内存生成一个newTable 的数组,用于存储变化后的链表,它们互不影响(这里互不影响,指的是两个新数组本身互不影响)。但是,需要注意的是,它们操作的数据却是同一份。
因为,真正的数组中的内容在堆中存储,它们指向的是同一份数据内容。就相当于,有两个不同的引用 X,Y,但是它们都指向同一个对象 Z。这里 X、Y就是两个线程不同的新数组,Z就是堆中的A,B 等元素对象。
假设线程一执行到了上图1中所指的代码①处,恰好 CPU 时间片到了,线程被挂起,不能继续执行了。 记住此时,线程一中记录的 e = A , e.next = B。
然后线程二正常执行,扩容后的数组长度为 4, 假设 A,B两个元素又碰撞到了同一个桶中。然后,通过几次 while 循环后,采用头插法,最终呈现的结构如下:

此时,线程一解挂,继续往下执行。注意,此时线程一,记录的还是 e = A,e.next = B,因为它还未感知到最新的变化。
主要关注图1中标注的①②③④处的变量变化:
/**
* next = e.next
* e.next = newTable[i]
* newTable[i] = e;
* e = next;
*/
//第一次循环,(伪代码)
e=A;next=B;
e.next=null //此时线程一的新数组刚初始化完成,还没有元素
newTab[i] = A->null //把A节点头插到新数组中
e=B; //下次循环的e值第一次循环结束后,线程一新数组的结构如下图:

然后,由于 e=B,不为空,进入第二次循环。
//第二次循环
e=B;next=A; //此时A,B的内容已经被线程二修改为 B->A->null,然后被线程一读到,所以B的下一个节点指向A
e.next=A->null // A->null 为第一次循环后线程一新数组的结构
newTab[i] = B->A->null //新节点B插入之后,线程一新数组的结构
e=A; //下次循环的 e 值第二次循环结束后,线程一新数组的结构如下图:

此时,由于 e=A,不为空,继续循环。
//第三次循环
e=A;next=null; // A节点后边已经没有节点了
e.next= B->A->null // B->A->null 为第二次循环后线程一新数组的结构
//我们把A插入后,抽象的表达为 A->B->A->null,但是,A只能是一个,不能分身啊
//因此实际上是 e(A).next指向发生了变化,A的 next 由指向 null 改为指向了 B,
//而 B 本身又指向A,因此A和B互相指向,成环
newTab[i] = A->B 且 B->A
e=next=null; //e此时为空,结束循环第三次循环结束后,看下图,A的指向由 null ,改为指向为 B,因此 A 和 B 之间成环。

这时,可能有疑问了,就算他们成环了,又怎样,跟死循环有什么关系?
看下get() 方法(最终调用getEntry方法)

可以看到查找元素时,只要e不为空,就会一直循环查找下去。若有某个元素 C 的 hash 值也落在了和 A,B元素同一个桶中,则会由于, A,B互相指向,e.next 永远不为空,就会形成死循环。
HashMap是线程不安全的,如何处理其在线程安全的场景?
在这样的场景,一般都会使用HashTable或者ConcurrentHashMap,但是因为前者的并发度的原因基本上没啥使用场景了,所以存在线程不安全的场景我们都使用的是ConcurrentHashMap。
HashTable的源码,很简单粗暴,直接在方法上锁,并发度很低,最多同时允许一个线程访问,ConcurrentHashMap就好很多了,1.7和1.8有较大的不同,不过并发度都比前者好太多了
面试点:Map和Set的关系
其实Set集合下的子类就是Map集合下的子类
HashSet就是HashMap;TreeSet就是TreeMap;LinkedHashSet就是LinkedHashMap。
之所以Set是不重复的,原因是因为Set中元素存储了Map的Key
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable { static final long serialVersionUID = -5024744406713321676L; private transient HashMap<E,Object> map; private static final Object PRESENT = new Object(); public HashSet() { map = new HashMap<>(); }
调用Set集合的add()方法实际上就是调用Map集合的put,将Set集合的元素放在key上,value都是同一个空的Object对象
public boolean add(E e) { return map.put(e, PRESENT)==null; }
private static final Object PRESENT = new Object();HashMap常见面试题:
HashMap的底层数据结构?
HashMap的存取原理?
Java7和Java8的区别?
为啥会线程不安全?
有什么线程安全的类代替么?
默认初始化大小是多少?为啥是这么多?为啥大小都是2的幂?
HashMap的扩容方式?负载因子是多少?为什是这么多?
HashMap的主要参数都有哪些?
HashMap是怎么处理hash碰撞的?
hash的计算规则?
谈谈对HashMap中put\get方法的认识?如果了解再谈谈HashMap的扩容机制?默认大小是多少?什么是负载因子(或填充比)?什么是吞吐临界值(或阈值、threshold)?














 75
75











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









