







多个分类算法的综合应用
在上文中,我们使用了支持向量机实现了分类任务。本文将探讨其他一些经典的分类算法,如决策树、K近邻、朴素贝叶斯,并将这些方法与支持向量机一起进行比较。
分类算法介绍
1. 决策树
决策树(Decision Tree)是一种十分常用的分类方法,它是一种监督学习。其在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
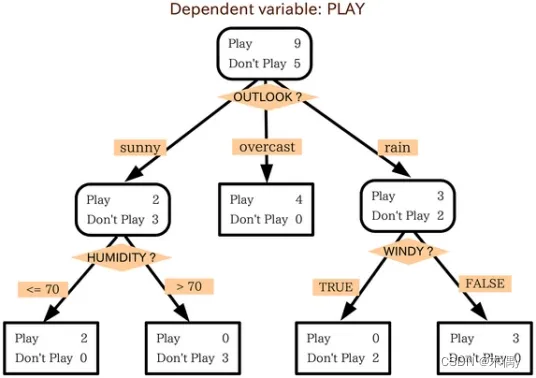
2. K近邻
K近邻(KNN)是一种基本分类与回归方法,属于有监督学习(带有标签)。分类问题中的K近邻,输入的是实例的特征向量(特征空间的点),输出的是实例的类别,可以取多类。它的原理很简单,就是服从多数原则。详细来说:给定一个数据集,其中的实例类别已定,在训练数据集中找到与目标实例最近的k各实例,这k个实例若大多数属于某个类别,就把目标实例归分为这个类别。
3. 朴素贝叶斯
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。
朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
4. 支持向量机
上文《SVM算法的应用》已详细介绍。
代码实现
1. 数据准备与预处理
准备用于训练和测试的数据集,并进行必要的数据预处理,如数据标准化等。
数据文件下载链接: https://pan.baidu.com/s/1X7m691FvnTVZpXfyUdCfiw?pwd=ukut 提取码: ukut
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
data = pd.read_csv("input\ex2data1.csv")
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
2. 多个分类算法的实现与训练
根据实验需求选择多个分类算法(如决策树、K近邻、朴素贝叶斯、支持向量机等),并编写相应的算法代码进行实现和训练。
由于本次算法较多,因此直接使用sklearn库中提供的方法。
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
clf_dt = DecisionTreeClassifier()
clf_knn = KNeighborsClassifier()
clf_nb = GaussianNB()
clf_svm = SVC()
# 使用训练数据进行训练
clf_dt.fit(X_train, y_train)
clf_knn.fit(X_train, y_train)
clf_nb.fit(X_train, y_train)
clf_svm.fit(X_train, y_train)
3. 模型预测与性能评估
使用训练好的模型对测试数据进行预测,并计算各个分类算法的性能评估指标,如准确度、召回率、精确度等。
from sklearn.metrics import accuracy_score, recall_score, precision_score
# 对测试数据进行预测
y_pred_dt = clf_dt.predict(X_test)
y_pred_knn = clf_knn.predict(X_test)
y_pred_nb = clf_nb.predict(X_test)
y_pred_svm = clf_svm.predict(X_test)
accuracy_dt = accuracy_score(y_test, y_pred_dt)
recall_dt = recall_score(y_test, y_pred_dt)
precision_dt = precision_score(y_test, y_pred_dt)
accuracy_knn = accuracy_score(y_test, y_pred_knn)
recall_knn = recall_score(y_test, y_pred_knn)
precision_knn = precision_score(y_test, y_pred_knn)
accuracy_nb = accuracy_score(y_test, y_pred_nb)
recall_nb = recall_score(y_test, y_pred_nb)
precision_nb = precision_score(y_test, y_pred_nb)
accuracy_svm = accuracy_score(y_test, y_pred_svm)
recall_svm = recall_score(y_test, y_pred_svm)
precision_svm = precision_score(y_test, y_pred_svm)
print("决策树:","\t\tAccuracy:",accuracy_dt,"\tRecall:",recall_dt,"\tPrecision:",precision_dt)
print("K近邻:","\t\tAccuracy:",accuracy_knn,"\tRecall:",recall_knn,"\tPrecision:",precision_knn)
print("朴素贝叶斯:","\tAccuracy:",accuracy_nb,"\tRecall:",recall_nb,"\tPrecision:",precision_nb)
print("支持向量机:","\tAccuracy:",accuracy_svm,"\tRecall:",recall_svm,"\tPrecision:",precision_svm)

试验结果分析
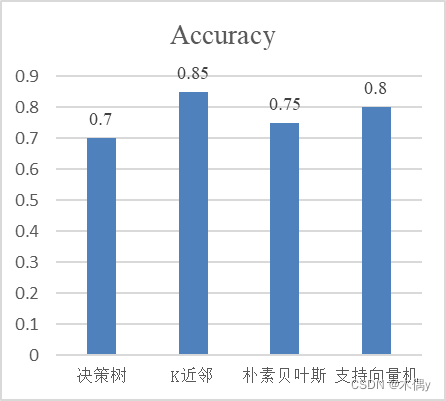
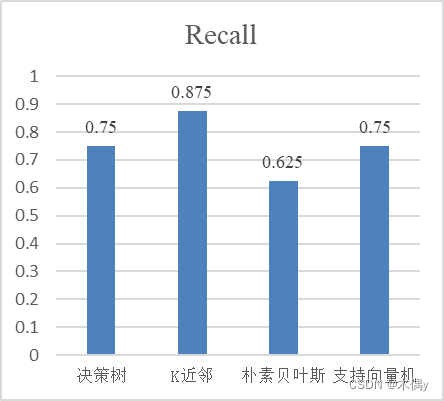
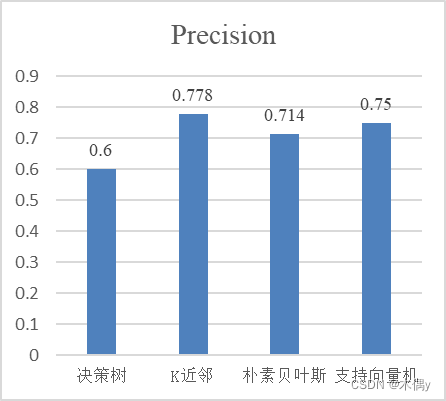
| 分类模型 | Accuracy | Recall | Precision |
|---|---|---|---|
| 决策树 | 0.7 | 0.75 | 0.6 |
| K近邻 | 0.85 | 0.875 | 0.778 |
| 朴素贝叶斯 | 0.75 | 0.625 | 0.714 |
| 支持向量机 | 0.8 | 0.75 | 0.75 |
 |  |  |
|---|
通过对比不同分类算法的性能评估指标,我们可以得出各个算法在给定数据集上的分类准确度、召回率和精确度。根据实验结果,我们可以分析出不同分类算法在特定数据集上的优劣势,并选择合适的算法用于实际应用。在本次实验的数据上,K近邻所取得的分类效果要好于其他三种方法,在三种评价指标上都有着更好的成绩。
个算法在给定数据集上的分类准确度、召回率和精确度。根据实验结果,我们可以分析出不同分类算法在特定数据集上的优劣势,并选择合适的算法用于实际应用。在本次实验的数据上,K近邻所取得的分类效果要好于其他三种方法,在三种评价指标上都有着更好的成绩。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









