







特征降维算法的应用
特征降维指的是采用某种映射方法,将高维向量空间的数据点映射到低维的空间中。在原始的高维空间中,数据可能包含冗余信息及噪声信息,其在实际应用中会对模型识别造成误差,降低模型准确率;而通过特征降维可以减少冗余信息造成的误差,从而提高模型准确率。
特征降维算法
1. 主成分分析(PCA)
主成分分析(Principal Component Analysis,PCA), 是考察多个变量间相关性一种多元统计方法,研究如何通过少数几个主成分来揭示多个变量间的内部结构,即从原始变量中导出少数几个主成分,使它们尽可能多地保留原始变量的信息,且彼此间互不相关.通常数学上的处理就是将原来P个指标作线性组合,作为新的综合指标。
2. 线性判别分析(LDA)
LDA的全称是Linear Discriminant Analysis(线性判别分析),是一种监督学习。原理是将带上标签的数据(点),通过投影的方法,投影到维度更低的空间中,使得投影后的点,会形成按类别区分,一簇一簇的情况,相同类别的点,将会在投影后的空间中更接近。
3. t分布随机邻居嵌入(t-SNE)
t-SNE( TSNE )将数据点的相似性转换为概率。原始空间中的相似性表示为高斯联合概率(根据数据点之间的相似性转换为概率),嵌入空间中的相似性表示为 “学生” 的 t 分布。这允许 t-SNE 对局部结构特别敏感,并且有超过现有技术的一些其它优点。
代码实现
1. 数据准备与预处理
准备用于降维的数据集,并进行必要的数据预处理,本次实验选择的是IRIS数据集。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.manifold import TSNE
from sklearn.datasets import load_iris
X,y=load_iris().data,load_iris().target
scaler = StandardScaler()
X = scaler.fit_transform(X)
2. 特征降维算法的实现与应用
根据实验需求选择特征降维算法(如PCA、LDA、t-SNE等),并编写相应的算法代码进行实现和应用。
# 创建降维器对象
pca = PCA(n_components=2)
lda = LinearDiscriminantAnalysis(n_components=2)
tsne = TSNE(n_components=2)
# 进行降维操作
X_pca = pca.fit_transform(X)
X_lda = lda.fit_transform(X, y)
X_tsne = tsne.fit_transform(X)
3. 降维结果可视化与分析
使用可视化方法将降维后的数据表示在二维空间中,并进行分析和比较。
# 可视化PCA降维结果
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y)
plt.title("PCA")
plt.xlabel("Component 1")
plt.ylabel("Component 2")
plt.show()
# 可视化LDA降维结果
plt.scatter(X_lda[:, 0], X_lda[:, 1], c=y)
plt.title("LDA")
plt.xlabel("Component 1")
plt.ylabel("Component 2")
plt.show()
# 可视化t-SNE降维结果
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y)
plt.title("t-SNE")
plt.xlabel("Component 1")
plt.ylabel("Component 2")
plt.show()
实验结果
| PCA | LDA | t-SNE |
|---|---|---|
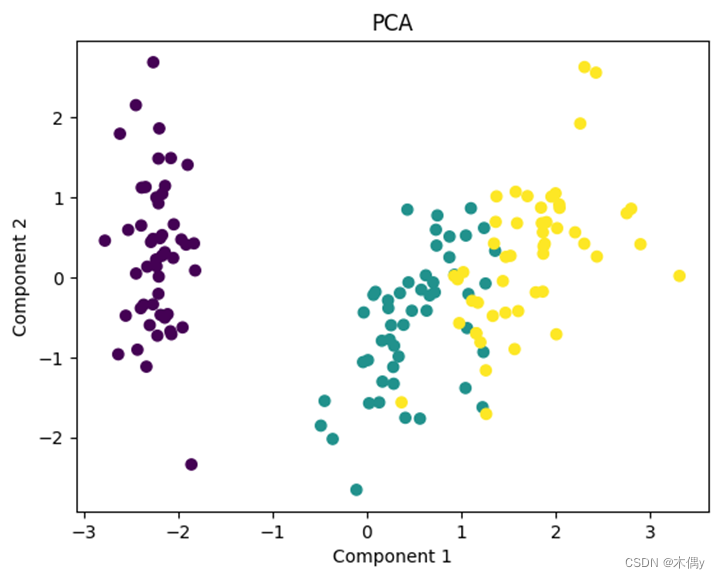 | 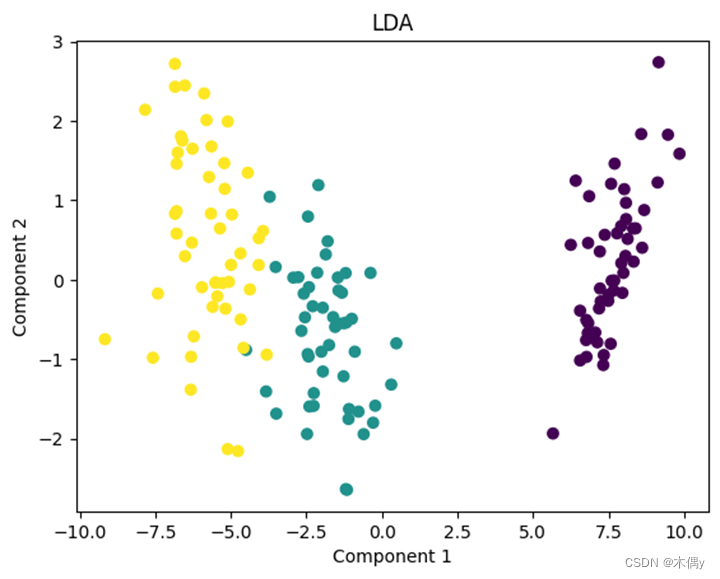 | 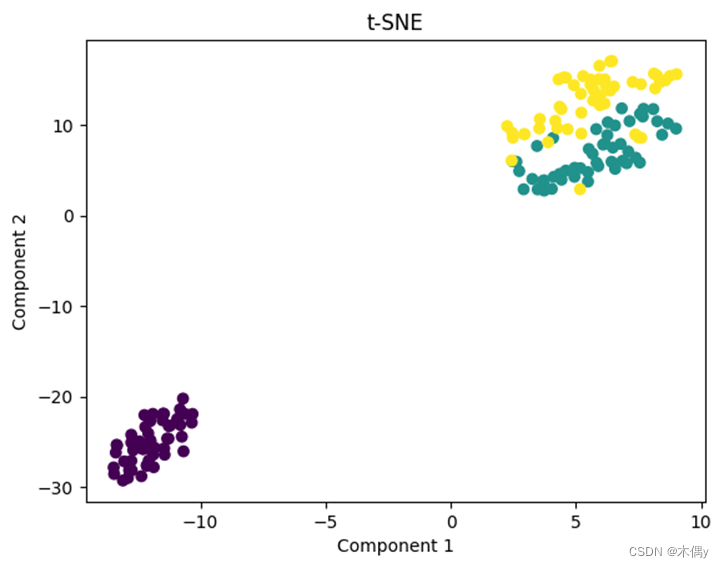 |
通过可视化降维结果,我们可以观察到数据在不同特征降维算法下的分布情况。根据降维后的数据表示,我们可以对数据集的结构和类别之间的关系有更深入的认识。
此外,可以根据实验需求和特征降维的目标,对不同的降维算法进行性能评估和比较。例如,可以计算降维后数据的方差解释比例(对于PCA),或者对分类任务进行评估。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









