






应用场景
该数据表用于接收各个项目组的数据信息,数据上传频率极高,数据量在一周内便达到十万加,
数据表sys_order简易结构如下:

由于数据量不断增加,项目数据库表数据量过大。需要使用shardingSphere根据groupId字段进行水平分表,每个项目组对应一张表,便于管理的同时减轻数据表压力。
实现步骤
引入Maven依赖
<!-- https://mvnrepository.com/artifact/org.apache.shardingsphere/sharding-jdbc-spring-boot-starter -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
配置yaml文件
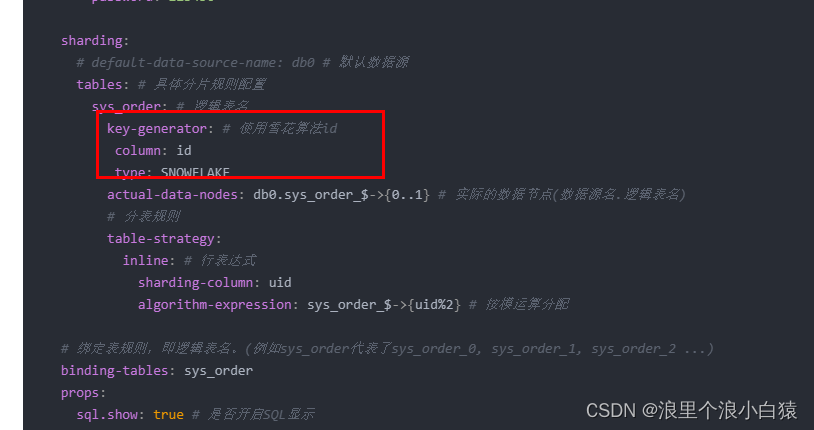
# 单库分表
spring:
shardingsphere:
datasource:
names: db0 # 指定数据源名字,多数据源以逗号分隔
db0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/sharding_test1?useUnicode=true&useSSL=false&characterEncoding=utf8&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
username: root
password: 123456
sharding:
# default-data-source-name: db0 # 默认数据源
tables: # 具体分片规则配置
sys_order: # 逻辑表名
key-generator: # 使用雪花算法id
column: id
type: SNOWFLAKE
actual-data-nodes: db0.sys_order_$->{0..1} # 实际的数据节点(数据源名.逻辑表名)
# 分表规则
table-strategy:
inline: # 行表达式
sharding-column: uid
algorithm-expression: sys_order_$->{uid%2} # 按模运算分配
# 绑定表规则,即逻辑表名。(例如sys_order代表了sys_order_0, sys_order_1, sys_order_2 ...)
binding-tables: sys_order
props:
sql.show: true # 是否开启SQL显示
### actual-data-nodes 读取数据分表策略
### table-strategy.inline 添加数据分表策略
### table-strategy.inline.sharding-column 添加数据分表字段(根据哪个字段插入数据到那个表,如:uid)
关键配置说明
sharing部分是我们分表需要使用的算法,一个是生成id使用的雪花算法,一个是分表使用的取模算法.
tables部分是对表的配置,分表是数据源使用,和分表策略使用。本次使用暂时不分库
后续测试
变化
1.数据源调整由dataSource替换成了shardingDataSource
2.健康检测异常,替换检测方式
@Configuration
public class DataSourceHealthConfig extends DataSourceHealthContributorAutoConfiguration {
@Value("${spring.datasource.dbcp2.validation-query:select 1}")
private String defaultQuery;
public DataSourceHealthConfig(Map<String, DataSource> dataSources, ObjectProvider<DataSourcePoolMetadataProvider> metadataProviders) {
super(dataSources, metadataProviders);
}
@Override
protected AbstractHealthIndicator createIndicator(DataSource source) {
DataSourceHealthIndicator indicator = (DataSourceHealthIndicator) super.createIndicator(source);
if (!StringUtils.hasText(indicator.getQuery())) {
indicator.setQuery(defaultQuery);
}
return indicator;
}
}
不足
1.无法自动建表
2.不支持部分SQL语句,引入需要对原来的数据库操作做一定检查调整
3.多字段IN查询无法通过sharing的SQL解析校验
总结:该中间件比较适用于数据操作简单而数据量大的数据库分表















 3634
3634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









